


ReLU stands for Rectified Linear Unit. It is a simple mathematical function widely used in neural networks. The ReLU regression has been widely studied over the past decade. It involves learning a ReLU activation function but is computationally challenging without additional assumptions about the input data distribution. Most studies focus on scenarios where input data follows a standard Gaussian distribution or other similar assumptions. Whether a ReLU neuron can be efficiently learned in scenarios where data may not fit the model perfectly remains unexplored.
The recent advancements in algorithmic learning theory focused on learning ReLU activation functions and biased linear models. Studies on teaching half-spaces with arbitrary bias achieved near-optimal error rates but struggled with regression tasks. Learning a ReLU neuron in the realizable setting was a special case of single index models (SIMs). While some works extended SIMs to the agnostic setting, challenges arose due to arbitrary bias. Gradient descent methods worked well for unbiased ReLUs but struggled when there was a negative bias. Most of these methods also depended on certain assumptions about the data distribution or prejudice. Some works have focused on whether a polynomial-time algorithm can learn such an arbitrary ReLU under Gaussian assumptions while achieving an approximately optimal loss (O(OPT)). Existing polynomial-time algorithms are limited to providing approximation guarantees for the more manageable unbiased setting or cases with restricted bias.
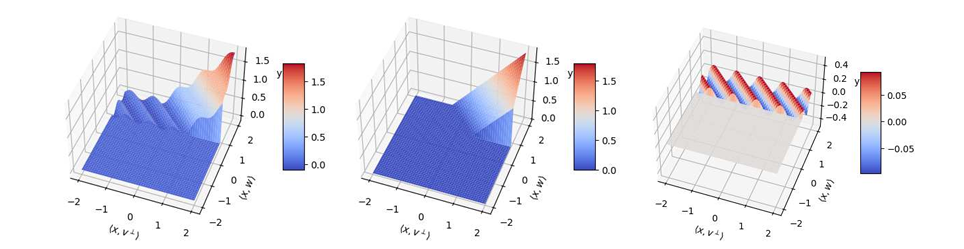
To solve this problem, researchers from Northwestern University proposed the SQ algorithm, which takes a different approach from existing gradient descent-based methods to achieve a constant factor approximation for arbitrary bias. The algorithm takes advantage of the Statistical Query framework to optimize a loss function based on ReLU by using a combination of grid search and thresholded PCA to estimate various parameters. The problem is normalized for simplicity, ensuring the parameter is a unit vector, and statistical queries are used to evaluate expectations over specific data regions. Grid search helps find approximate values for parameters, while thresholded PCA starts some calculations by dividing the data space and looking at contributions within defined areas. It has a noise-resistant algorithm that also handles changes in estimates and provides accurate initializations and parameter estimates with limited errors. This method optimizes the ReLU loss function efficiently by emphasizing the good characteristics of the SQ framework in dealing with noise and performance well in large-scale scenarios.
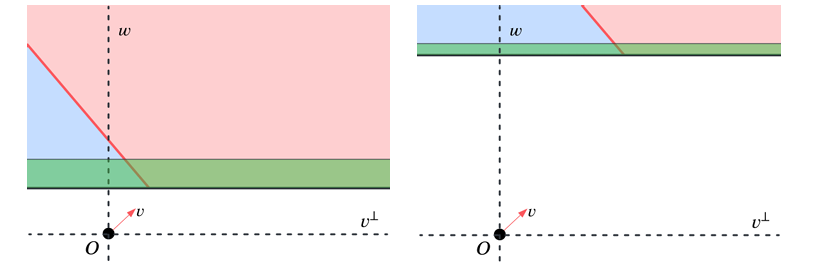
The researchers further explored the limitations of CSQ (Correlational Statistical Query) algorithms in learning ReLU neurons with certain loss functions, showing that for specific instances, any CSQ algorithm aiming to achieve low error rates would require either an exponential number of queries or queries with very low tolerance. This result was proven using a CSQ hardness approach involving key lemmas about high-dimensional spaces and the complexity of function classes. The CSQ dimension, which measures the complexity of function classes relative to a distribution, was introduced to establish lower bounds for query complexity.Â
In summary, the researchers addressed the problem of learning arbitrary ReLU activations under Gaussian marginals and provided a major upgrade in the field of machine learning. The method also showed that achieving even small errors in the learning process often required either an exponential number of queries or a high level of precision. Such results gave insight into the inherent difficulty of learning such functions in the context of the CSQ method. The proposed SQ algorithm offers a robust and efficient solution that overcomes the flaws of existing processes and gives a constant factor approximation for arbitrary bias. The technique showed the importance of the ReLU, and thus, this method can bring a huge change in the domain of Machine learning and training algorithms serving as a baseline for future researchers!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Understanding the Agnostic Learning Paradigm for Neural Activations appeared first on MarkTechPost.
Source: Read MoreÂ

