




Large language models (LLMs) have transformed AI applications, powering tasks like language translation, virtual assistants, and code generation. These models rely on resource-intensive infrastructure, particularly GPUs with high-bandwidth memory, to manage their computational demands. However, delivering high-quality service to numerous users simultaneously introduces significant challenges. Efficiently allocating these limited resources is critical to meet service level objectives (SLOs) for time-sensitive metrics, ensuring the system can cater to more users without compromising performance.
A persistent issue in LLM serving systems is achieving fair resource distribution while maintaining efficiency. Existing systems often prioritize throughput, neglecting fairness requirements such as balancing latency among users. Preemptive scheduling mechanisms, which dynamically adjust request priorities, address this. However, these mechanisms introduce context-switching overheads, such as GPU idleness and inefficient I/O utilization, which degrade key performance indicators like Time to First Token (TTFT) and Time Between Tokens (TBT). For instance, the stall time caused by preemption in high-stress scenarios can reach up to 59.9% of P99 latency, leading to a significant decline in user experience.
Current solutions, such as vLLM, rely on paging-based memory management to address GPU memory constraints by swapping data between GPU and CPU memory. While these approaches improve throughput, they face limitations. Issues such as fragmented memory allocation, low I/O bandwidth utilization, and redundant data transfers during multi-turn conversations persist, undermining their effectiveness. For example, vLLM’s fixed block size of 16 tokens results in suboptimal granularity, which reduces PCIe bandwidth efficiency and increases latency during preemptive context switching.
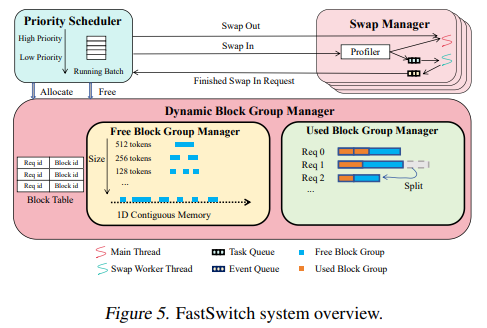
Researchers from Purdue University, Shanghai Qi Zhi Institute, and Tsinghua University developed FastSwitch, a fairness-aware LLM serving system that addresses inefficiencies in context switching. FastSwitch introduces three core optimizations: a dynamic block group manager, a multithreading swap manager, and a KV cache reuse mechanism. These innovations synergize to improve I/O utilization, reduce GPU idleness, and minimize redundant data transfers. The system’s design builds on vLLM but focuses on coarse-grained memory allocation and asynchronous operations to enhance resource management.
FastSwitch’s dynamic block group manager optimizes memory allocation by grouping contiguous blocks, increasing transfer granularity. This approach reduces latency by up to 3.11x compared to existing methods. The multithreading swap manager enhances token generation efficiency by enabling asynchronous swapping, mitigating GPU idle time. It incorporates fine-grained synchronization to avoid conflicts between ongoing and new requests, ensuring seamless operation during overlapping processes. Meanwhile, the KV cache reuse mechanism preserves partially valid data in CPU memory, reducing preemption latency by avoiding redundant KV cache transfers. These components collectively address key challenges and improve the overall performance of LLM serving systems.
The researchers evaluated FastSwitch using the LLaMA-8B and Qwen-32B models on GPUs such as NVIDIA A10 and A100. Testing scenarios included high-frequency priority updates and multi-turn conversations derived from the ShareGPT dataset, which averages 5.5 turns per conversation. FastSwitch outperformed vLLM across various metrics. It achieved speedups of 4.3-5.8x in P95 TTFT and 3.6-11.2x in P99.9 TBT for different models and workloads. Furthermore, FastSwitch improved throughput by up to 1.44x, demonstrating its ability to handle complex workloads efficiently. The system also substantially reduced context-switching overhead, improving I/O utilization by 1.3x and GPU by 1.42x compared to vLLM.
FastSwitch’s optimizations resulted in tangible benefits. For example, its KV cache reuse mechanism reduced swap-out blocks by 53%, significantly lowering latency. The multithreading swap manager enhanced token generation efficiency, achieving a 21.8% improvement at P99 latency compared to baseline systems. The dynamic block group manager maintained granularity by allocating memory in larger chunks, balancing efficiency and utilization. These advancements highlight FastSwitch’s capacity to maintain fairness and efficiency in high-demand environments.

Key takeaways from the research include:
- Dynamic Block Group Manager: Improved I/O bandwidth utilization through larger memory transfers, reducing context-switching latency by 3.11x.
- Multithreading Swap Manager: Increased token generation efficiency by 21.8% at P99 latency, minimizing GPU idle time with asynchronous operations.
- KV Cache Reuse Mechanism: Reduced swap-out volume by 53%, enabling efficient reuse of cache data and lowering preemption latency.
- Performance Metrics: FastSwitch achieved speedups of up to 11.2x in TBT and improved throughput by 1.44x under high-priority workloads.
- Scalability: Demonstrated robust performance across models like LLaMA-8B and Qwen-32B, showcasing versatility in diverse operational scenarios.

In conclusion, FastSwitch addresses fundamental inefficiencies in LLM serving by introducing innovative optimizations that balance fairness and efficiency. Reducing context-switching overheads and enhancing resource utilization ensure scalable, high-quality service delivery for multi-user environments. These advancements make it a transformative solution for modern LLM deployments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post FastSwitch: A Breakthrough in Handling Complex LLM Workloads with Enhanced Token Generation and Priority-Based Resource Management appeared first on MarkTechPost.
Source: Read MoreÂ
