




Parallel computing continues to advance, addressing the demands of high-performance tasks such as deep learning, scientific simulations, and data-intensive computations. A fundamental operation within this domain is matrix multiplication, which underpins many computational workflows. Recent hardware innovations, like Tensor Core Units (TCUs), offer efficient processing by optimizing constant-size matrix multiplications. These units are now being adapted for broader applications beyond neural networks, including graph algorithms and sorting, to improve computational efficiency.
Despite these innovations, prefix sum or scan algorithms, which calculate cumulative sums, still need help in matrix-based computations. Traditional approaches must be more efficient in managing computational depth and distributing work for large datasets. Also, the latency in initiating matrix operations and limited parallelism across tensor core units further complicate performance. Current methods based on the Parallel Random Access Machine (PRAM) model are effective for simpler binary operations but need to exploit the full potential of modern tensor core hardware in matrix-intensive scenarios.
Existing methods for prefix sum computations include tree-based algorithms like Brent-Kung, which optimize the trade-offs between depth and work in the PRAM model. However, these algorithms are constrained by their reliance on basic operations and are not designed for large-scale matrix computations. GPU-based approaches using warp- and block-level algorithms have succeeded with small data segments but need help with larger datasets due to underutilization of tensor cores and high overhead from memory operations like gather and scatter.
Researchers from Huawei Technologies introduced a novel algorithm called MatMulScan to address these challenges, specifically designed for the Tensor Core Unit model. The algorithm leverages the capabilities of TCUs to perform efficient matrix multiplications, minimizing computational depth while achieving high throughput. MatMulScan is tailored for applications like gradient boosting trees and parallel sorting. It extends traditional algorithms to handle matrices, using specialized designs like lower triangular matrices to encode local prefix sums and scalar-vector additions.
MatMulScan consists of two main phases: an up-sweep phase and a down-sweep phase. During the up-sweep phase, prefix sums are computed to increase indices, ensuring efficient computation of cumulative sums for subsets of data. The down-sweep phase propagates these prefix sums across the remaining data, correcting any local sums to produce accurate results. This approach optimizes latency and hardware utilization, ensuring scalability for large datasets. Analysis shows that the algorithm achieves significant reductions in computational depth and performs efficiently on large-scale matrix operations.
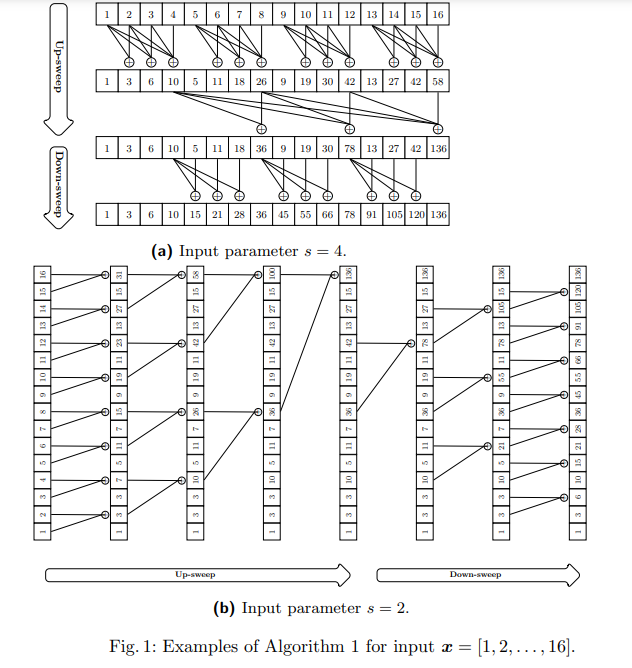
Extensive evaluations of MatMulScan demonstrated its practical utility. For example, the algorithm effectively reduces computational depth compared to traditional methods while performing fewer matrix multiplications. Its work requirements are optimized for large datasets, making it a strong candidate for real-world applications. Also, the algorithm addresses latency costs by integrating efficient matrix multiplication processes with hardware-specific optimizations. This ensures linear scalability with data size, making it suitable for high-performance computing environments.
The study highlighted several key takeaways that contribute to advancing parallel computations:
- Reduced Computational Depth: The algorithm optimizes computational depth, significantly decreasing the processing steps required for large datasets.
- Enhanced Scalability: It efficiently scales with increasing data sizes, maintaining performance across diverse applications.
- Improved Hardware Utilization: By leveraging tensor core capabilities, the algorithm enhances hardware efficiency, overcoming limitations seen in prior methods.
- Broad Applicability: Beyond prefix sums, MatMulScan demonstrates potential in applications such as gradient-boosting tree models, parallel sorting, and graph algorithms.


In conclusion, MatMulScan is a pivotal development in parallel scan algorithms, addressing traditional scalability and computational depth limitations. By integrating tensor core technology, the algorithm balances performance and practicality, paving the way for future advancements in high-performance computing. This research expands the utility of TCUs and sets the stage for innovative applications in computational science and engineering.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 59k+ ML SubReddit.

 ‘
‘The post Huawei Research Developed MatMulScan: A Parallel Scan Algorithm Transforming Parallel Computing with Tensor Core Units, Enhancing Efficiency and Scalability for Large-Scale Matrix Operations appeared first on MarkTechPost.
Source: Read MoreÂ