


Large Language Models (LLMs) have revolutionized data analysis by introducing novel approaches to regression tasks. Traditional regression techniques have long relied on handcrafted features and domain-specific expertise to model relationships between metrics and selected features. However, these methods often struggle with complex, nuanced datasets that require semantic understanding beyond numerical representations. LLMs provide a groundbreaking approach to regression by leveraging free-form text, overcoming the limitations of traditional methods. Bridging the gap between advanced language comprehension and robust statistical modeling is key to redefining regression in the age of modern natural language processing.
Existing research methods for LLM-based regression have largely overlooked the potential of service-based LLM embeddings as a regression technique. While embedding representations are widely used in retrieval, semantic similarity, and downstream language tasks, their direct application in regression still needs to be explored. Previous approaches have primarily focused on decoding-based regression techniques, which generate predictions through token sampling. In contrast, embedding-based regression offers a novel approach, enabling data-driven training using cost-effective post-embedding layers like multi-layer perceptrons (MLPs). However, significant challenges emerge when applying high-dimensional embeddings to function domains.
Researchers from Stanford University, Google, and Google DeepMind have presented a comprehensive investigation into embedding-based regression using LLMs. Their approach demonstrates that LLM embeddings can outperform traditional feature engineering techniques in high-dimensional regression tasks. The study contains a novel perspective on regression modeling by using semantic representations that inherently preserve Lipschitz continuity over the feature space. Moreover, the study aims to bridge the gap between advanced natural language processing and statistical modeling by systematically analyzing the potential of LLM embeddings. The work quantifies the impact of critical model characteristics, particularly model size, and language understanding capabilities.
The research methodology utilizes a carefully controlled architectural approach to ensure fair and rigorous comparison across different embedding techniques. The team used a consistent MLP prediction head with two hidden layers and ReLU activation maintaining uniform loss calculation using mean squared error. Researchers benchmark across diverse language model families, specifically the T5 and Gemini 1.0 models, which feature distinct architectures, vocabulary sizes, and embedding dimensions to validate the generalizability of the approach. Lastly, average pooling is adopted as the canonical method for aggregating Transformer outputs to ensure the embedding dimension directly corresponds to the output feature dimension following a forward pass.
The experimental results reveal fascinating insights into the performance of LLMs across various regression tasks. Experiments with T5 models demonstrate a clear correlation between model size and improved performance when training methodology remains consistent. In contrast, the Gemini family shows more complex behavior, with larger model sizes not necessarily yielding superior results. This variance is attributed to differences in model “recipes,†including variations in pre-training datasets, architectural modifications, and post-training configurations. The study finds that the default forward pass of pre-trained models generally performs best, though improvements were minimal in specific tasks like AutoML, L2DA, etc.
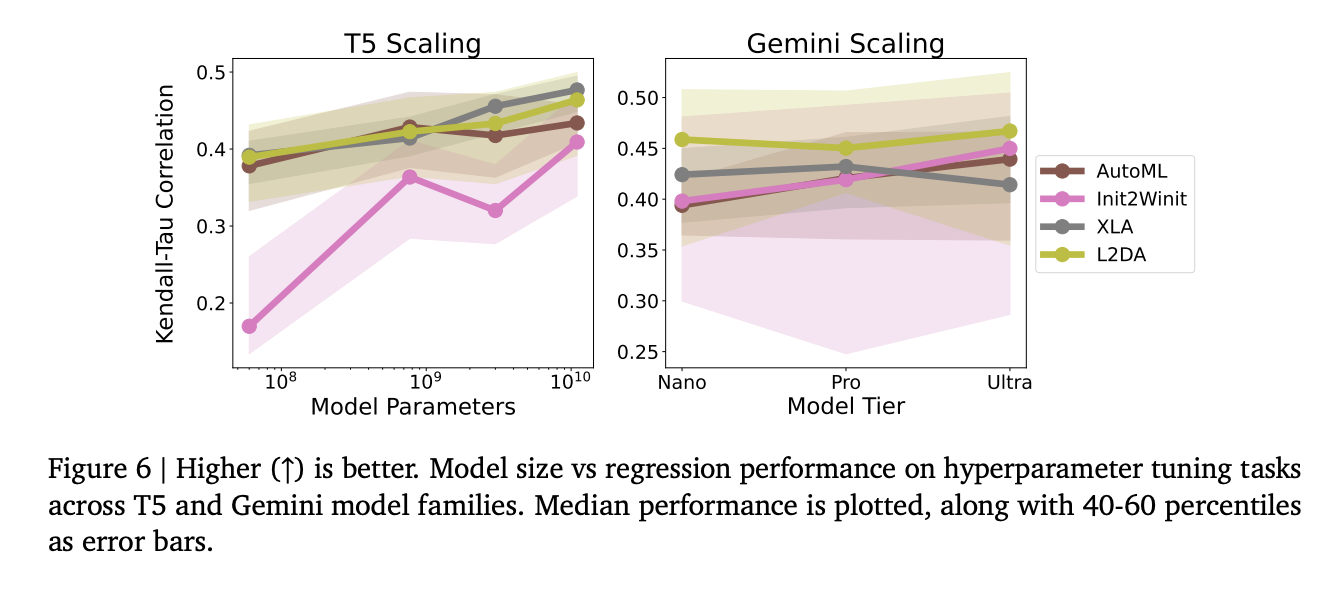
In conclusion, researchers introduced a comprehensive exploration of LLM embeddings in regression tasks offering significant insights into their potential and limitations. By investigating multiple critical aspects of LLM embedding-based regression, the study reveals that these embeddings can be highly effective for input spaces with complex, high-dimensional characteristics. Moreover, the researchers introduced the Lipschitz factor distribution technique to understand the relationship between embeddings and regression performance. They suggest exploring the application of LLM embeddings to diverse input types, including non-tabular data like graphs, and extending the approach to other modalities like images and videos.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Google DeepMind Research Unlocks the Potential of LLM Embeddings for Advanced Regression appeared first on MarkTechPost.
Source: Read MoreÂ

