


The advent of LLMs has propelled advancements in AI for decades. One such advanced application of LLMs is Agents, which replicate human reasoning remarkably. An agent is a system that can perform complicated tasks by following a reasoning process similar to humans: think (solution to the problem), collect (context from past information), analyze(the situations and data), and adapt (based on the style and feedback). Agents encourage the system through dynamic and intelligent activities, including planning, data analysis, data retrieval, and utilizing the model’s past experiences.Â
A typical agent has four components:
- Brain: An LLM with advanced processing capabilities, such as prompts.
- Memory: For storing and recalling information.
- Planning: Decomposing tasks into sub-sequences and creating plans for each.
- Tools: Connectors that integrate LLMs with the external environment, akin to joining two LEGO pieces. Tools allow agents to perform unique tasks by combining LLMs with databases, calculators, or APIs.
Now that we have established the wonders of agents in transforming an ordinary LLM into a specialized and intelligent tool, it is necessary to assess the effectiveness and reliability of an agent. Agent evaluation not only ascertains the quality of the framework in question but also identifies the best processes and reduces inefficiencies and bottlenecks. This article discusses four ways to gauge the effectiveness of an agent.
- Agent as Judge: It is the assessment of AI by AI and for AI. LLMs take on the roles of judge, invigilator, and examinee in this arrangement. The judge scrutinizes the examinee’s response and gives its ruling based on accuracy, completeness, relevance, timeliness, and cost efficiency. The examiner coordinates between the judge and examinee by providing the target tasks and retrieving the response from the judge. The examiner also offers descriptions and clarifications to the examinee LLM. The “Agent as Judge†framework has eight interacting modules. Agents perform the role of judge much better than LLMs, and this approach has a high alignment rate with human evaluation. One such instance is the OpenHands evaluation, where Agent Evaluation performed 30% better than LLM judgment.
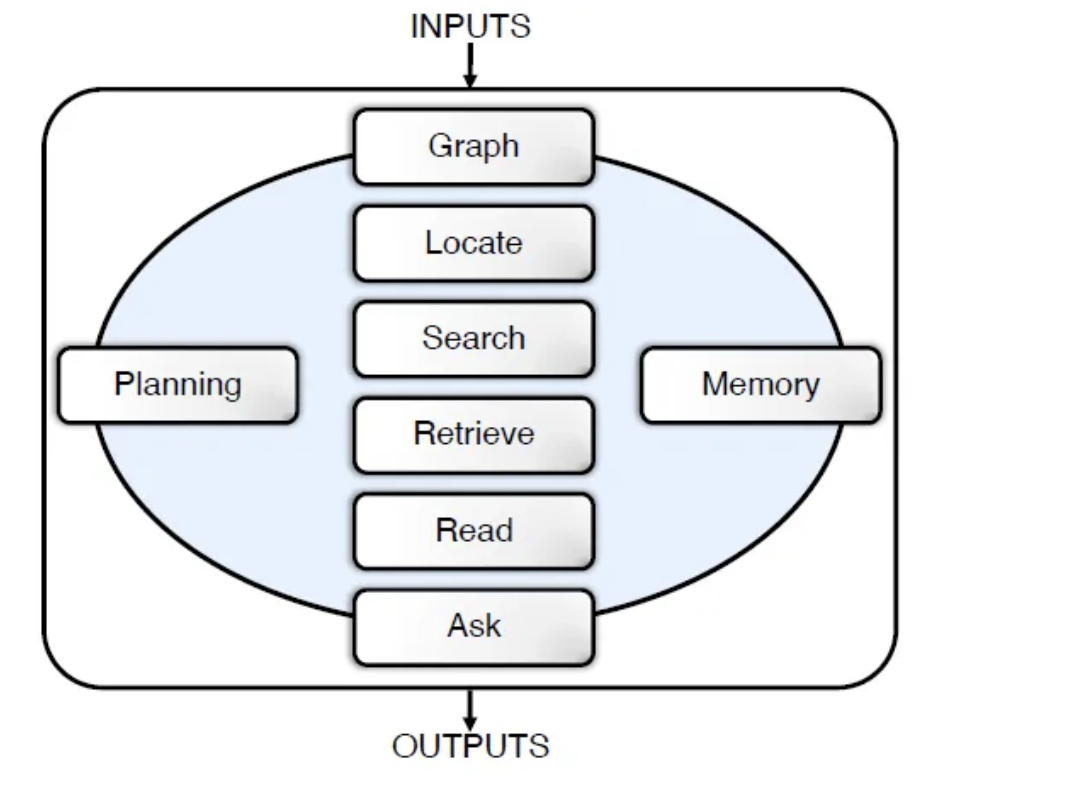
- Agentic Application Evaluation Framework (AAEF) assesses agents’ performance on specific tasks. Qualitative outcomes such as effectiveness, efficiency, and adaptability are measured for agents through four components: Tool Utilization Efficacy (TUE), Memory Coherence and Retrieval (MCR), Strategic Planning Index (SPI), and Component Synergy Score (CSS). Each of these specializes in different assessment criteria, from the selection of appropriate tools to the measurement of memory, the ability to plan and execute, and the ability to work coherently.
- MOSAIC AI: The Mosaic AI Agent Framework for evaluation, announced by Databricks, solves multiple challenges simultaneously. It offers a unified set of metrics, including but not limited to accuracy, precision, recall, and F1 score, to ease the process of choosing the right metrics for evaluation. It further integrates human review and feedback to define high-quality responses. Besides furnishing a solid pipeline for evaluation, Mosaic AI also has MLFlow integration to take the model from development to production while improving it. Mosaic AI also provides a simplified SDK for app lifecycle management.
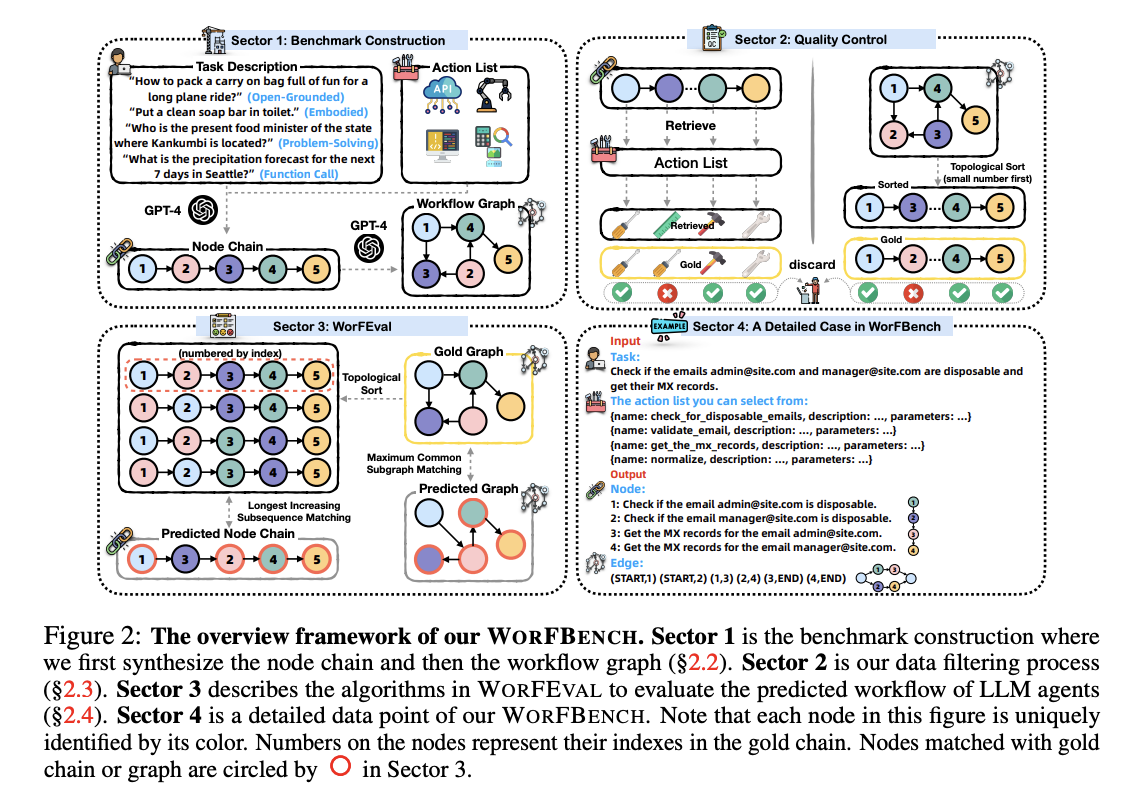
- WORFEVAL: It is a systematic protocol that helps assess an LLM agent’s workflow capabilities through quantitative algorithms based on advanced subsequence and subgraph matching. This evaluation technique compares predicted node chains and workflow graphs with correct flows. WORFEVAL comes on the advanced end of the spectrum, where agent application is done on complex structures like Directed Acyclic Graphs in a multi-faceted scenario.
Each of the above methods helps developers test if their agent is performing satisfactorily and find the optimal configuration, but they have their demerits. Discussing Agent Judgment first could be questioned in complex tasks that require deep knowledge. One could always ask about the competence of the teacher! Even agents trained on specific data may have biases that hinder generalization. AAEF faces a similar fate in complex and dynamic tasks. MOSAIC AI is good, but its credibility decreases as the scale and diversity of data increase. At the highest end of the spectrum, WORFEVAL performs well even on complex data, but its performance depends on the correct workflow, which is a random variable—the definition of the correct workflow changes from computer to computer.
Conclusion: Agents are an attempt to make LLMs more human-like with reasoning capabilities and intelligent decision-making. The evaluation of agents is thus imperative to ensure their claims and quality. Agents as Judge, the Agentic Application Evaluation Framework, Mosaic AI, and WORFEVAL are the current top evaluation techniques. While Agents as Judge starts with the basic intuitive idea of peer review, WORFEVAL deals with complex data. Although these evaluation methods perform well in their respective contexts, they face difficulties as tasks become more intricate with complicated structures.
The post Four Cutting-Edge Methods for Evaluating AI Agents and Enhancing LLM Performance appeared first on MarkTechPost.
Source: Read MoreÂ

