

Function calling has emerged as a transformative capability in AI systems, enabling language models to interact with external tools through structured JSON object generation. However, current methodologies face critical challenges in comprehensively simulating real-world interaction scenarios. Existing approaches predominantly focus on generating tool-specific call messages, overlooking the nuanced requirements of human-AI conversational interactions. The complexity of tool-use dialogs extends beyond mere mechanical function invocation, demanding a more holistic approach that seamlessly navigates tool interactions and user communication. Thus, there is a need for more complex and adaptive function-calling frameworks that bridge the gap between technical precision and natural conversational dynamics.
Recent studies have increasingly focused on exploring how language models utilize tools, leading to the development of various benchmarks for evaluating their capabilities. Prominent evaluation frameworks like APIBench, GPT4Tools, RestGPT, and ToolBench have concentrated on developing systematic assessment methodologies for tool usage. Existing innovative approaches like MetaTool investigate tool usage awareness, while BFCL introduces function relevance detection. Despite these advancements, existing methodologies predominantly focus on generating tool call-type outputs, which do not directly interact with users. This narrow evaluation approach reveals a critical gap in comprehensively measuring language models’ interactive capabilities.
Researchers from Kakao Corp. / Sungnam, South Korea have proposed FunctionChat-Bench, a method to evaluate language models’ function calling capabilities across diverse interaction scenarios. This method addresses the critical limitations in existing evaluation methodologies by introducing a robust dataset comprising 700 assessment items and automated evaluation programs. Moreover, FunctionChat-Bench examines language models’ performance across single-turn and multi-turn dialogue contexts focusing on function-calling capabilities. It critically challenges the assumption that high performance in isolated tool call scenarios directly correlates with overall interactive proficiency.
The FunctionChat-Bench benchmark introduces a complex two-subset evaluation framework to evaluate the function calling capabilities of language models, (a) Single call dataset and (b) Dialog dataset. The following conditions define evaluation items in the Single call dataset:
- The user’s single-turn utterance must contain all the necessary information for function invocation, leading directly to a tool call.Â
- A suitable function for carrying out the user’s request must be given in the available tool list.
In contrast, the Dialog dataset simulates more complex real-world interaction scenarios, challenging language models to navigate diverse input contexts. Key evaluation criteria for the proposed method include the model’s capacity to communicate tool invocation results, request missing information when necessary, and handle user interactions.
Experimental results from the FunctionChat-Bench reveal detailed insights into language models’ function calling performance across different scenarios. The accuracy of models did not consistently decrease by increasing the number of function candidates between 1 and 8 candidates. Notably, the Gemini model demonstrates improved accuracy as the number of function candidates increases. GPT-4-turbo shows a substantial 10-point accuracy difference between random and close function type scenarios. Moreover, the dialog dataset provides tool call generations, conversational outputs, slot-filling questions, and tool call relevance detection across multi-turn discourse interactions.
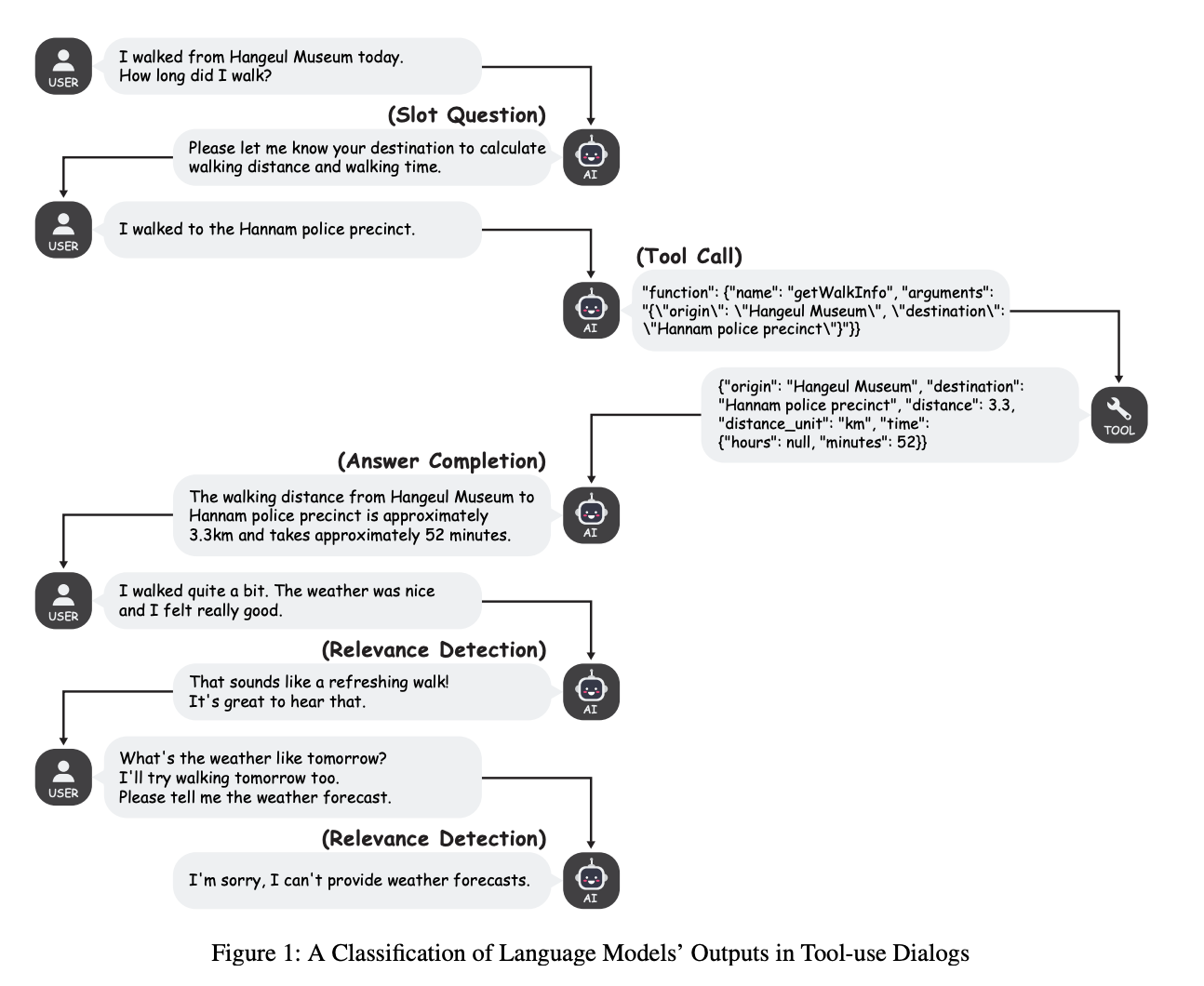
In this paper, researchers introduced FunctionChat-Bench, a benchmark that comprehensively evaluates language models’ function-calling capabilities, extending beyond traditional assessment methodologies. They provide detailed insights into language models’ generative performance by developing a novel dataset with Single call and Dialog subsets, and an automated evaluation program. Utilizing an advanced LLM as an evaluation judge with refined rubrics, FunctionChat-Bench offers a complex framework for evaluating function calling proficiency. However, this benchmark has limitations while evaluating advanced function calling applications. The study sets a foundation for future research, highlighting the complexity of interactive AI systems.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post FunctionChat-Bench: Comprehensive Evaluation of Language Models’ Function Calling Capabilities Across Interactive Scenarios appeared first on MarkTechPost.
Source: Read MoreÂ

