


Reinforcement Learning (RL) represents a robust computational approach to decision-making formulated through the Markov Decision Processes (MDPs) framework. RL has gained prominence for its ability to address complex tasks in games, robotics, and computational language processing. RL systems are designed to learn through iterative feedback mechanisms by optimizing policies to achieve cumulative rewards. However, despite its successes, RL’s reliance on mathematical rigor and scalar-based evaluations often limits its adaptability and interpretability in nuanced and linguistically rich environments.
A critical issue in traditional RL is its inability to effectively handle diverse, multi-modal inputs, such as textual feedback, which are naturally present in many real-world scenarios. These systems must be more interpretable, as their decision-making processes are even opaque to experienced analysts. Moreover, RL frameworks depend heavily on extensive data sampling and precise mathematical modeling, rendering them unsuitable for tasks that demand rapid generalization or reasoning grounded in linguistic contexts. This limitation presents a barrier to deploying RL solutions in domains where textual understanding and explanation are critical.
Current RL methodologies predominantly utilize numerical reward systems and mathematical optimization techniques. Two common approaches are Monte Carlo (MC) and Temporal Difference (TD) methods, which estimate value functions based on cumulative or immediate feedback. However, these techniques often overlook the potential richness of language as a feedback mechanism. Although large language models (LLMs) are increasingly used as decision-making agents, they are typically employed as external evaluators or summarizers rather than as integrated components within RL systems. This lack of integration limits their ability to exploit the advantages of natural language processing in decision-making fully.
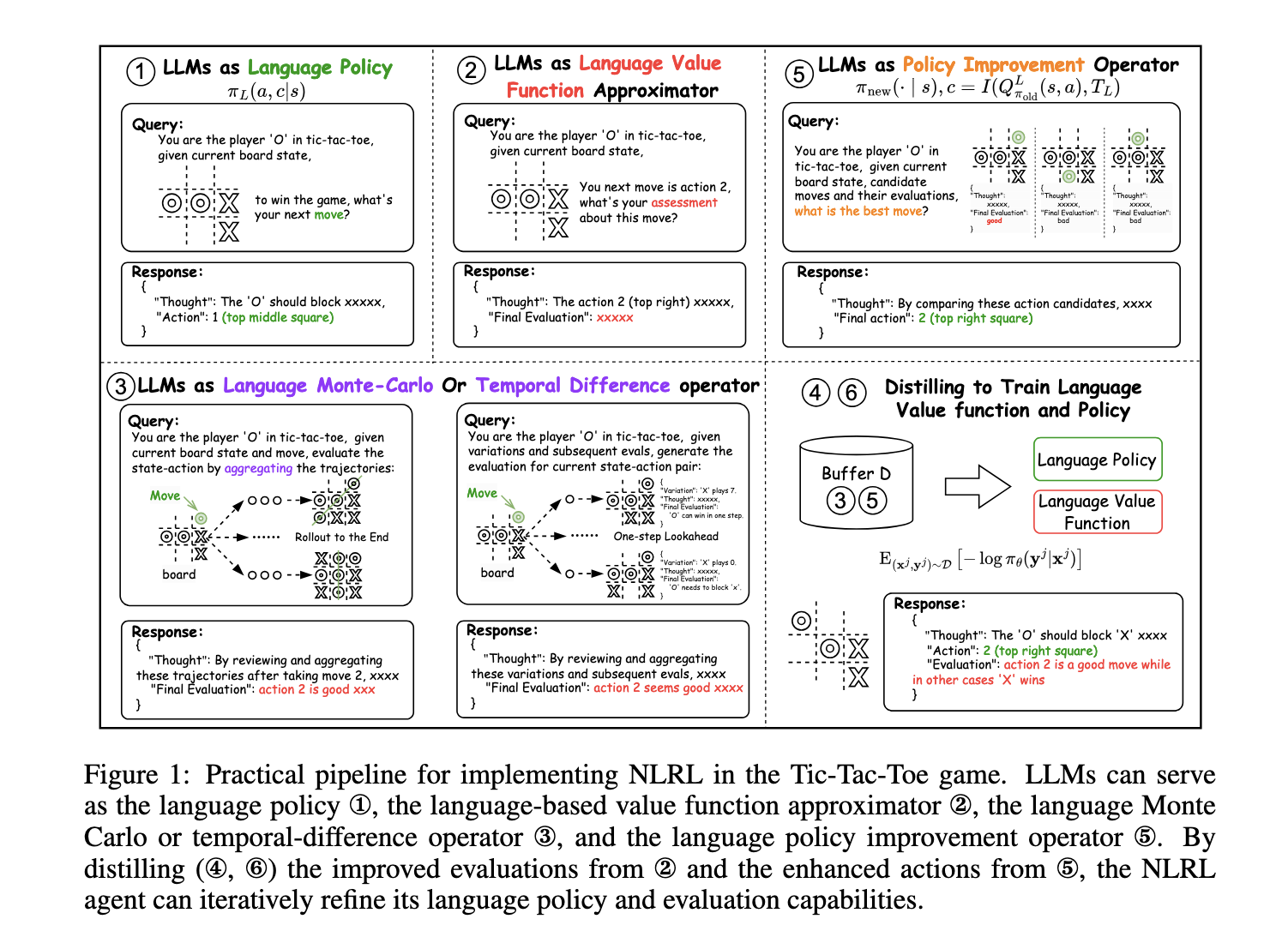
Researchers from University College London, Shanghai Jiao Tong University, Brown University, National University of Singapore, University of Bristol, and University of Surrey propose Natural Language Reinforcement Learning (NLRL) as a transformative paradigm. NLRL extends traditional RL principles into natural language spaces, redefining key components such as policies, value functions, and Bellman equations in linguistic terms. This approach leverages advancements in LLMs to make RL more interpretable and capable of utilizing textual feedback for improved learning outcomes. The researchers employed this framework in diverse experiments, demonstrating its capacity to enhance RL systems’ efficiency and adaptability.
NLRL employs a language-based MDP framework that transforms states, actions, and feedback into textual representations. The policy in this framework is modeled as a chain-of-thought process, enabling the system to reason, strategize, and plan effectively in natural language. Value functions traditionally rely on scalar evaluations and are redefined as language-based constructs that encapsulate richer contextual information. The framework also incorporates analogical language Bellman equations to facilitate the iterative improvement of language-based policies. Further, NLRL supports scalable implementations through prompting techniques and gradient-based training, allowing for efficient adaptation to complex tasks.
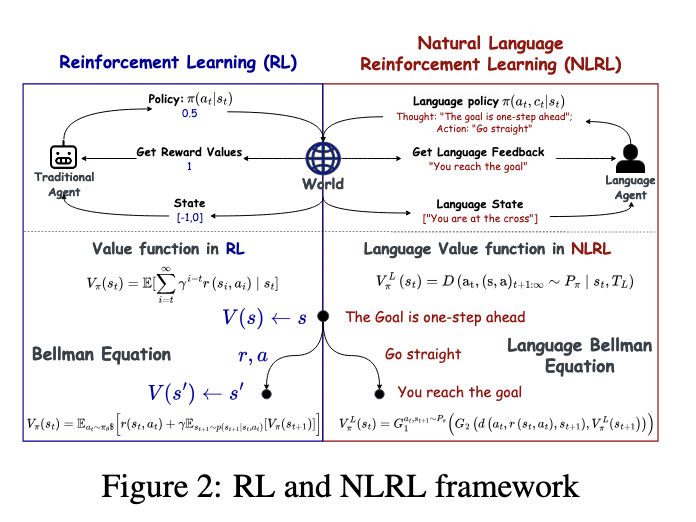
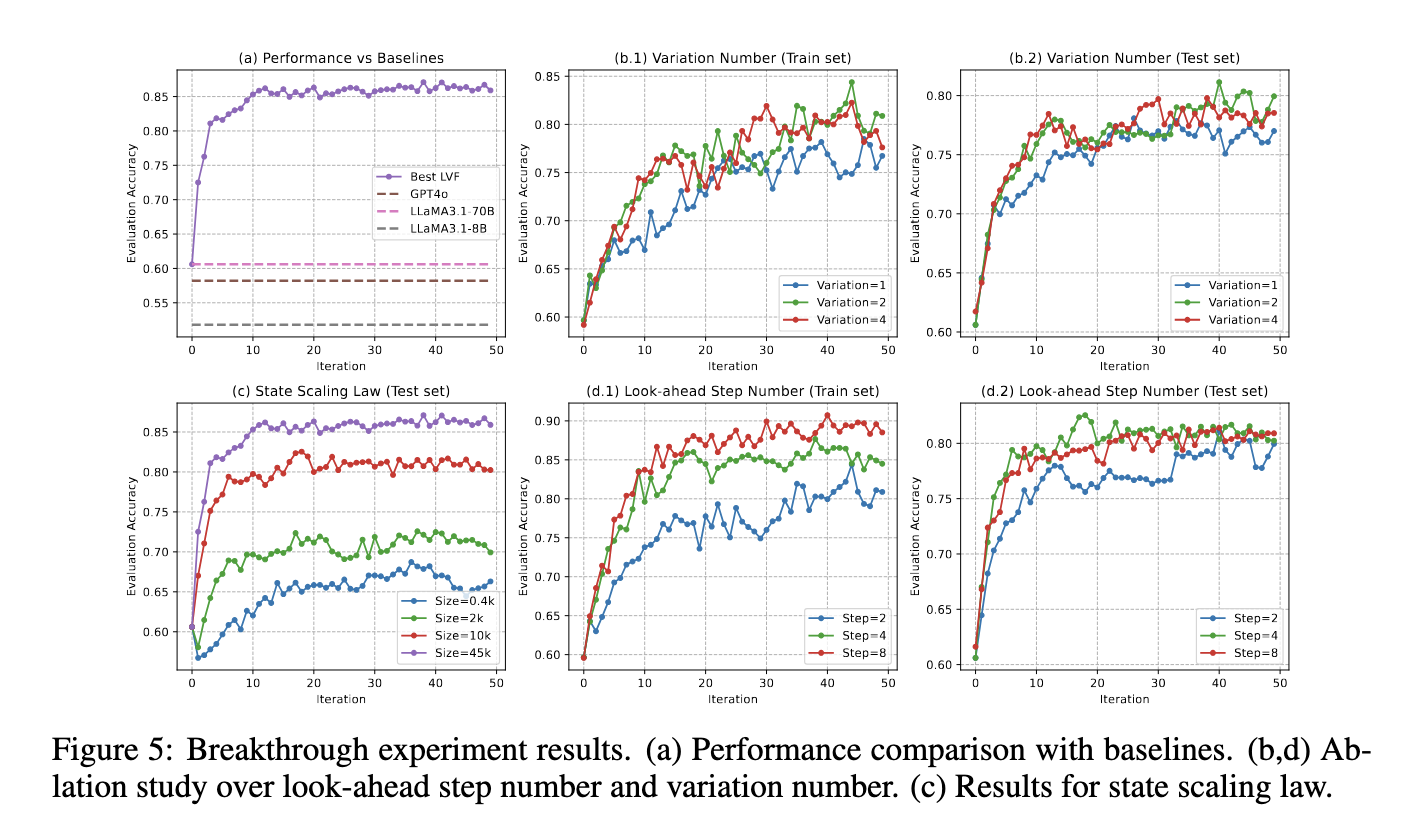
The results from the NLRL framework indicate significant improvements over traditional methods. For instance, in the Breakthrough board game, NLRL achieved an evaluation accuracy of 85% on test datasets, compared to the 61% accuracy of the best-performing baseline models. In the Maze experiments, NLRL’s language TD estimation enhanced interpretability and adaptability by integrating multi-step look-ahead strategies. In another experiment involving Tic-Tac-Toe, the language actor-critic pipeline, they outperformed standard RL models by achieving higher win rates against deterministic and stochastic opponents. These results highlight NLRL’s ability to leverage textual feedback effectively, making it a versatile tool across varied decision-making tasks.
This research illustrates the potential of NLRL to address the interpretability and adaptability challenges inherent in traditional RL systems. By redefining RL components through the lens of natural language, NLRL enhances learning efficiency and improves the transparency of decision-making processes. This integration of natural language into RL frameworks represents a significant advancement, positioning NLRL as a viable solution for tasks that demand precision and human-like reasoning capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post This AI Paper Proposes NLRL: A Natural Language-Based Paradigm for Enhancing Reinforcement Learning Efficiency and Interpretability appeared first on MarkTechPost.
Source: Read MoreÂ

