


Transformer models have driven groundbreaking advancements in artificial intelligence, powering applications in natural language processing, computer vision, and speech recognition. These models excel at understanding and generating sequential data by leveraging mechanisms like multi-head attention to capture relationships within input sequences. The rise of large language models (LLMs) built upon transformers has amplified these capabilities, enabling tasks ranging from complex reasoning to creative content generation.
However, LLMs’ increasing size and complexity come at the cost of computational efficiency. These models rely heavily on fully connected layers and multi-head attention operations, which demand significant resources. In most practical scenarios, fully connected layers dominate the computational load, making it challenging to scale these models without incurring high energy and hardware costs. This inefficiency restricts their accessibility and scalability across broader industries and applications.
Various methods have been proposed to tackle the computational bottlenecks in transformer models. Techniques like model pruning and weight quantization have moderately improved efficiency by reducing model size and precision. Redesigning the self-attention mechanism, such as linear and flash-attention, has diminished its computational complexity from quadratic to linear concerning sequence length. However, these approaches often need to pay more attention to the contribution of fully connected layers, leaving a substantial portion of the computation unoptimized.
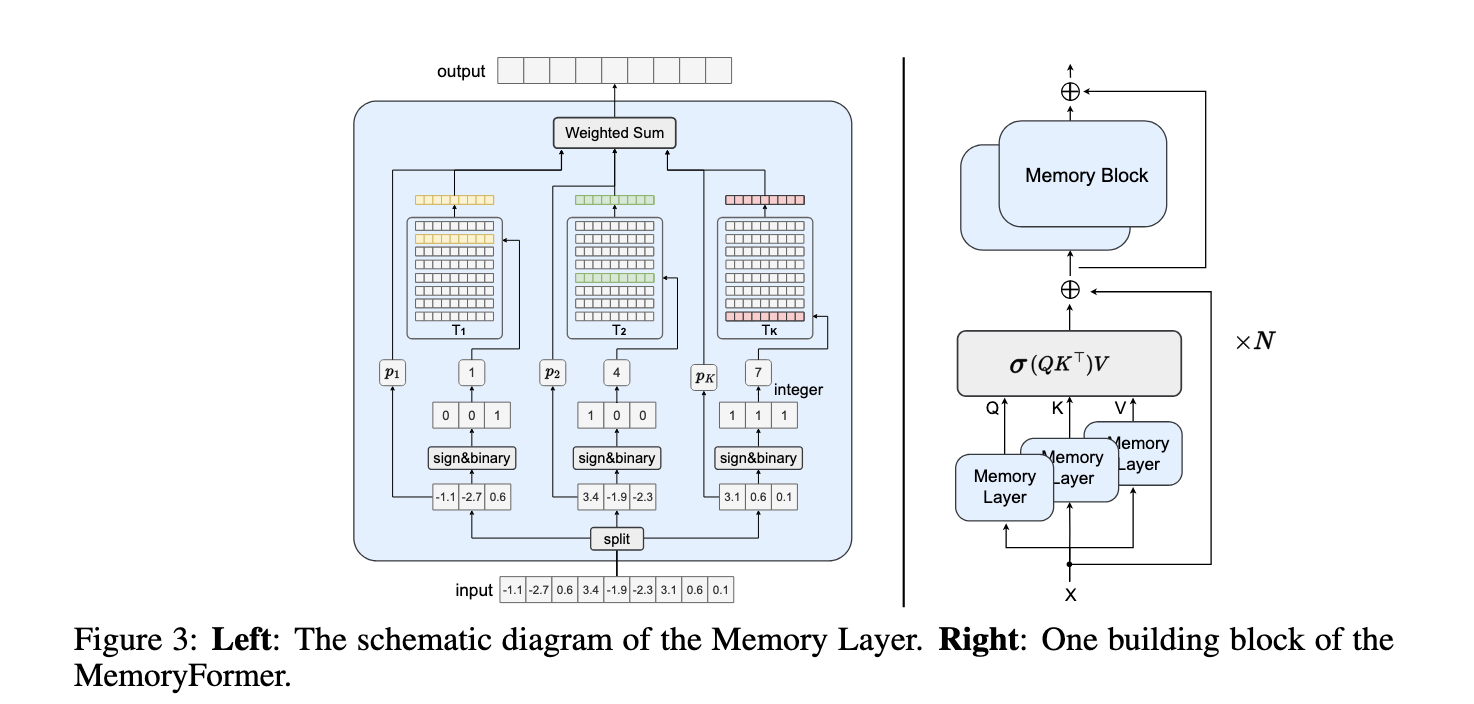
Researchers from Peking University, Huawei Noah’s Ark Lab, and Huawei HiSilicon introduced MemoryFormer. This transformer architecture eliminates the computationally expensive fully-connected layers, replacing them with Memory Layers. These layers utilize in-memory lookup tables and locality-sensitive hashing (LSH) algorithms. MemoryFormer aims to transform input embeddings by retrieving pre-computed vector representations from memory instead of performing conventional matrix multiplications.
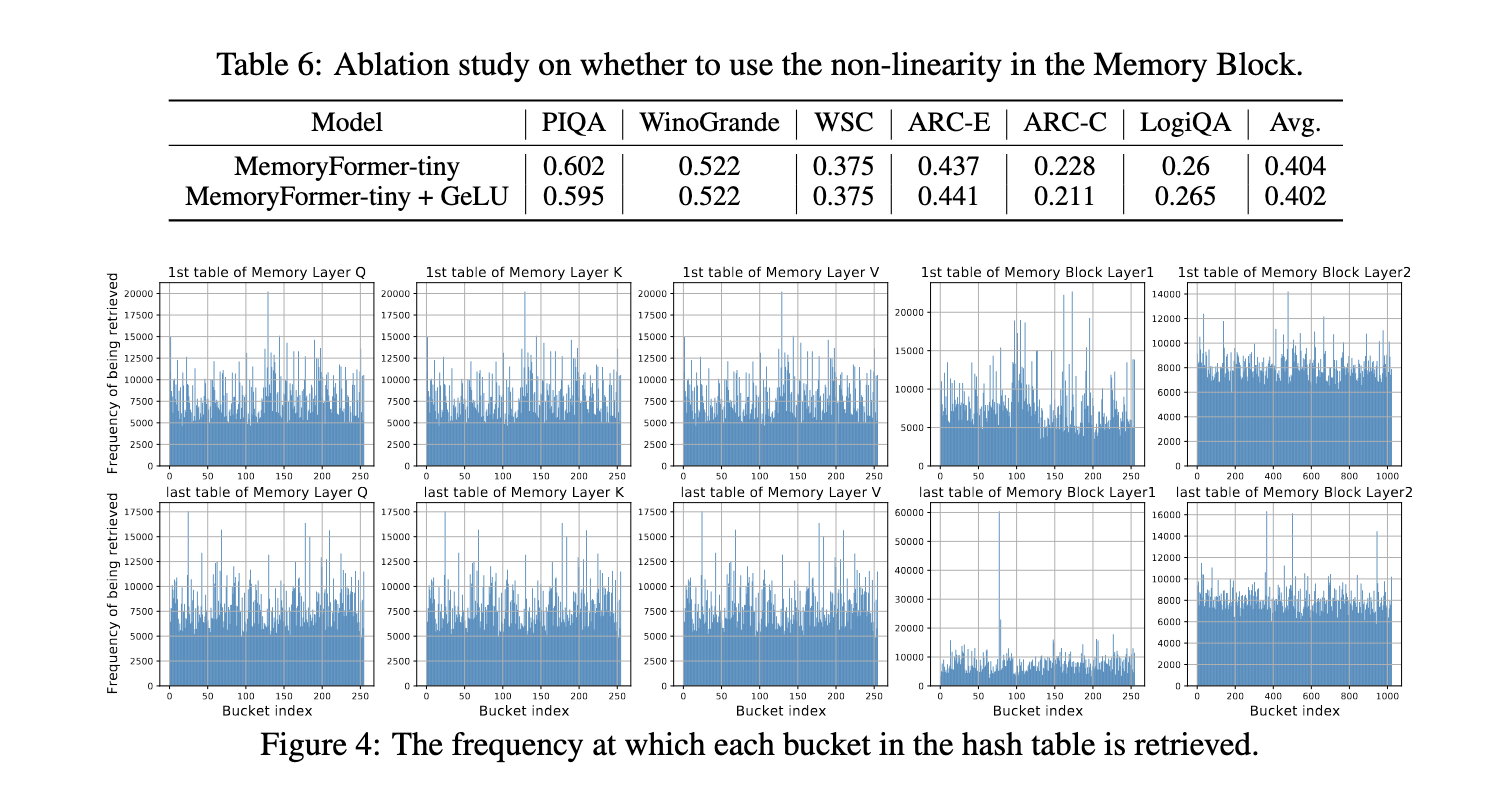
The core innovation in MemoryFormer lies in its Memory Layer design. Instead of directly performing linear projections, input embeddings are hashed using a locality-sensitive hashing algorithm. This process maps similar embeddings to the same memory locations, allowing the model to retrieve pre-stored vectors that approximate the results of matrix multiplications. By dividing embeddings into smaller chunks and processing them independently, MemoryFormer reduces memory requirements and computational load. The architecture also incorporates learnable vectors within hash tables, enabling the model to be trained end-to-end using back-propagation. This design ensures that MemoryFormer can handle diverse tasks while maintaining efficiency.
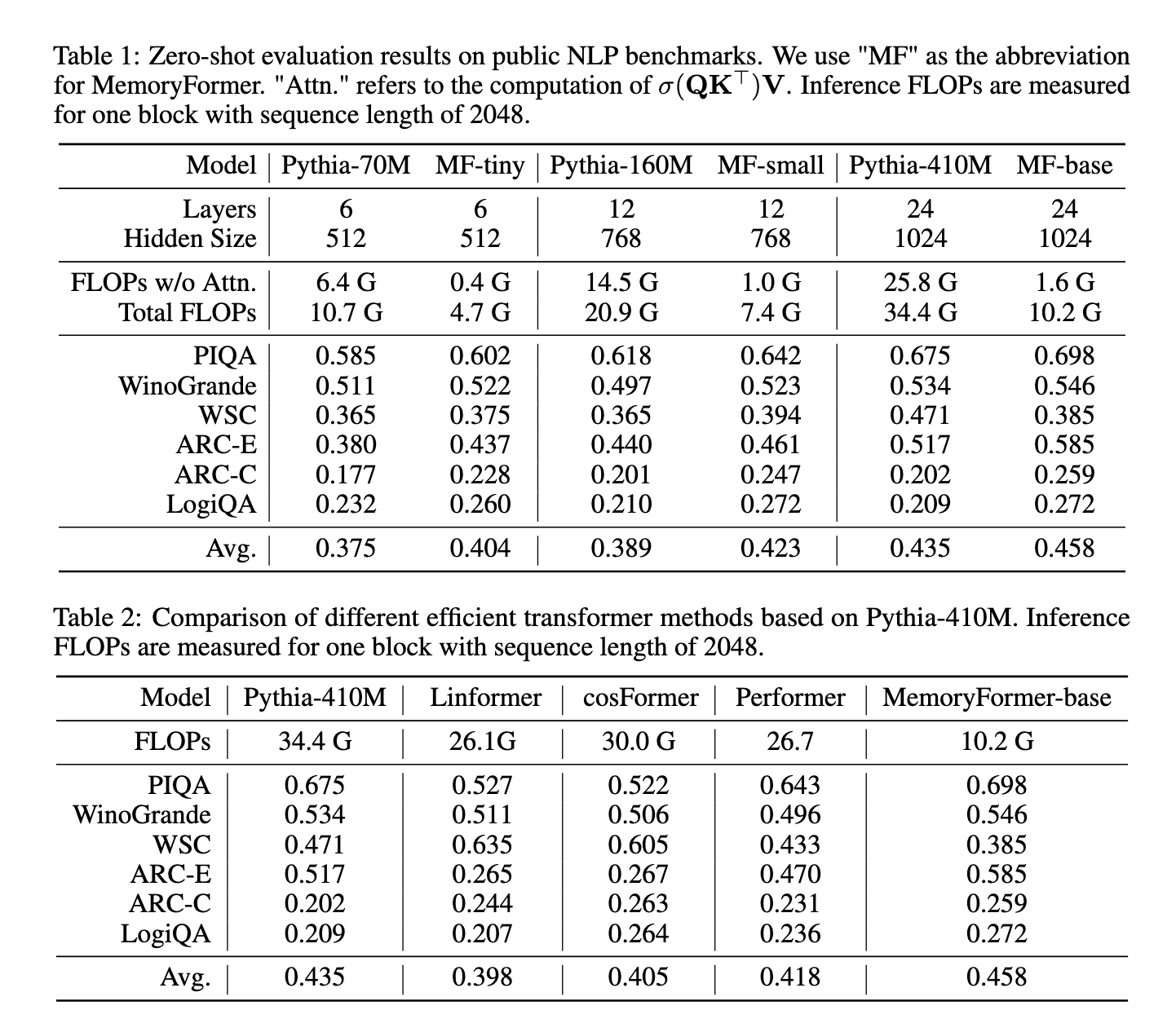
MemoryFormer demonstrated exceptional performance and efficiency during experiments conducted across multiple NLP benchmarks. For sequence lengths of 2048 tokens, MemoryFormer reduced the computational complexity of fully connected layers by over an order of magnitude. The computational FLOPs for MemoryFormer were reduced to just 19% of a standard transformer block’s requirements. On specific tasks, such as PIQA and ARC-E, the MemoryFormer achieved accuracy scores of 0.698 and 0.585, respectively, surpassing the baseline transformer models. The overall average accuracy across evaluated tasks also improved, highlighting the model’s ability to maintain or enhance performance while significantly reducing computational overhead.
The researchers compared MemoryFormer with existing efficient transformer methods, including Linformer, Performer, and Cosformer. MemoryFormer consistently outperformed these models in terms of computational efficiency and benchmark accuracy. For example, compared to Performer and Linformer, which achieved average accuracies of 0.418 and 0.398, respectively, MemoryFormer reached 0.458 while utilizing fewer resources. Such results underline the effectiveness of its Memory Layer in optimizing transformer architectures.
In conclusion, MemoryFormer addresses the limitations of transformer models by minimizing computational demands through the innovative use of Memory Layers. The researchers demonstrated a transformative approach to balancing performance and efficiency by replacing fully-connected layers with memory-efficient operations. This architecture provides a scalable pathway for deploying large language models across diverse applications, ensuring accessibility and sustainability without compromising accuracy or capability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post MemoryFormer: A Novel Transformer Architecture for Efficient and Scalable Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ

