




Self-supervised learning on offline datasets has permitted large models to reach remarkable capabilities both in text and image domains. Still, analogous generalizations for agents acting sequentially in decision-making problems are difficult to attain. The environments of classical Reinforcement Learning (RL) are mostly narrow and homogeneous and, consequently, hard to generalize.
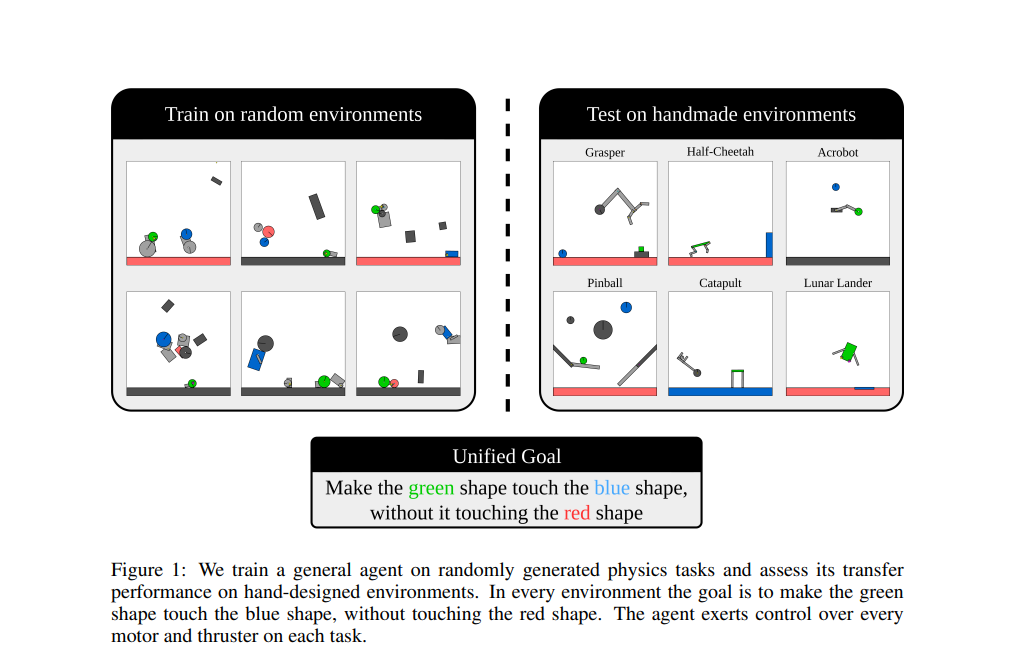
Current reinforcement learning (RL) methods often train agents on fixed tasks, limiting their ability to generalize to new environments. Platforms like MuJoCo and OpenAI Gym focus on specific scenarios, restricting agent adaptability. RL is based on Markov Decision Processes (MDPs), where agents maximize cumulative rewards by interacting with environments. Unsupervised Environment Design (UED) addresses these limitations by introducing a teacher-student framework, where the teacher designs tasks to challenge the agent and promote efficient learning. Certain metrics ensure tasks are neither too easy nor impossible. Tools like JAX enable faster GPU-based RL training through parallelization, while transformers, using attention mechanisms, enhance agent performance by modeling complex relationships in sequential or unordered data.
To address these limitations, a team of researchers has developed Kinetix, an open-ended space of physics-based RL environments.Â
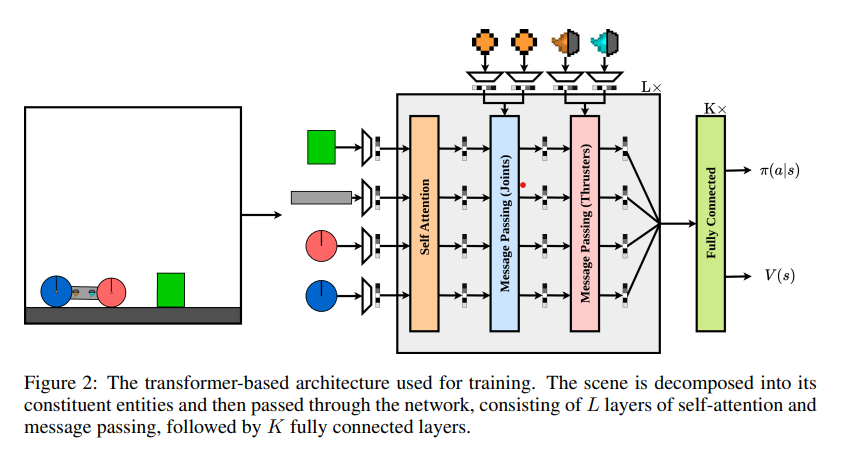
Kinetix, proposed by a team of researchers from Oxford University, can represent tasks ranging from robotic locomotion and grasping to video games and classic RL environments. Kinetix uses a novel hardware-accelerated physics engine, Jax2D, that allows for the cheap simulation of billions of environmental steps during training. The trained agent exhibits strong physical reasoning capabilities, being able to zero-shot solve unseen human-designed environments. Furthermore, fine-tuning this general agent on tasks of interest shows significantly stronger performance than training an RL agent tabula rasa. Jax2D applies discrete Euler steps for rotational and positional velocities and uses impulses and higher-order corrections to constrain instantaneous sequences for efficient simulation of diversified physical tasks. Kinetix is suited for multi-discrete and continuous action spaces and for a wide array of RL tasks.
The researchers trained a general RL agent on tens of millions of procedurally generated 2D physics-based tasks. The agent exhibited strong physical reasoning capabilities, being able to zero-shot solve unseen human-designed environments. Fine-tuning this demonstrates the feasibility of large-scale, mixed-quality pre-training for online RL.
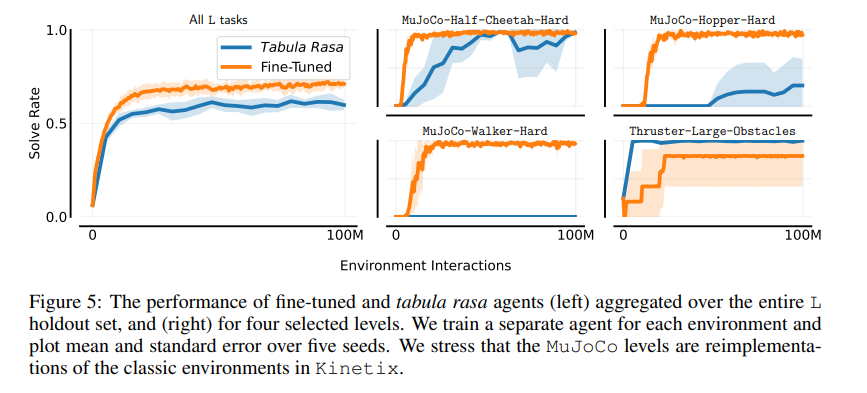
In conclusion, Kinetix is a discovery that addresses the limitations of traditional RL environments by providing a diverse and open-ended space for training, leading to improved generalization and performance of RL agents. This work can serve as a foundation for future research in large-scale online pre-training of general RL agents and unsupervised environment design.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post Kinetix: An Open-Ended Universe of Physics-based Tasks for Reinforcement Learning appeared first on MarkTechPost.
Source: Read MoreÂ
