




Retrieval-augmented generation (RAG) systems are essential in enhancing language model performance by integrating external knowledge sources into their workflows. These systems utilize methods that divide documents into smaller, manageable sections called chunks. RAG systems aim to improve both the accuracy and contextual relevance of their outputs by retrieving contextually appropriate chunks and feeding them into generative language models. The field is constantly evolving to address challenges related to document segmentation’s efficiency and scalability.
A key challenge in RAG systems is ensuring that chunking strategies effectively balance contextual preservation and computational efficiency. Traditional fixed-size chunking divides documents into uniform, consecutive parts and often fragments semantically related content. This fragmentation limits its usefulness in evidence retrieval and answer generation tasks. While alternative strategies like semantic chunking are gaining attention for their ability to group semantically similar information, their benefits over fixed-size chunking still need to be discovered. Researchers have questioned whether these methods can consistently justify the additional computational resources required.
Fixed-size chunking, while computationally straightforward, must be improved to maintain contextual continuity across document segments. Researchers have proposed semantic chunking strategies such as breakpoint-based and clustering-based methods. Breakpoint-based semantic chunking identifies points of significant semantic dissimilarity between sentences to create coherent segments. In contrast, clustering-based chunking uses algorithms to group semantically similar sentences, even if they are not consecutive. Various industry tools have implemented these methods, but systematic effectiveness evaluations still need to be more sparse.

Researchers from Vectara, Inc., and the University of Wisconsin-Madison evaluated chunking strategies to determine their performance across document retrieval, evidence retrieval, and answer generation tasks. Using sentence embeddings and data from benchmark datasets, they compared fixed-size, breakpoint-based, and clustering-based semantic chunking methods. The study aimed to measure retrieval quality, answer generation accuracy, and computational costs. Further, the team introduced a novel evaluation framework to address the need for ground-truth data for chunk-level assessments.
The evaluation involved multiple datasets, including stitched and original documents, to simulate real-world complexities. Stitched datasets contained artificially combined short documents with high topic diversity, while original datasets maintained their natural structure. The study used positional and semantic metrics for clustering-based chunking, combining cosine similarity with sentence positional proximity to improve chunking accuracy. Breakpoint-based chunking relied on thresholds to determine segmentation points. Fixed-size chunking included overlapping sentences between consecutive chunks to mitigate information loss. Metrics such as F1 scores for document retrieval and BERTScore for answer generation provided quantitative insights into performance differences.

The results revealed that semantic chunking offered marginal benefits in high-topic diversity scenarios. For instance, the breakpoint-based semantic chunker achieved an F1 score of 81.89% on the Miracl dataset, outperforming fixed-size chunking, which scored 69.45%. However, these advantages could have been more consistent across other tasks. In evidence retrieval, fixed-size chunking performed comparably or better in three of five datasets, indicating its reliability in capturing core evidence sentences. On datasets with natural structures, such as HotpotQA and MSMARCO, fixed-size chunking, they achieved F1 scores of 90.59% and 93.58%, respectively, demonstrating their robustness. Clustering-based methods struggled with maintaining contextual integrity in scenarios where positional information was critical.
Answer generation results highlighted minor differences between chunking methods. Fixed-size and semantic chunkers produced comparable results, with semantic chunkers showing slightly higher BERTScores in certain cases. For example, clustering-based chunking achieved a score of 0.50 on the Qasper dataset, marginally outperforming fixed-size chunking’s score of 0.49. However, these differences were insignificant enough to justify the additional computational costs associated with semantic approaches.
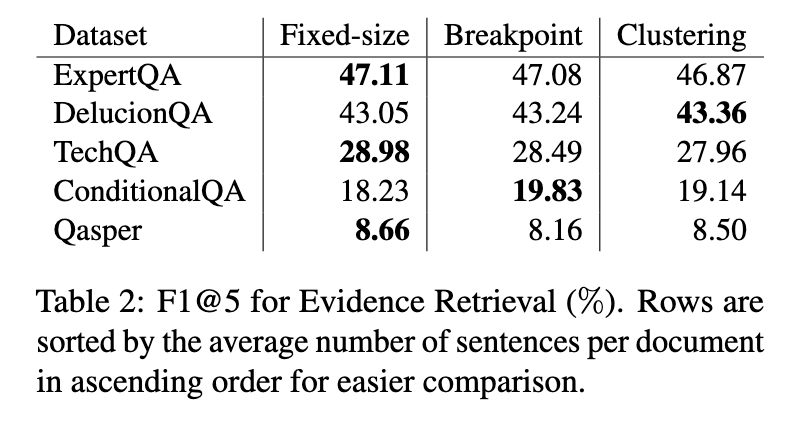
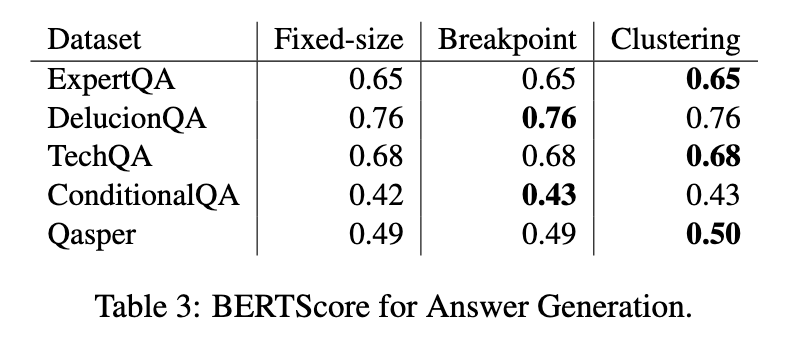
The findings emphasize that fixed-size chunking remains a practical choice for RAG systems, particularly in real-world applications where documents often feature limited topic diversity. While semantic chunking occasionally demonstrates superior performance in highly specific conditions, its computational demands and inconsistent results limit its broader applicability. Researchers concluded that future work should focus on optimizing chunking strategies to achieve a better balance between computational efficiency and contextual accuracy. The study underscores the importance of evaluating the trade-offs between chunking strategies in RAG systems. By systematically comparing these methods, the researchers provide valuable insights into their strengths and limitations, guiding the development of more efficient document segmentation techniques.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post This AI Paper from Vectara Evaluates Semantic and Fixed-Size Chunking: Efficiency and Performance in Retrieval-Augmented Generation Systems appeared first on MarkTechPost.
Source: Read MoreÂ
