


Embodied artificial intelligence (AI) involves creating agents that function within physical or simulated environments, executing tasks autonomously based on pre-defined objectives. Often used in robotics and complex simulations, these agents leverage extensive datasets and sophisticated models to optimize behavior and decision-making. In contrast to more straightforward applications, embodied AI requires models capable of managing vast amounts of sensorimotor data and complex interactive dynamics. As such, the field has increasingly prioritized “scaling,†a process that adjusts model size, dataset volume, and computational power to achieve efficient and effective agent performance across diverse tasks.
The challenge with scaling embodied AI models lies in striking a balance between model size and dataset volume, a process necessary to ensure that these agents can operate optimally within constraints on computational resources. Different from language models, where scaling is well-established, the precise interplay of factors like dataset size, model parameters, and computation costs in embodied AI still needs to be explored. This lack of clarity limits researchers’ ability to construct large-scale models effectively, as it remains unclear how to distribute resources for tasks requiring behavioral and environmental adaptation optimally. For instance, while increasing model size improves performance, doing so without a proportional increase in data can lead to inefficiencies or even diminished returns, especially in tasks like behavior cloning and world modeling.
Language models have developed robust scaling laws that outline relationships between model size, data, and compute requirements. These laws enable researchers to make educated predictions about the necessary configurations for effective model training. However, embodied AI has not fully adopted these principles, partly because of the varied nature of its tasks. In response, researchers have been working on transferring scaling insights from language models to embodied AI, particularly by pre-training agents on large offline datasets that capture diverse environmental and behavioral data. The aim is to establish laws that help embody agents achieve high performance in decision-making and interaction with their surroundings.
Researchers at Microsoft Research have recently developed scaling laws specifically for embodied AI, introducing a methodology that evaluates how changes in model parameters, dataset size, and computational limits impact the learning efficiency of AI agents. The team’s work focused on two major tasks within embodied AI: behavior cloning, where agents learn to replicate observed actions, and world modeling, where agents predict environmental changes based on prior actions and observations. They used transformer-based architectures, testing their models under various configurations to understand how tokenization strategies and model compression rates affect overall efficiency and accuracy. By systematically adjusting the number of parameters and tokens, the researchers observed distinct scaling patterns that could improve model performance and compute efficiency.
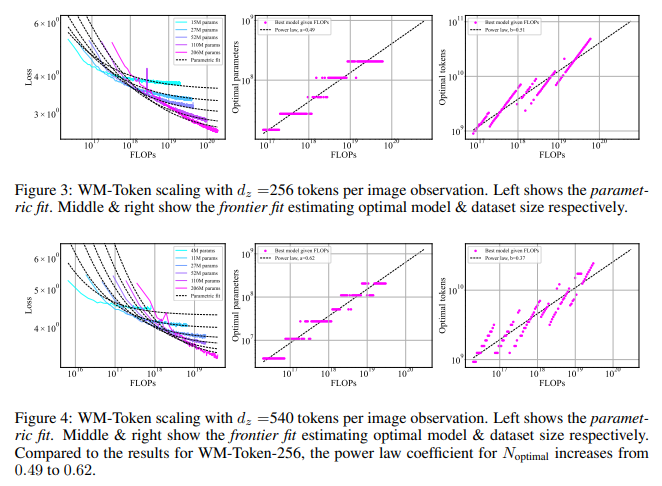
The methodology involved training transformers with different tokenization approaches to balance model and dataset sizes. For instance, the team implemented tokenized and CNN-based architectures in behavior cloning, allowing the model to operate under a continuous embedding framework rather than discrete tokens, reducing computational demands significantly. The study found that for world modeling, scaling laws demonstrated that an increase in token count per observation affected model sizing, with the optimal model size coefficient increasing from 0.49 to 0.62 as the tokens rose from 256 to 540 per image. However, for behavior cloning with tokenized observations, optimal model size coefficients were skewed towards larger datasets with smaller models, displaying a need for greater data volume rather than expanded parameters, an opposite trend to that seen in world modeling.
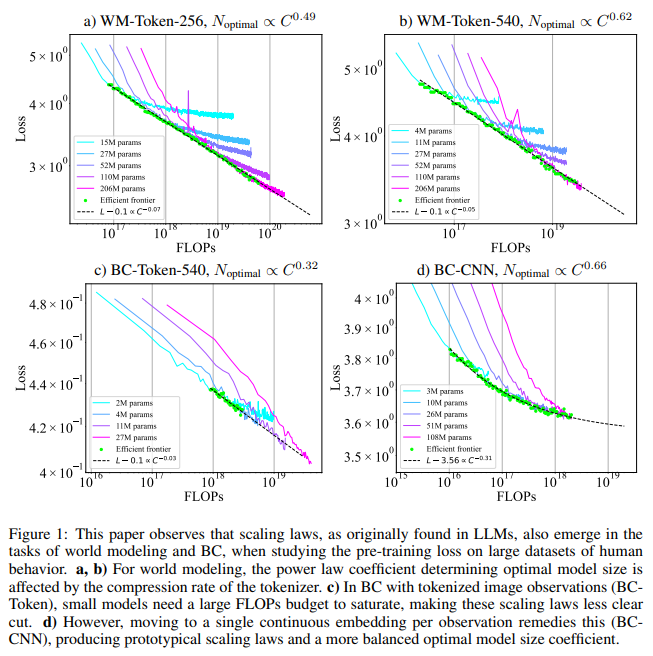
The study presented remarkable findings on how scaling principles from language models could be applied effectively to embodied AI. The optimal trade-off occurred for world modeling when both model and dataset size increased proportionally, matching findings in LLM scaling literature. Specifically, with a 256-token configuration, an optimal balance was achieved by scaling both model and dataset in similar proportions. In contrast, in the 540-token configuration, the emphasis shifted toward larger models, making size adjustments highly dependent on the compression rate of the tokenized observations.
Key results highlighted that model architecture influences the scaling balance, particularly for behavior cloning. In tasks where agents used tokenized observations, model coefficients indicated a preference for extensive data over larger model sizes, with an optimal size coefficient of 0.32 against a dataset coefficient of 0.68. In comparison, behavior cloning tasks based on CNN architectures favored increased model size, with an optimal size coefficient of 0.66. This demonstrated that embodied AI could achieve efficient scaling under specific conditions by tailoring model and dataset proportions based on task requirements.
In testing the accuracy of the derived scaling laws, the research team trained a world-modeling agent with a model size of 894 million parameters, significantly larger than those used in prior scaling analyses. The study found a strong alignment between predictions and actual results, with the loss value closely matching computed optimal loss levels even under substantially increased compute budgets. This validation step underscored the scaling laws’ reliability, suggesting that with appropriate hyperparameter tuning, scaling laws can predict model performance effectively in complex simulations and real-world scenarios.
Key Takeaways from the Research:
- Balanced Scaling for World Modeling: For optimal performance in world modeling, both model and dataset sizes must increase proportionally.
- Behavior Cloning Optimization: Optimal configurations for behavior cloning favor smaller models paired with extensive datasets when tokenized observations are used. An increase in model size is preferred for CNN-based cloning tasks.
- Compression Rate Impact: Higher token compression rates skew scaling laws toward larger models in world modeling, indicating that tokenized data substantially affects optimal model sizes.
- Extrapolation Validation: Testing with larger models confirmed the scaling laws’ predictability, supporting these laws as a basis for efficient model sizing in embodied AI.
- Distinct Task Requirements: Scaling requirements vary significantly between behavior cloning and world modeling, highlighting the importance of customized scaling approaches for different AI tasks.

In conclusion, this study advances embodied AI by tailoring language model scaling insights to AI agent tasks. This allows researchers to predict and control resource needs more accurately. Establishing these tailored scaling laws supports the development of more efficient, capable agents in environments demanding high computational and data efficiency.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post This Machine Learning Paper Transforms Embodied AI Efficiency: New Scaling Laws for Optimizing Model and Dataset Proportions in Behavior Cloning and World Modeling Tasks appeared first on MarkTechPost.
Source: Read MoreÂ

