

The Google Cloud Speech-to-Text API is a potential solution for organizations looking to build features around Speech AI, especially for organizations that store much of their data in Google Cloud Storage (GCS) and are already deeply integrated in the Google ecosystem. This tutorial will guide you through the process of using Google Cloud’s Speech-to-Text API in your Python projects.
We will cover everything from features of the API to setting up an environment to consume it. If you want to jump directly to the code, click here.
What is the Google Cloud Speech-to-Text API?
The Google Cloud Speech-to-Text API is a service that enables developers to convert audio to text using Deep Learning models exposed through an API. Below we list some of the API’s key features, as well as some benefits and drawbacks to incorporating it into your application or workflow.
Key Features
- Support for various audio formats and languages: The API supports a wide range of audio formats and many languages and dialects (to varying degrees of accuracy and feature-completeness)
- Streaming Speech-to-Text: Google offers streaming Speech-to-Text, meaning that you can stream audio to Google and get transcription results back in real-time. This can be useful for things like live closed captioning on virtual events. Check out our related article on Streaming Speech-to-Text with Google’s API to learn more about how to implement it.
- Speaker diarization: The API can perform Speaker Diarization, distinguishing between different speakers in the audio.
- Automatic punctuation and casing: The API can automatically add punctuation and capitalization to the transcribed text.
- Word-level confidence scores: The API can provide confidence scores for each word in the transcription.
Strengths
- Pricing model: Google’s API is priced as a usage-based model, so your costs rise only with increased usage. You can use their calculator to estimate costs based on your particular needs.
- SDKs: Google offers SDKs or client libraries for many languages to make working with their API easier.
- Documentation: Google generally has good documentation that is well-synced to their product lifecycle, although it can be overwhelming given how many products they offer.
Weaknesses
- Accuracy: Google has accurate Speech-to-Text models that maintain parity with industry leaders. Check out our benchmarks page to see a detailed performance comparison for popular Speech-to-Text providers.
- Feature-completeness: While Google does offer some features for speech analysis beyond transcription, like sentiment analysis, their available models and features for Audio Intelligence and integrated LLM application do not provide the same level of feature-coverage as some other providers
- Focus: While Google has a strong AI research division, it also offers a huge range of products and services which can lead to a lack of focus in bringing these models to market, creating a feature-lag relative to other providers
- Support: Google has strong documentation, but this comes with the expectation that developers will be able to troubleshoot most problems themselves. Therefore, smaller organizations may not find the dedicated support responsiveness they want as they implement features on top of the API.
- Ecosystem-dependence: For teams not already heavily integrated into the Google ecosystem, it can be confusing and time consuming to navigate Google Cloud projects
How to use Google’s Speech-to-Text API in Python
Now it’s time to use the API to transcribe speech. Below you’ll learn how to create and set up a Google Cloud project with Speech-to-Text enabled, and then use it to transcribe both local and remote files.
Prerequisites
Before you get started, you’ll need to have Python installed on your system and a Google account, so make sure you have those set up before continuing.
Additionally, you’ll need to have the client library for Google’s Speech-to-Text API installed, as well as the requests package to make HTTP requests. Open a terminal and install those now with the below command, optionally setting up a virtual environment first if you would like to do so.
pip install google-cloud-speech requestsProject setup and authentication
Now, follow the below steps to set up a Google Cloud project that has Speech-to-Text enabled. All of the transcriptions we request will be associated with this project.
Step 1: Create a Google Cloud project
Go to the Google Cloud Console. Click on the project dropdown at the top of the page
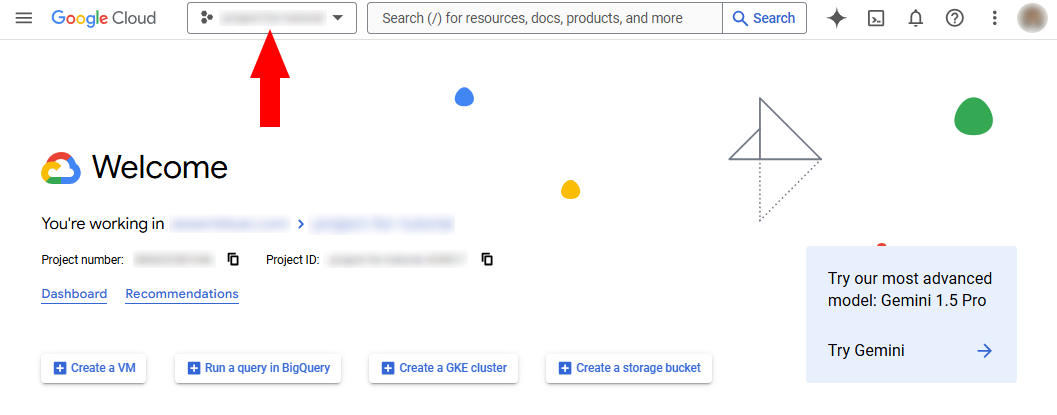
In the popup modal, select “New Project”. Enter a name for your project and click “Create”.
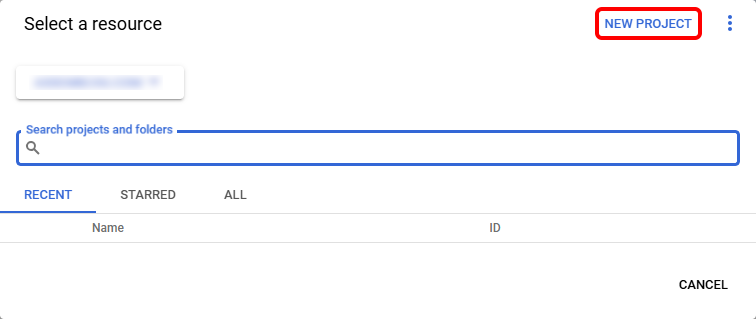
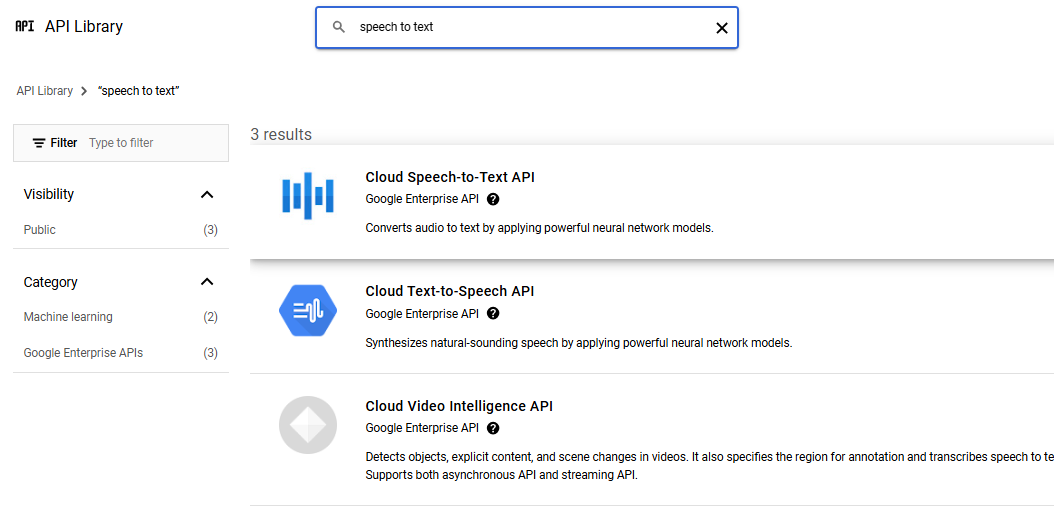
Step 2: Enable the Speech-to-Text API
Once the project is created, select it from the project dropdown at the top of the page if it is not already selected. Navigate to the API Library and search for “Speech-to-Text API”. Click on the “Speech-to-Text API” result and then click “Enable”. You may need to select your project from the dropdown if you used the previous link.
Step 3: Create a service account and generate a JSON key file
Next, you’ll create a service account. Service accounts are special Google accounts that belong to your application, rather than to an individual end user, which authenticate your application with Google Cloud services securely. By creating a service account, you can generate a key file that your application can use to authenticate API requests.
In the Google Cloud Console, navigate to the IAM & Admin section (you again may need to select your project from the dropdown if you use this link). Click on “Service Accounts” in the left-hand menu if it’s not already selected, and then click “Create Service Account” at the top of the page.
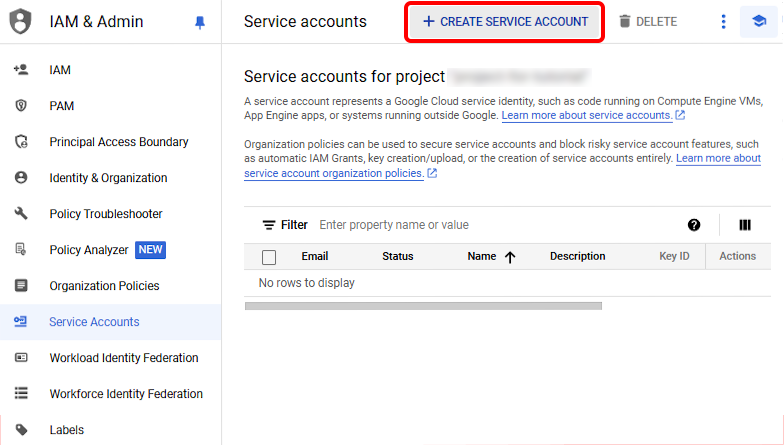
Enter a name and description for the service account, then click “Create and Continue”. You can then click “Done” to skip the two optional steps. You will be brought back to the Service Accounts overview page. Click on the service account you just created in the list, and then click on the Keys tab. Find the button that says Add Key, select it, and then click Create new key from the dropdown.
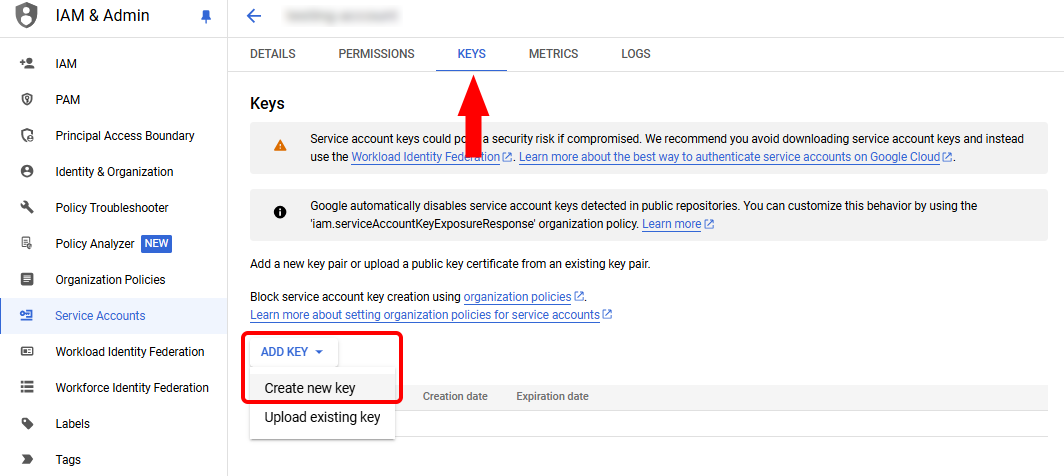
Select JSON from the options and then click Create. This will download the JSON private key to your computer. You may be presented with an additional screen notifying you of the security implications of being in possession of the private key – hit “accept” to advance. Remember to keep the private key file secret and not e.g. check it in to source control.
Step 4: Set the credentials environment variable
Next, you’ll set the GOOGLE_APPLICATION_CREDENTIALS environment variable to point to your JSON key file. Locate the JSON key file you downloaded in the previous step. Open a terminal and run the following command, replacing path/to/your/service-account-file.json with the actual path to your JSON key file:
export GOOGLE_APPLICATION_CREDENTIALS="path/to/your/service-account-file.json"To make this change permanent, you can add the above command to your shell’s startup file (e.g. ~/.bashrc).
Step 5: Initialize the Speech-to-Text client in your Python code
Now your Google Cloud project is configured with the Speech-to-Text API enabled, and your local workstation is authenticated to submit requests to the project. Next we have to write some code to submit these requests, which we’ll do now. We’ll start by showing how to transcribe remote files, and then show how to transcribe local files.
Remote file transcription with Google Speech-to-Text
First we’ll learn how to perform asynchronous transcription of a remote file. To transcribe a remote file with Google’s Speech-to-Text API, it must be stored in Google Cloud Storage (GCS). The general URL structure for these sorts of files is gs://<BUCKET_NAME>/<FILE_PATH>. We provide an example file you can use, but if you want to use your own you’ll have to create a storage bucket and upload your file.
Once you have files stored remotely in GCS, you can easily use them with Google’s Speech-to-Text API. Create a file called remote.py and add the following code:
from google.cloud import speech
def transcribe_audio_gcs(gcs_uri):
client = speech.SpeechClient()First, we import the google.cloud.speech module from the google-cloud-speech library. Then we define the transcribe_audio_gcs function, which handles the transcription itself. This function in turn creates a SpeechClient to interact with the API. Next, add the following lines to the transcribe_audio_gcs function:
audio = speech.RecognitionAudio(uri=gcs_uri)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
language_code="en-US",
)These lines instantiate both a RecognitionAudio object with the GCS URI that is passed into the function, and a RecognitionConfig object which stores the configuration we want to use for the transcription. In this case, we specify the audio encoding as Linear PCM (LINEAR16), and the language of the audio via it’s language code – in this case, US English. Next, add the following lines to transcribe_audio_gcs:
response = client.recognize(config=config, audio=audio)
print("Transcript: {}".format(response.results[0].alternatives[0].transcript))The first line uses the client.recognize method to submit the file for transcription.
This call returns a RecognizeResponse object, which we store in the response variable. From this object, we extract the first element of the results list, which corresponds to the transcript for our first (in this case only) audio file. This element in turn contains an alternatives list with different possible transcriptions, ordered by accuracy. You can set the number of alternative transcriptions returned via the max_alternatives parameter of the RecognitionConfig. The default is one, so we extract this element from the list, and then access the transcript attribute to finally print off the transcript.
Lastly, add the following lines to the bottom of remote.py to set the GCS URI of the file we want to transcribe and pass it into the transcribe_audio_gcs function:
if __name__ == "__main__":
gcs_uri = 'gs://aai-web-samples/gettysburg.wav'
transcribe_audio_gcs(gcs_uri)Run python remote.py in the terminal to execute this script. Make sure to do so in the same terminal where you set the GOOGLE_APPLICATION_CREDENTIALS environment variable. After a short wait, you’ll see the following results printed to the terminal:
Transcript: 4 score and 7 years ago our fathers brought forth on this continent a new nation conceived in liberty and dedicated to the proposition that all men are created equalNote that for files that are not WAV or FLAC, you need to specify the sample rate of the file via the sample_rate_hertz parameter in the speech.RecognitionConfig.
Google recommends a sampling rate of 16 kHz, but if this is not possible to use the native sample rate of the audio source rather than attempting to resample.
Local file transcription with Google Speech-to-Text
It’s also possible to transcribe a local audio file with Google’s Speech-to-Text API, let’s do that now. Create a file called local.py and add the following code:
from google.cloud import speech
def transcribe_audio_local(file_path):
client = speech.SpeechClient()
with open(file_path, 'rb') as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
language_code="en-US",
)
response = client.recognize(config=config, audio=audio)
for result in response.results:
print("Transcript: {}".format(result.alternatives[0].transcript))
if __name__ == "__main__":
file_path = 'file.wav'
transcribe_audio_local(file_path)The contents of transcribe_audio_local are almost identical to those of transcribe_audio_gcs, except for these lines:
with open(file_path, 'rb') as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)These lines open and read the bytes of the audio file, and then pass them into the speech.RecognitionAudio constructor via the content parameter, rather than the uri parameter as above.
Currently, the script will work if you place a file.wav file in the project directory and run python local.py, but let’s add the ability to download a remote file. This will allow us to transcribe remote files that are not in GCS (but still have a public download link). Add the following function and modify the __main__ block:
import requests
from google.cloud import speech
def download_audio(url, file_path):
response = requests.get(url)
with open(file_path, 'wb') as f:
f.write(response.content)
print(f"Audio file downloaded and saved as '{file_path}'")
# ...
if __name__ == "__main__":
url = 'https://storage.googleapis.com/aai-web-samples/gettysburg.wav'
file_path = 'file.wav'
download_audio(url, file_path)
transcribe_audio_local(file_path)These lines add a function to download a remote audio file and write it locally to disk, and modify the __main__ block to call this function with the file we used in the previous section. Now if you run python local.py, you will see the following output in the terminal:
Audio file downloaded and saved as 'file.wav'
Transcript: 4 score and 7 years ago our fathers brought forth on this continent a new nation conceived in liberty and dedicated to the proposition that all men are created equalNote that, as mentioned in the last section, you need to specify the sample rate of the file via the sample_rate_hertz parameter in the speech.RecognitionConfig for audio files that are not WAV or FLAC.
Conclusion
In this tutorial, we covered the basics of using the Google Cloud Speech-to-Text API in Python, including setting up a Google Cloud project, authenticating your application, and performing remote and local asynchronous transcriptions. For more information on advanced features like speaker diarization and profanity filtering, refer to the Google Cloud Speech-to-Text documentation.
You can perform Speech-to-Text with no project setup in a few lines of code with our API:
import assemblyai as aai
aai.settings.api_key = "YOUR_API_KEY"
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("https://assembly.ai/sports_injuries.mp3")
print(transcript.text)Check out our Docs to learn more.
For inspiration on features you can build on top of Speech-to-Text and SpeechAI more widely, check out our YouTube channel. There you’ll find AI deep-dives, how-to tutorials for popular frameworks, and walkthroughs on building features on top of SpeechAI, like this video on automatically extracting phone call insights using LLMs:
Source: Read MoreÂ

