


Retrieval-augmented generation (RAG) has been shown to improve knowledge capabilities and reduce the hallucination problem of LLMs. The Web is a major source of external knowledge used in RAG and many commercial systems such as ChatGPT. However, current RAG implementations face a fundamental challenge in their knowledge-processing approach. The conventional method of converting HTML documents into plain text before feeding them to LLMs results in a substantial loss of structural and semantic information. This limitation becomes evident when dealing with complex web content like tables, where the conversion process disrupts the original format and discards crucial HTML tags that carry important contextual information.
The existing methods to enhance RAG systems have focused on various components and frameworks. Traditional RAG pipelines use elements like query rewriters, retrievers, re-rankers, refiners, and readers, as implemented in frameworks like LangChain and LlamaIndex. The Post-retrieval processing method is explored through chunking-based and abstractive refiners to optimize the content sent to LLMs. Moreover, research in structured data understanding has demonstrated the superior information richness of HTML and Excel tables compared to plain text. However, these existing solutions face limitations when dealing with HTML content, as traditional chunking methods cannot effectively handle HTML structure, and abstractive refiners struggle with long HTML content and have high computational costs.
Researchers from the Gaoling School of Artificial Intelligence, Renmin University of China, and Baichuan Intelligent Technology, China have proposed HtmlRAG, a method that uses HTML instead of plain text as the format of retrieved knowledge in RAG systems to preserve richer semantic and structured information that is missing in plain text. This method utilizes recent advances in LLMs’ context window capabilities and the versatility of HTML as a format that can accommodate various document types like LaTeX, PDF, and Word with minimal information loss. Moreover, the researchers identified significant challenges in implementing this approach, particularly the extensive token length of raw HTML documents and the presence of noise in the CSS styles, JavaScript, and comments format, which comprise over 90% of the tokens.
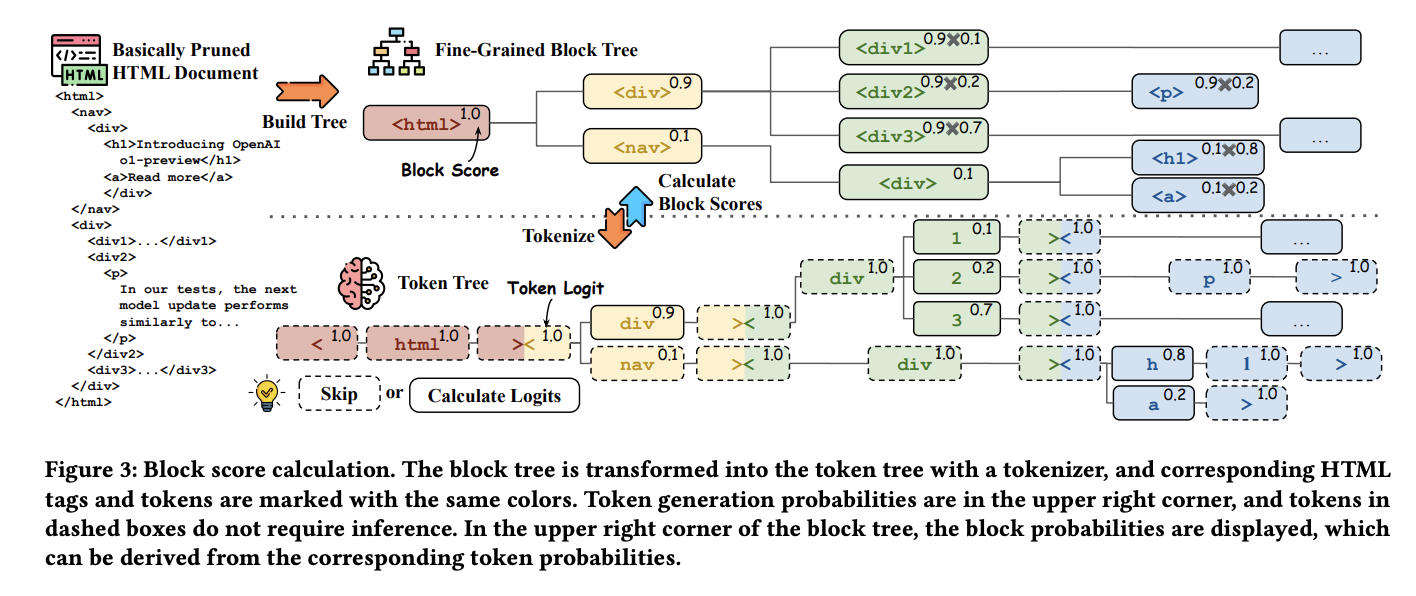
HtmlRAG implements a two-step pruning mechanism to process retrieved HTML documents efficiently. Initially, the system concatenates all retrieved HTML documents and parses them into a single DOM tree using Beautiful Soup. To address the computational challenges posed by the fine-grained nature of traditional DOM trees, the researchers developed an optimized “block tree†structure. This approach allows for adjustable granularity controlled by a maxWords parameter. Moreover, the block tree construction process recursively merges fragmented child nodes into their parent nodes, creating larger blocks while maintaining the word limit constraint. The pruning process then operates in two distinct phases: the first utilizes an embedding model to process the cleaned HTML output, followed by a generative model for further refinement.
The results show HtmlRAG’s superior performance across six datasets outperforming baseline methods in all evaluation metrics. The results show limited utilization of structural information compared to HtmlRAG while examining chunking-based refiners that follow LangChain’s approach. Among re-rankers, dense retrievers outperformed the sparse retriever BM25, with the encoder-based BGE showing better results than the decoder-based e5-mistral. Moreover, the abstractive refiners show notable limitations: LongLLMLingua struggles with HTML document optimization and lost structural information in plain text conversion, while JinaAI-reader, despite generating refined Markdown from HTML input, faced challenges with token-by-token decoding and high computational demands for long sequences.
In conclusion, researchers have introduced an approach called HtmlRAG that uses HTML as the format of retrieved knowledge in RAG systems to preserve rich semantic and structured information not present in plain text. The implemented HTML cleaning and pruning techniques effectively manage token length while preserving essential structural and semantic information. HtmlRAG’s superior performance compared to traditional plain-text-based post-retrieval processes validates the effectiveness of utilizing HTML format for knowledge retrieval. The researchers provide an immediate practical solution and establish a promising new direction for future developments in RAG systems, encouraging further innovations in HTML-based knowledge retrieval and processing methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post HtmlRAG: Enhancing RAG Systems with Richer Semantic and Structural Information through HTML appeared first on MarkTechPost.
Source: Read MoreÂ

