




In today’s world, Graph similarity computation (GSC) plays an important role in various applications such as code detection, molecular graph similarity, image matching, etc., by evaluating the similarity between two graphs, and it is based on Graph similarity learning. Graph Edit Distance (GED) and Maximum Common Subgraph (MCS) are widely used to measure graph similarity. GED refers to the minimum number of operations that convert one graph to the other, and MCS is the largest subgraph that is simultaneously isomorphic(structurally identical) to both graphs. However, calculating GED and MCS is difficult because of problems that belong to a category called NP-complete, meaning they are extremely hard to solve efficiently, especially as the graphs get larger. Traditional algorithms like Hungar and A* can compute GED accurately but at the cost of high computational complexity. Computing graph similarity scores accurately is important, as this can significantly impact its applications.Â
The existing methods to compute graph similarity have two major drawbacks:
1. Representation limitation: A comprehensive representation enables matching from multiple perspectives. Most methods only use simple node embeddings without highlighting the edge representation, which is crucial for accurately comparing structures.
2. Matching inadequacy:Â Some recent GSC methods use Graph neural networks (GNNs) to take advantage of intra-graph structures in message passing. However, most of them need to fully utilize the information presented by edges to boost the representation of the connected nodes. Moreover, previous cross-graph node embedding matching needs to include the bigger picture of the overall structure of the graph pair because the node representations from GNNs only focus on the intra-graph structure, causing an unreasonable similarity score.
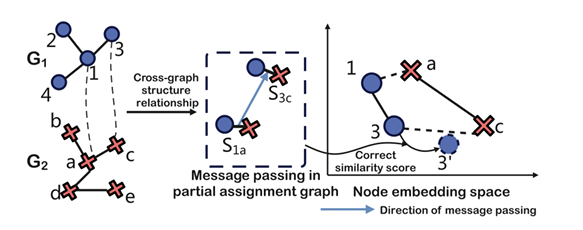
To overcome the drawbacks of previous works, researchers from Nanjing University of Posts and Telecommunications proposed a Structure Enhanced Graph Matching Network (SEGMN) framework. Equipped with a dual embedding learning module and a structure perception matching module, SEGMN achieves structure enhancement in both embedding learning and cross-graph matching. This proposed framework consists of four modules: Dual embedding learning, Cross-graph interaction, Structure perception matching, and Similarity matrix learning.
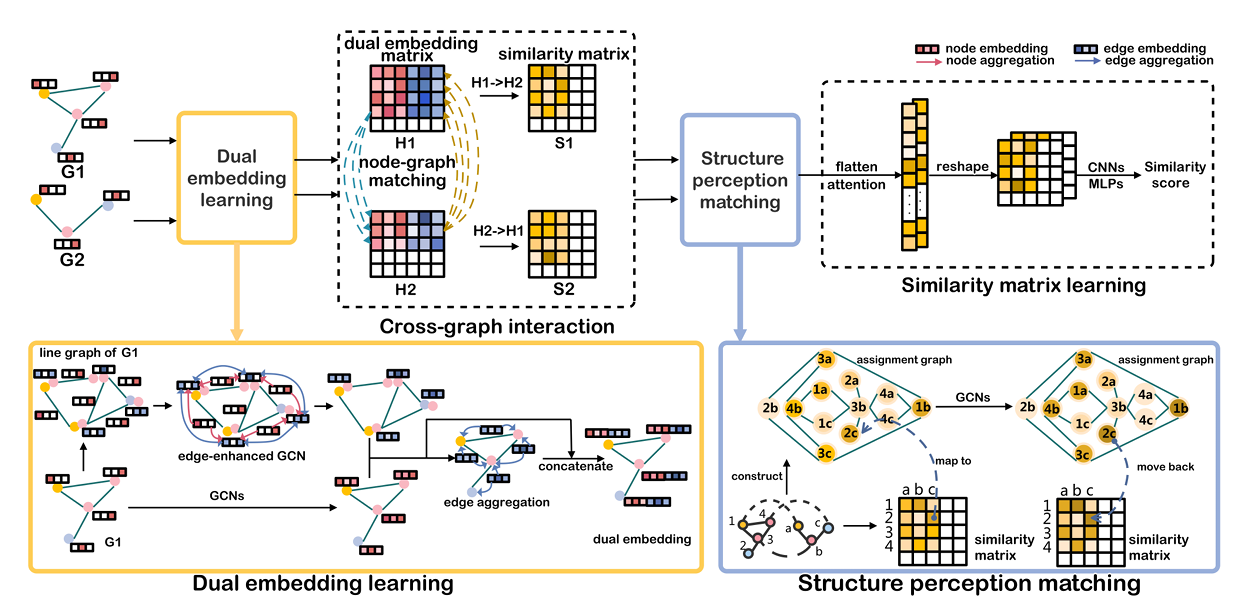
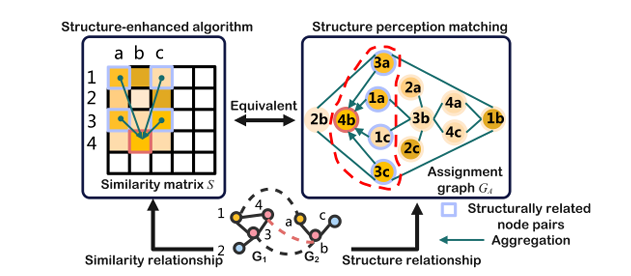
The dual embedding learning module can be divided into three steps. An edge-enhanced GCN is applied to the line graph for edge embedding. Secondly, a GCN with residual connections is applied to the node graph for embedding. Thirdly, each node aggregates the connected edge embeddings to generate the ultimate dual embedding. This dual embedding is used for cross-graph matching on the node level, where node-graph attention is adopted to calculate each node pair’s similarity score. The structure perception matching improves these scores by considering the structural relationships between node pairs across graphs. Finally, the similarity matrix is refined using convolution and self-attention to produce accurate similarity scores, with a loss function based on Mean Squared Error to optimize the model’s predictions.
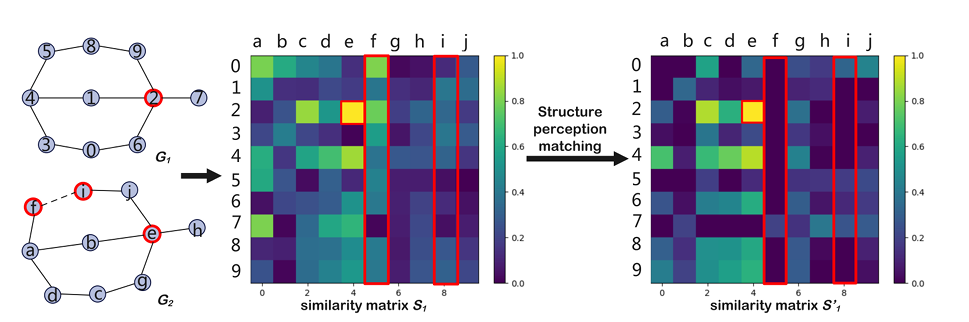
Researchers evaluated SEGMN using three benchmark real-world datasets: AIDS, LINUX, and IMDB, and compared it to other groups of baselines such as GCN, GIN, GAT, SimGNN, and GraphSim. Upon evaluation, the proposed method outperformed other models in terms of Mean Square Error (MSE), Spearman’s Rank Correlation (Ï), Kendall’s Tau (Ï„), and precision at top 10 (p@10), with the structure perception matching module further improving performance by up to 25%.
In conclusion, the proposed framework is based on a dual embedding learning module and a structure-matching perception module, which perform better than traditional methods and mitigate their issues. It also offers a robust solution for graph similarity computation by providing a strong way to calculate it more accurately. This research marks an essential step toward understanding graph similarity computation and can serve as a baseline for future research in this domain!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post From Edges to Nodes: SEGMN’s Comprehensive Approach to Graph Similarity appeared first on MarkTechPost.
Source: Read MoreÂ