


Automatic differentiation has transformed the development of machine learning models by eliminating complex, application-dependent gradient derivations. This transformation helps to calculate  Jacobian-vector and vector-Jacobian products without creating the full Jacobian matrix, which is crucial for tuning scientific and probabilistic machine learning models. Otherwise, it would require a column for each neural network parameter. Nowadays, everyone can build algorithms around matrices of large sizes by exploiting this matrix-free approach. However, differentiable linear algebra for Jacobian-vector products and similar operations has remained largely unexplored to this day and traditional methods also have some flaws.
Current methods for evaluating functions of large matrices mainly rely on Lanczos and Arnoldi iterations, which require good computation power and are not optimized for differentiation. Generative models depended primarily on the change-of-variables formula, which involves the log-determinant of the Jacobian matrix of a neural network. To optimize model parameters in Gaussian processes, it is important to calculate gradients of log-probability functions that involve many large covariance matrices. Using methods that combine random trace estimation with the Lanczos iteration helps to increase the speed of convergence. Some of the recent work uses some combination of stochastic trace estimation with the Lanczos iteration and agrees on gradients of log determinants. Unlike in Gaussian processes, prior work on Laplace approximations tries to simplify the Generalized Gauss-Newton (GGN) matrix by using only certain groups of network weights or by various algebraic techniques like diagonal or low-rank approximations. These methods make it easy to compute log determinants automatically, but they lose important details about the correlation between weights.Â
To mitigate these challenges and as a step towards the exploration of differentiable linear algebra, researchers proposed a new matrix-free method for automatically differentiating functions of matrices.Â
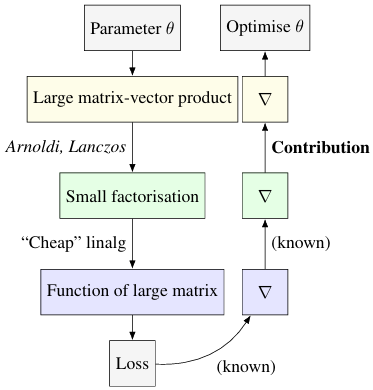
A group of researchers from the Technical University of Denmark and Kongens Lyngby, Denmark, conducted detailed research and derived previously unknown adjoint systems for Lanczos and Arnoldi iterations, implementing them in JAX, and showed that the resulting code could compete with Diffrax when it comes to differentiating PDEs, GPyTorch for selecting Gaussian process models. Also, it beats standard factorization methods for calibrating Bayesian neural networks.Â
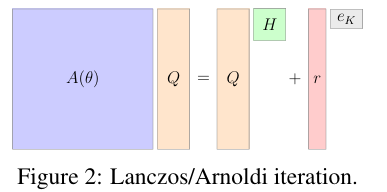
In this, the researchers primarily focused on matrix-free algorithms that avoid direct matrix storage and instead operate via matrix-vector products. The Lanczos and Arnoldi iterations are popular for matrix decomposition in a matrix-free manner, which produces smaller and structured matrices that approximate the large matrix, making it easy to evaluate matrix functions. The proposed method can efficiently find the derivatives of functions related to large matrices without creating the entire Jacobian matrix. This matrix-free approach evaluates Jacobian-vector and vector-Jacobian products, making it suitable for large-scale machine-learning models. Also, the implementation in JAX ensures high performance and scalability.Â
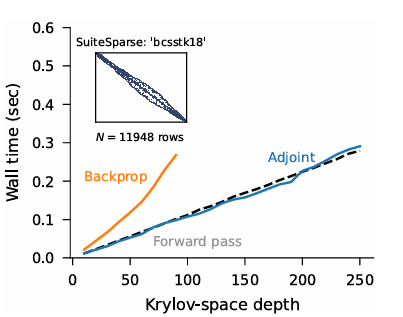
The method is similar to the adjoint method, and this new algorithm is faster than backpropagation and shares the same stability benefits as the original calculations. The code was tested on three complex machine-learning problems to see how it compares with current methods for Gaussian processes, differential equation solvers, and Bayesian neural networks. The findings conducted by the researchers show that the integration of Lanczos iterations and Arnoldi methods greatly enhances efficiency and accuracy in machine learning, which unlocks new training, testing, and calibration techniques and highlights how important advanced math techniques are for making machine learning models work better in different areas.
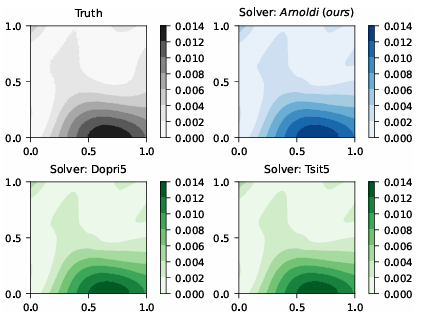
In conclusion, the proposed method mitigates problems that the traditional method faces and does not require creating large matrices to find the differences in functions. Also, it addresses and solves the computing difficulties of existing methods and enhances the efficiency and accuracy of probabilistic machine learning models. Still, there are certain limitations to this method, such as challenges with forward-mode differentiation and the assumption that the orthogonalized matrix can fit in memory. Future work may extend this framework by addressing these constraints and exploring applications in various fields, especially in Machine learning, which may require adaptations for complex-valued matrices!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post Matrix-Free Differentiation: Advancing Probabilistic Machine Learning appeared first on MarkTechPost.
Source: Read MoreÂ

