")


Quantization is an essential technique in machine learning for compressing model data, which enables the efficient operation of large language models (LLMs). As the size and complexity of these models expand, they increasingly demand vast storage and memory resources, making their deployment a challenge on limited hardware. Quantization directly addresses these challenges by reducing the memory footprint of models, making them accessible for more diverse applications, from complex natural language processing to high-speed scientific modeling. Specifically, post-training quantization (PTQ) compresses model weights without requiring retraining, offering a memory-efficient solution crucial for scalable and cost-effective deployments.
A significant problem with LLMs lies in their high storage demands, which limits their practical application on constrained hardware systems. Large models, such as LLMs exceeding 200GB, can quickly overwhelm memory bandwidth, even in high-capacity GPUs. Current PTQ techniques like vector quantization (VQ) rely on codebooks with multiple vectors to represent model data efficiently. However, traditional VQ methods have a significant drawback: they need exponential memory to store and access these codebooks. This dependence limits the scalability of VQ for high-dimensional data, leading to slower inference speeds and suboptimal performance, especially when real-time response is essential.
Existing quantization methods, including QuIP# and AQLM, aim to reduce data representation by compressing weights into 2-bit or 4-bit models through VQ techniques. By quantizing each vector dimension into a high-density codebook, VQ can optimize the model’s size while preserving data integrity. However, the codebooks required for high-dimensional vectors often exceed practical cache limits, causing bottlenecks in memory access. For example, the 8-dimensional codebooks AQLM uses occupy around 1MB each, making storing them in high-speed caches difficult, severely limiting VQ’s overall inference speed and scalability.
Researchers from Cornell University introduced the Quantization with Trellis and Incoherence Processing (QTIP) method. QTIP offers an alternative to VQ by applying trellis-coded quantization (TCQ), which efficiently compresses high-dimensional data using a hardware-efficient “bitshift†trellis structure. QTIP’s design separates codebook size from the bitrate, allowing ultra-high-dimensional quantization without incurring the memory costs typical of VQ. This innovative design combines trellis coding with incoherence processing, resulting in a scalable and practical solution that supports fast, low-memory quantization for LLMs. With QTIP, researchers can achieve state-of-the-art compression while minimizing the operational bottlenecks that typically arise from codebook size limitations.
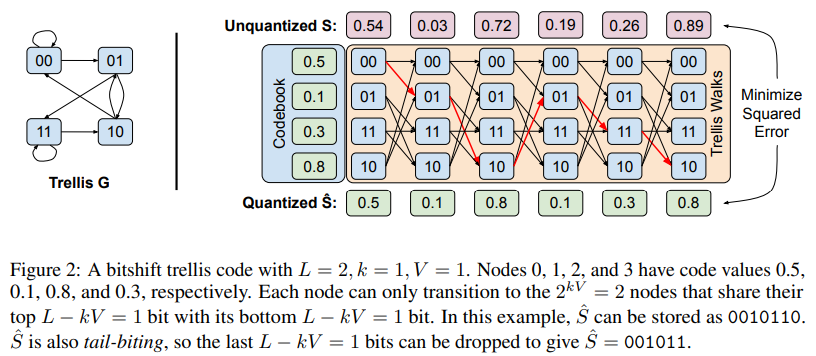
The QTIP structure leverages a bitshift trellis, enabling high-dimensional quantization while reducing memory access demands. This method uses a trellis-coded quantizer that eliminates the need to store a full codebook by generating random Gaussian values directly in memory, significantly enhancing data efficiency. Also, QTIP employs incoherence processing through a random Hadamard transformation that ensures weight data resembles Gaussian distributions, a process that reduces data storage costs and allows for fast inference speeds. By managing quantized data efficiently, QTIP achieves excellent performance without requiring large memory caches, making it adaptable to various hardware configurations.
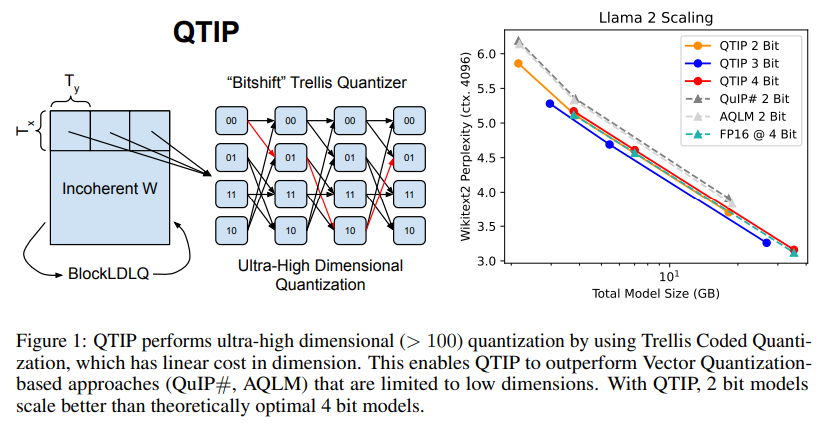
Performance evaluations of QTIP show that it achieves notable gains over traditional methods, delivering higher accuracy with faster processing times across different hardware setups. In tests involving Llama 2 model quantization, QTIP produced better compression quality at 2-bit and 3-bit settings, surpassing state-of-the-art results achieved by VQ-based QuIP# and AQLM. On a Wikitext2 evaluation, QTIP attained a 5.12 perplexity score in 4-bit mode, outperforming both QuIP# and AQLM without additional fine-tuning, which is a crucial advantage when real-time adaptability is required. Notably, QTIP’s efficient code-based approach requires as few as two hardware instructions per weight, enabling faster decoding speeds while maintaining model accuracy, even with models like Llama 3.1, where traditional quantization methods struggle.
QTIP’s flexibility in adapting to various hardware environments further highlights its potential. Designed for compatibility with cache-limited and parallel-processing devices, QTIP leverages the bitshift trellis to process quantized data efficiently on GPUs and other devices like ARM CPUs. For example, QTIP achieves high processing speeds on GPUs while maintaining a high-dimensional quantization of 256 dimensions, a feature that no other PTQ method currently supports without compromising speed. Its ability to maintain compression quality at ultra-high dimensions is a notable advancement, especially in large-scale deployment needs in LLM inference tasks.
QTIP sets a new standard in quantization efficiency for large language models. Using trellis-coded quantization paired with incoherence processing, QTIP enables high-dimensional compression with minimal hardware requirements, ensuring large-scale models can perform inference quickly and precisely. Compared to VQ-based methods, QTIP achieves significant compression rates without needing large codebooks or fine-tuning adjustments, making it highly adaptable for different types of machine learning infrastructure.
Key Takeaways from QTIP Research:
- Improved Compression Efficiency: Achieves superior model compression with state-of-the-art quantization quality, even in high-dimensional settings.
- Minimal Memory Requirements: Requires only two instructions per weight, significantly reducing memory demands and accelerating processing speeds.
- Enhanced Adaptability: QTIP’s trellis-coded quantization can be efficiently processed on GPUs and ARM CPUs, making it versatile for varied hardware environments.
- Higher-Quality Inference: Outperforms QuIP# and AQLM in inference accuracy across various model sizes, including the Llama 3 and Llama 2 models.
- Ultra-High-Dimensional Quantization: Successfully operates with 256-dimensional quantization, exceeding the practical limits of vector quantization.

In conclusion, QTIP presents an innovative solution to large language models’ scalability and memory demands, offering efficient quantization without sacrificing speed or accuracy. By addressing the core challenges of traditional quantization methods, QTIP holds significant promise for enhancing the performance and accessibility of complex machine learning models across a range of hardware configurations.
Check out the Paper and Models on HuggingFace. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post Cornell Researchers Introduce QTIP: A Weight-Only Post-Training Quantization Algorithm that Achieves State-of-the-Art Results through the Use of Trellis-Coded Quantization (TCQ) appeared first on MarkTechPost.
Source: Read MoreÂ

