


Large language models (LLMs) rely on deep learning architectures that capture complex linguistic relationships within layered structures. Primarily based on Transformer architectures, these models are increasingly deployed across industries for tasks that require nuanced language understanding and generation. However, the demands of large Transformer models come with steep computational and memory requirements. As models grow to billions of parameters, their deployment on standard hardware becomes challenging due to processing power and memory capacity limitations. To make LLMs feasible and accessible for broader applications, researchers are pursuing optimizations that balance model performance with resource efficiency.
LLMs typically require extensive computational resources and memory, making them costly to deploy and difficult to scale. One of the critical issues in this area is reducing the resource burden of LLMs while preserving their performance. Researchers are investigating methods for minimizing model parameters without impacting accuracy, with parameter sharing being one approach under consideration. Model weights are reused across multiple layers in parameter sharing, theoretically reducing the model’s memory footprint. However, this method has had limited success in modern LLMs, where layer complexity can cause shared parameters to degrade performance. Reducing parameters effectively without loss in model accuracy has thus become a significant challenge as models become highly interdependent within their layers.
Researchers have explored techniques already used in parameter reduction, such as knowledge distillation and pruning. Knowledge distillation transfers the performance of a larger model to a smaller one, while pruning eliminates less influential parameters to reduce the model’s size. Despite their advantages, these techniques can fail to achieve the desired efficiency in large-scale models, particularly when performance at scale is essential. Another approach, low-rank adaptation (LoRA), adjusts the model structure to attain similar outcomes but does not always yield the efficiency necessary for broader applications.
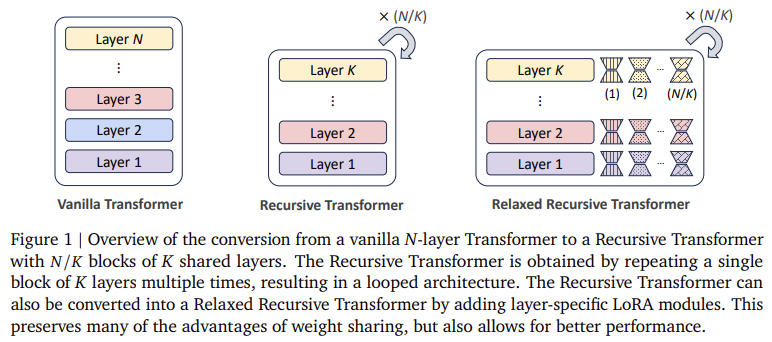
The researchers from KAIST AI, Google DeepMind, and Google Research introduced Relaxed Recursive Transformers to overcome these limitations. This architecture builds on traditional Transformers by implementing parameter sharing across layers through recursive transformations supported by LoRA modules. The Recursive Transformer architecture operates by reusing a unique block of layers multiple times in a loop, retaining performance benefits while decreasing the computational burden. Researchers demonstrated that by looping the same layer block and initializing it from a standard pretrained model, Recursive Transformers could reduce parameters while maintaining accuracy and optimizing model resource use. This configuration further introduces Relaxed Recursive Transformers by adding low-rank adaptations to loosen the strict parameter-sharing constraints, allowing more flexibility and refined performance in the shared structure.
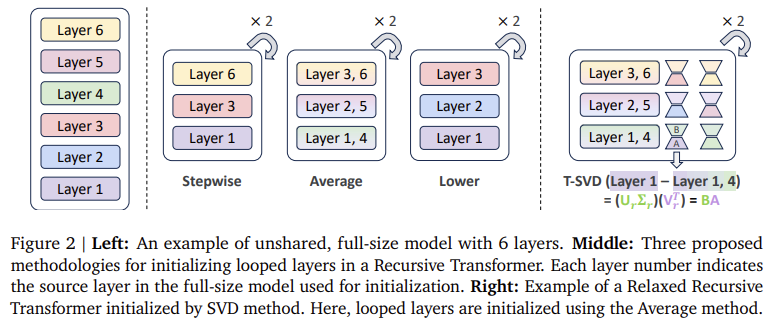
The Relaxed Recursive Transformer’s design hinges on integrating LoRA modules customized for each layer, allowing the model to function at reduced parameter counts without compromising accuracy. Each layer block is initialized using Singular Value Decomposition (SVD) techniques, which ensure the model’s layers can operate effectively at a compressed scale. Recursive models such as the Gemma 1B model, which use this design, have been shown to outperform non-recursive counterparts of a similar size, like the TinyLlama 1.1B and Pythia 1B, by achieving higher accuracy in few-shot tasks. This architecture further allows Recursive Transformers to leverage early-exit mechanisms, enhancing inference throughput by up to 3x compared to traditional LLMs due to its recursive design.
The results reported in the study show that Recursive Transformers achieve notable gains in efficiency and performance. For example, the recursive Gemma 1B model demonstrated a 10-percentage-point accuracy gain over reduced-size models trained on the same dataset. The researchers report that by using early-exit strategies, the Recursive Transformer achieved nearly 3x speed improvements in inference, as it allows depth-wise batching. Also, the recursive models performed competitively with larger models, reaching performance levels comparable to non-recursive models pretrained on substantially larger datasets, with some recursive models nearly matching models trained on corpora exceeding three trillion tokens.

Key Takeaways from the Research:
- Efficiency Gains: Recursive Transformers achieved up to 3x improvements in inference throughput, making them significantly faster than standard Transformer models.
- Parameter Sharing: Parameter sharing with LoRA modules allowed models like the Gemma 1B to achieve nearly ten percentage points higher accuracy over reduced-size models without losing effectiveness.
- Enhanced Initialization: Singular Value Decomposition (SVD) initialization was used to maintain performance with reduced parameters, providing a balanced approach between fully shared and non-shared structures.
- Accuracy Maintenance: Recursive Transformers sustained high accuracy even when trained on 60 billion tokens, achieving competitive performance against non-recursive models trained on far larger datasets.
- Scalability: The recursive transformer models present a scalable solution by integrating recursive layers and early-exit strategies, facilitating broader deployment without demanding high-end computational resources.

In conclusion, Relaxed Recursive Transformers offer a novel approach to parameter efficiency in LLMs by leveraging recursive layer sharing supported by LoRA modules, preserving both memory efficiency and model effectiveness. By optimizing parameter-sharing techniques with flexible low-rank modules, the team presented a high-performing, scalable solution that makes large-scale language models more accessible and feasible for practical applications. The research presents a viable path for improving cost and performance efficiency in deploying LLMs, especially where computational resources are limited.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post Relaxed Recursive Transformers with Layer-wise Low-Rank Adaptation: Achieving High Performance and Reduced Computational Cost in Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ
