
Intelligent document processing (IDP) is a technology to automate the extraction, analysis, and interpretation of critical information from a wide range of documents. By using advanced machine learning (ML) and natural language processing algorithms, IDP solutions can efficiently extract and process structured data from unstructured text, streamlining document-centric workflows.
When enhanced with generative AI capabilities, IDP enables organizations to transform document workflows through advanced understanding, structured data extraction, and automated classification. Generative AI-powered IDP solutions can better handle the variety of documents that traditional ML models might not have seen before. This technology combination is impactful across multiple industries, including child support services, insurance, healthcare, financial services, and the public sector. Traditional manual processing creates bottlenecks and increases error risk, but by implementing these advanced solutions, organizations can dramatically enhance their document workflow efficiency and information retrieval capabilities. AI-enhanced IDP solutions improve service delivery while reducing administrative burden across diverse document processing scenarios.
This approach to document processing provides scalable, efficient, and high-value document processing that leads to improved productivity, reduced costs, and enhanced decision-making. Enterprises that embrace the power of IDP augmented with generative AI can benefit from increased efficiency, enhanced customer experiences, and accelerated growth.
In the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey.
Benefits of Amazon Bedrock Data Automation
Amazon Bedrock Data Automation introduces several features that significantly improve the scalability and accuracy of IDP solutions:
- Confidence scores and bounding box data – Amazon Bedrock Data Automation provides confidence scores and bounding box data, enhancing data explainability and transparency. With these features, you can assess the reliability of extracted information, resulting in more informed decision-making. For instance, low confidence scores can signal the need for additional human review or verification of specific data fields.
- Blueprints for rapid development – Amazon Bedrock Data Automation provides pre-built blueprints that simplify the creation of document processing pipelines, helping you develop and deploy solutions quickly. Amazon Bedrock Data Automation provides flexible output configurations to meet diverse document processing requirements. For simple extraction use cases (OCR and layout) or for a linearized output of the text in documents, you can use standard output. For customized output, you can start from scratch to design a unique extraction schema, or use preconfigured blueprints from our catalog as a starting point. You can customize your blueprint based on your specific document types and business requirements for more targeted and accurate information retrieval.
- Automatic classification support – Amazon Bedrock Data Automation splits and matches documents to appropriate blueprints, resulting in precise document categorization. This intelligent routing alleviates the need for manual document sorting, drastically reducing human intervention and accelerating processing time.
- Normalization – Amazon Bedrock Data Automation addresses a common IDP challenge through its comprehensive normalization framework, which handles both key normalization (mapping various field labels to standardized names) and value normalization (converting extracted data into consistent formats, units, and data types). This normalization approach helps reduce data processing complexities, so organizations can automatically transform raw document extractions into standardized data that integrates more smoothly with their existing systems and workflows.
- Transformation – The Amazon Bedrock Data Automation transformation feature converts complex document fields into structured, business-ready data by automatically splitting combined information (such as addresses or names) into discrete, meaningful components. This capability simplifies how organizations handle varied document formats, helping teams define custom data types and field relationships that match their existing database schemas and business applications.
- Validation – Amazon Bedrock Data Automation enhances document processing accuracy by using automated validation rules for extracted data, supporting numeric ranges, date formats, string patterns, and cross-field checks. This validation framework helps organizations automatically identify data quality issues, trigger human reviews when needed, and make sure extracted information meets specific business rules and compliance requirements before entering downstream systems.
Solution overview
The following diagram shows a fully serverless architecture that uses Amazon Bedrock Data Automation along with AWS Step Functions and Amazon Augmented AI (Amazon A2I) to provide cost-effective scaling for document processing workloads of different sizes.
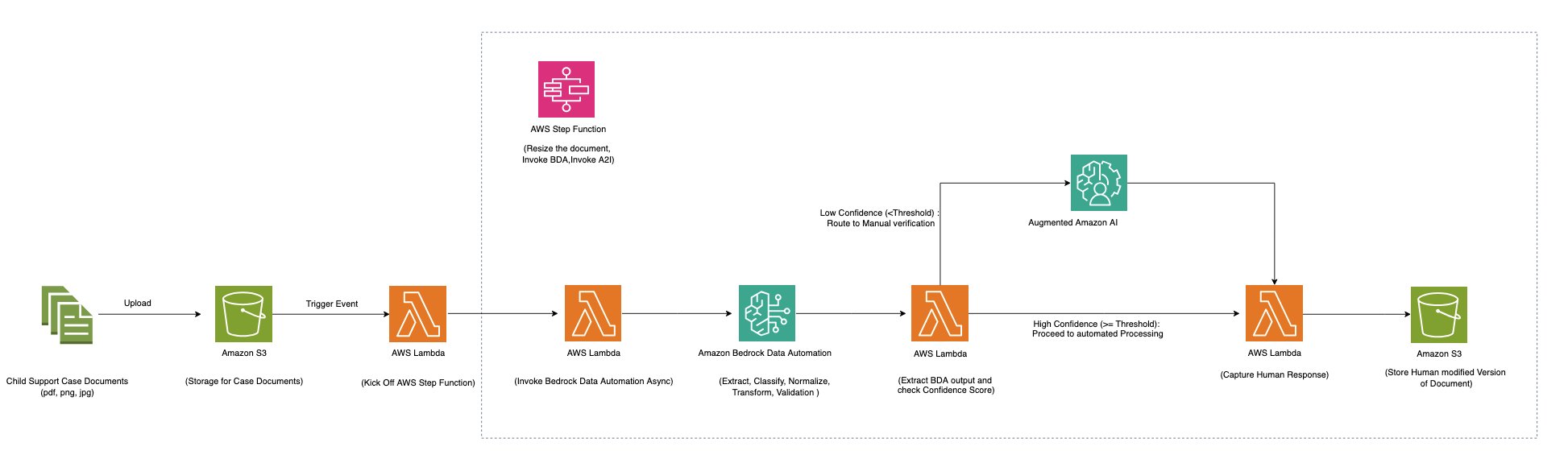
The Step Functions workflow processes multiple document types including multipage PDFs and images using Amazon Bedrock Data Automation. It uses various Amazon Bedrock Data Automation blueprints (both standard and custom) within a single project to enable processing of diverse document types such as immunization documents, conveyance tax certificates, child support services enrollment forms, and driver licenses.
The workflow processes a file (PDF, JPG, PNG, TIFF, DOC, DOCX) containing a single document or multiple documents through the following steps:
- For multi-page documents, splits along logical document boundaries
- Matches each document to the appropriate blueprint
- Applies the blueprint’s specific extraction instructions to retrieve information from each document
- Perform normalization, Transformation and validation on extracted data according to the instruction specified in blueprint
The Step Functions Map state is used to process each document. If a document meets the confidence threshold, the output is sent to an Amazon Simple Storage Service (Amazon S3) bucket. If any extracted data falls below the confidence threshold, the document is sent to Amazon A2I for human review. Reviewers use the Amazon A2I UI with bounding box highlighting for selected fields to verify the extraction results. When the human review is complete, the callback task token is used to resume the state machine and human-reviewed output is sent to an S3 bucket.
To deploy this solution in an AWS account, follow the steps provided in the accompanying GitHub repository.
In the following sections, we review the specific Amazon Bedrock Data Automation features deployed using this solution, using the example of a child support enrollment form.
Automated Classification
In our implementation, we define the document class name for each custom blueprint created, as illustrated in the following screenshot. When processing multiple document types, such as driver’s licenses and child support enrollment forms, the system automatically applies the appropriate blueprint based on content analysis, making sure the correct extraction logic is used for each document type.

Data Normalization
We use data normalization to make sure downstream systems receive uniformly formatted data. We use both explicit extractions (for clearly stated information visible in the document) and implicit extractions (for information that needs transformation). For example, as shown in the following screenshot, dates of birth are standardized to YYYY-MM-DD format.

Similarly, format of Social Security Numbers is changed to XXX-XX-XXXX.
Data Transformation
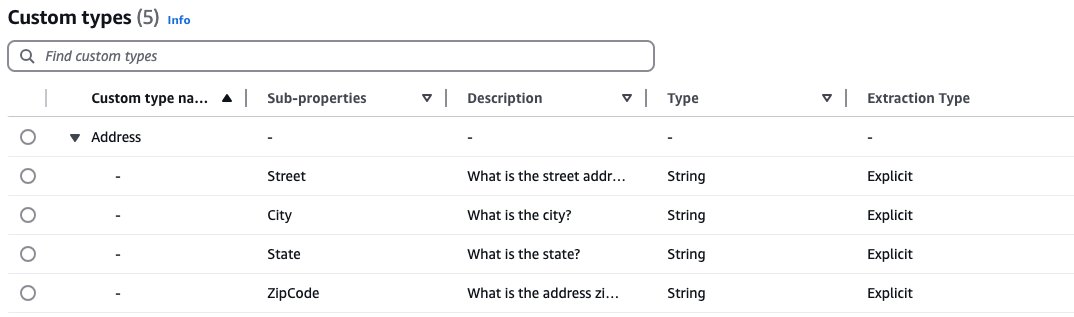
For the child support enrollment application, we’ve implemented custom data transformations to align extracted data with specific requirements. One example is our custom data type for addresses, which breaks down single-line addresses into structured fields (Street, City, State, ZipCode). These structured fields are reused across different address fields in the enrollment form (employer address, home address, other parent address), resulting in consistent formatting and straightforward integration with existing systems.
Data Validation
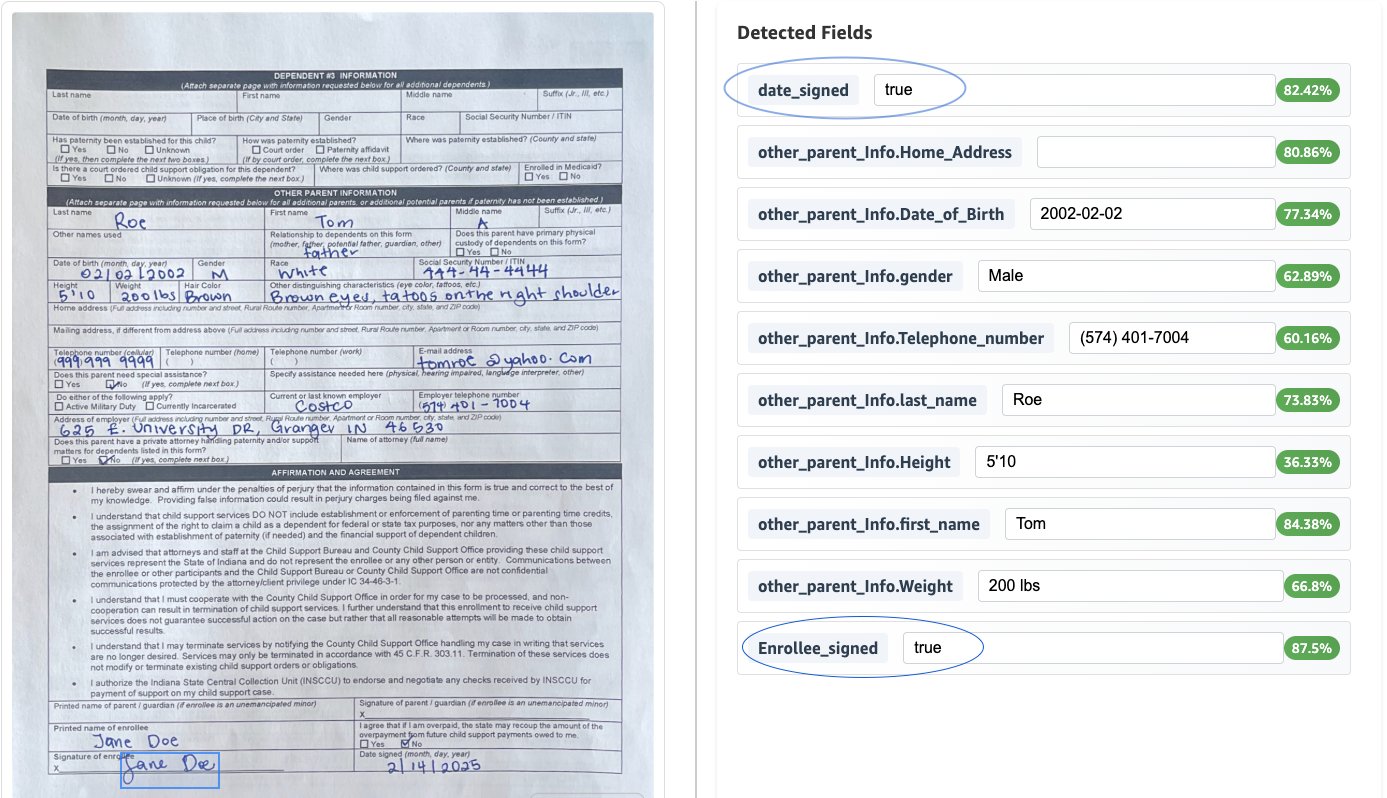
Our implementation includes validation rules for maintaining data accuracy and compliance. For our example use case, we’ve implemented two validations: 1. verify the presence of the enrollee’s signature and 2. verify that the signed date isn’t in the future.

The following screenshot shows the result of the above validation rules applied to the document.
Human-in-the-loop validation
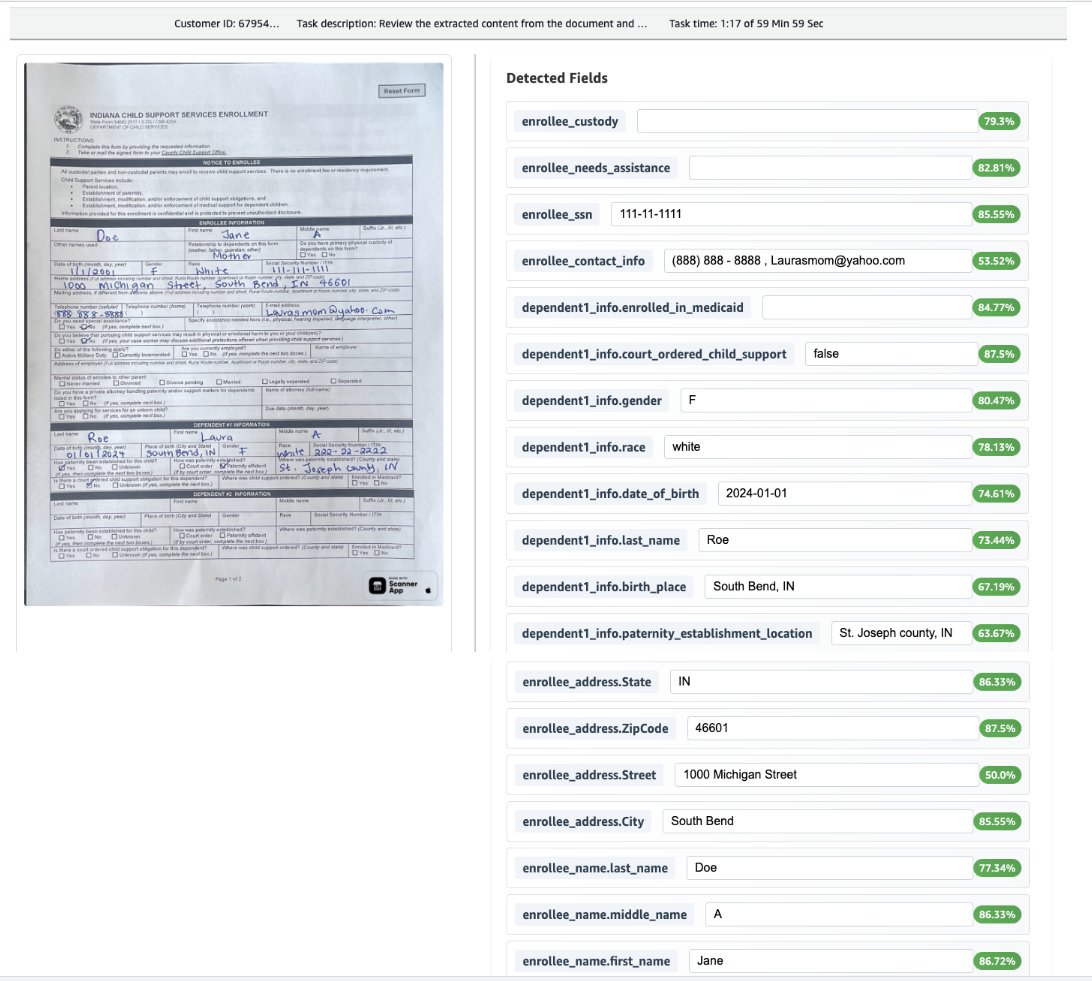
The following screenshot illustrates the extraction process, which includes a confidence score and is integrated with a human-in-the-loop process. It also shows normalization applied to the date of birth format.
Conclusion
Amazon Bedrock Data Automation significantly advances IDP by introducing confidence scoring, bounding box data, automatic classification, and rapid development through blueprints. In this post, we demonstrated how to take advantage of its advanced capabilities for data normalization, transformation, and validation. By upgrading to Amazon Bedrock Data Automation, organizations can significantly reduce development time, improve data quality, and create more robust, scalable IDP solutions that integrate with human review processes.
Follow the AWS Machine Learning Blog to keep up to date with new capabilities and use cases for Amazon Bedrock.
About the authors
 Abdul Navaz is a Senior Solutions Architect in the Amazon Web Services (AWS) Health and Human Services team, based in Dallas, Texas. With over 10 years of experience at AWS, he focuses on modernization solutions for child support and child welfare agencies using AWS services. Prior to his role as a Solutions Architect, Navaz worked as a Senior Cloud Support Engineer, specializing in networking solutions.
Abdul Navaz is a Senior Solutions Architect in the Amazon Web Services (AWS) Health and Human Services team, based in Dallas, Texas. With over 10 years of experience at AWS, he focuses on modernization solutions for child support and child welfare agencies using AWS services. Prior to his role as a Solutions Architect, Navaz worked as a Senior Cloud Support Engineer, specializing in networking solutions.
 Venkata Kampana is a senior solutions architect in the Amazon Web Services (AWS) Health and Human Services team and is based in Sacramento, Calif. In this role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a senior solutions architect in the Amazon Web Services (AWS) Health and Human Services team and is based in Sacramento, Calif. In this role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
 Sanjeev Pulapaka is principal solutions architect and AI lead for public sector. Sanjeev is a published author with several blogs and a book on generative AI. He is also a well-known speaker at several events including re:Invent and Summit. Sanjeev has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.
Sanjeev Pulapaka is principal solutions architect and AI lead for public sector. Sanjeev is a published author with several blogs and a book on generative AI. He is also a well-known speaker at several events including re:Invent and Summit. Sanjeev has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.
Source: Read MoreÂ

