
Introduction
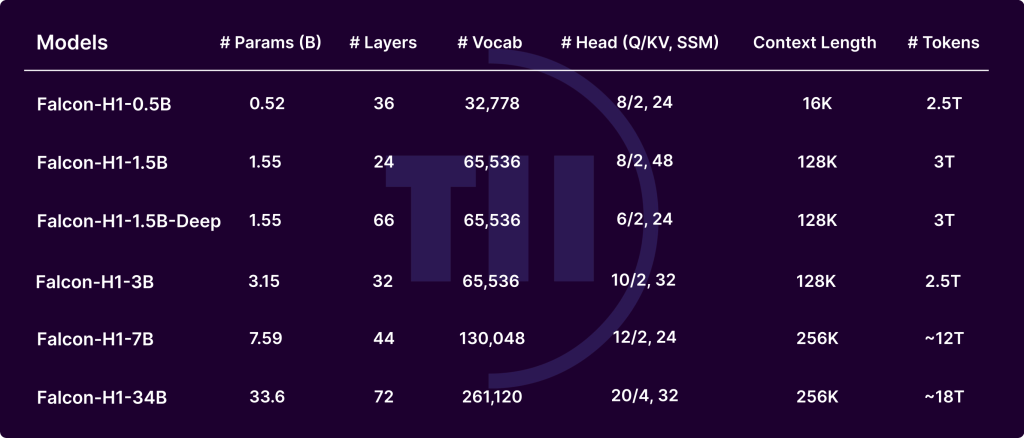
The Falcon-H1 series, developed by the Technology Innovation Institute (TII), marks a significant advancement in the evolution of large language models (LLMs). By integrating Transformer-based attention with Mamba-based State Space Models (SSMs) in a hybrid parallel configuration, Falcon-H1 achieves exceptional performance, memory efficiency, and scalability. Released in multiple sizes (0.5B to 34B parameters) and versions (base, instruct-tuned, and quantized), Falcon-H1 models redefine the trade-off between compute budget and output quality, offering parameter efficiency superior to many contemporary models such as Qwen2.5-72B and LLaMA3.3-70B.
Key Architectural Innovations
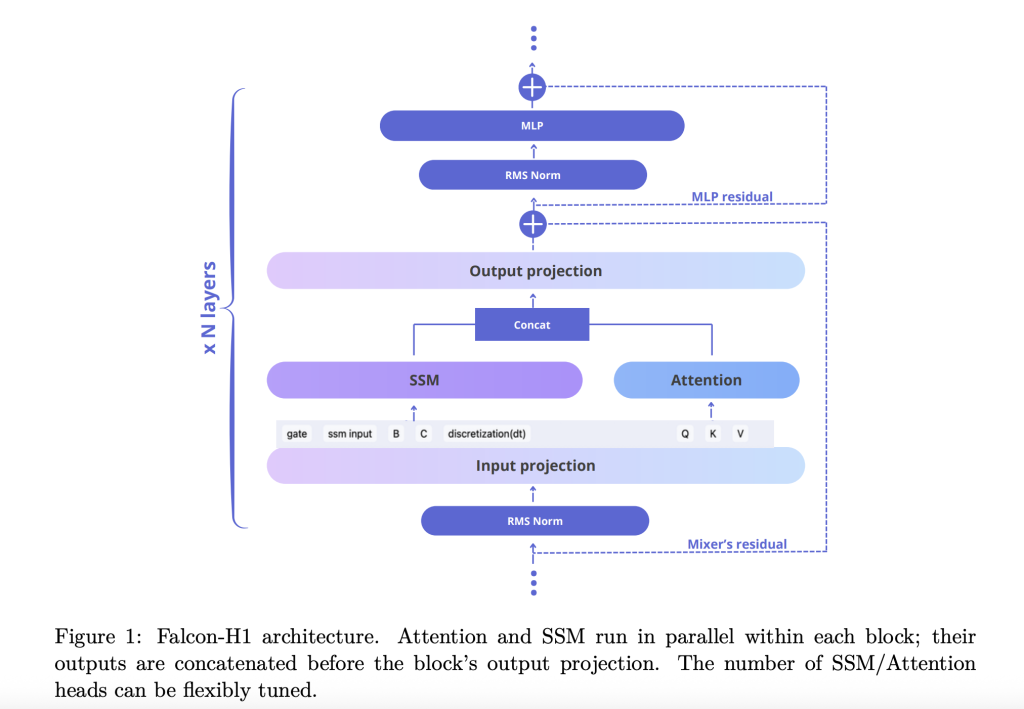
The technical report explains how Falcon-H1 adopts a novel parallel hybrid architecture where both attention and SSM modules operate concurrently, and their outputs are concatenated before the projection. This design deviates from traditional sequential integration and provides the flexibility to tune the number of attention and SSM channels independently. The default configuration uses a 2:1:5 ratio for SSM, attention, and MLP channels respectively, optimizing both efficiency and learning dynamics.
To further refine the model, Falcon-H1 explores:
- Channel allocation: Ablations show that increasing attention channels deteriorates performance, whereas balancing SSM and MLP yields robust gains.
- Block configuration: The SA_M configuration (semi-parallel with attention and SSM run together, followed by MLP) performs best in training loss and computational efficiency.
- RoPE base frequency: An unusually high base frequency of 10^11 in Rotary Positional Embeddings (RoPE) proved optimal, improving generalization during long-context training.
- Width-depth trade-off: Experiments show that deeper models outperform wider ones under fixed parameter budgets. Falcon-H1-1.5B-Deep (66 layers) outperforms many 3B and 7B models.
Tokenizer Strategy
Falcon-H1 uses a customized Byte Pair Encoding (BPE) tokenizer suite with vocabulary sizes ranging from 32K to 261K. Key design choices include:
- Digit and punctuation splitting: Empirically improves performance in code and multilingual settings.
- LATEX token injection: Enhances model accuracy on math benchmarks.
- Multilingual support: Covers 18 languages and scales to 100+, using optimized fertility and bytes/token metrics.
Pretraining Corpus and Data Strategy
Falcon-H1 models are trained on up to 18T tokens from a carefully curated 20T token corpus, comprising:
- High-quality web data (filtered FineWeb)
- Multilingual datasets: Common Crawl, Wikipedia, arXiv, OpenSubtitles, and curated resources for 17 languages
- Code corpus: 67 languages, processed via MinHash deduplication, CodeBERT quality filters, and PII scrubbing
- Math datasets: MATH, GSM8K, and in-house LaTeX-enhanced crawls
- Synthetic data: Rewritten from raw corpora using diverse LLMs, plus textbook-style QA from 30K Wikipedia-based topics
- Long-context sequences: Enhanced via Fill-in-the-Middle, reordering, and synthetic reasoning tasks up to 256K tokens
Training Infrastructure and Methodology
Training utilized customized Maximal Update Parametrization (µP), supporting smooth scaling across model sizes. The models employ advanced parallelism strategies:
- Mixer Parallelism (MP) and Context Parallelism (CP): Enhance throughput for long-context processing
- Quantization: Released in bfloat16 and 4-bit variants to facilitate edge deployments
Evaluation and Performance
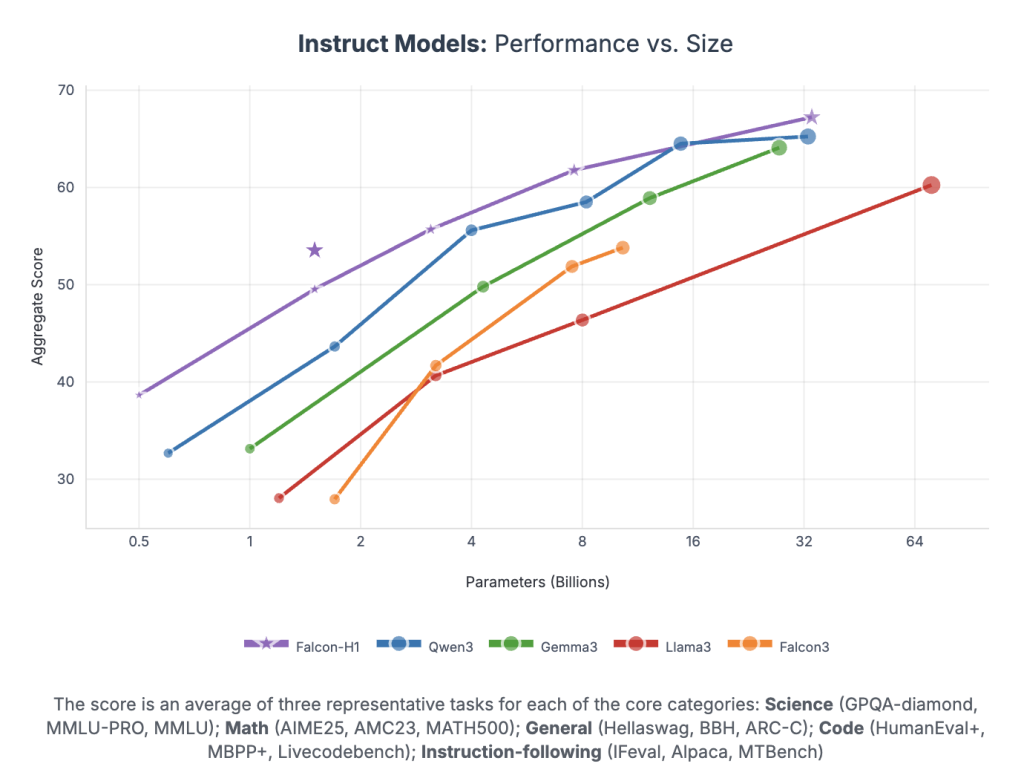
Falcon-H1 achieves unprecedented performance per parameter:
- Falcon-H1-34B-Instruct surpasses or matches 70B-scale models like Qwen2.5-72B and LLaMA3.3-70B across reasoning, math, instruction-following, and multilingual tasks
- Falcon-H1-1.5B-Deep rivals 7B–10B models
- Falcon-H1-0.5B delivers 2024-era 7B performance
Benchmarks span MMLU, GSM8K, HumanEval, and long-context tasks. The models demonstrate strong alignment via SFT and Direct Preference Optimization (DPO).
Conclusion
Falcon-H1 sets a new standard for open-weight LLMs by integrating parallel hybrid architectures, flexible tokenization, efficient training dynamics, and robust multilingual capability. Its strategic combination of SSM and attention allows for unmatched performance within practical compute and memory budgets, making it ideal for both research and deployment across diverse environments.
Check out the Paper and Models on Hugging Face. Feel free to check our Tutorials page on AI Agent and Agentic AI for various applications. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Falcon LLM Team Releases Falcon-H1 Technical Report: A Hybrid Attention–SSM Model That Rivals 70B LLMs appeared first on MarkTechPost.
Source: Read MoreÂ

