
To make streamline project development and maintenance, in any programming language, we need the support of metadata, configuration, and documentation. Project configurations can be done using configuration files. Configuration files are easy to use and make it user friendly to interact with developer. One such type of configuration files used in DBT are the YAML files.
In this blog, will go through the required YAML files in DBT.
Let’s understand first what YAML is and DBT
DBT (Data Build Tool) :
Data transformation is the important process in modern analytics. DBT is a system to transform, clean and aggregate data within data warehouse. The power of DBT lies in its utilization of YAML files for both configuration and transformation.
Note:
Please go through link for DBT(DBT)
What is YAML file:
YAML acronym as “Yet Another Markup Language.” It is easy to read and understand. YAML is superset of JSON.
Common use of YAML file:
– Configuration Management:
Use to define configuration like roles, environment.
– CI/CD Pipeline:
CI/CD tools depend on YAML file to describe their pipeline.
– Data Serialization:
YAML can manage complex data types such as linked list, arrays, etc.
– API:
YAML can be use in defining API contracts and specification.
Sample Example of YAML file:
YAML files are the core of defining configuration and transformation in DBT. YAML files have “.yml” extension.
The most important YAML file is
profiles.yml:
This file needs to be locally. It contains sensitive that can be used to connect with target data warehouse.
Purpose:
It consists of main configuration details to which connect with data warehouse(Snowflake, Postgres, etc.)
profile configuration looks like as :

Note:
We should not share profiles.yml file with anyone because it consists of target data warehouse information. This file will be used in DBT core and not in DBT cloud.
YAML file classification according to DBT component:
Let us go through different components of DBT with corresponding YAML files:
1.dbt_project.yml:
This is the most important configuration file in DBT. This file tells DBT what configuration
need to use for projects. By default, dbt_project.yml is the current directory structure
For Example:
name: string
config-version: 2
version: version
profile: profilename
model-paths: [directorypath]
seed-paths: [directorypath]
test-paths: [directorypath]
analysis-paths: [directorypath]
macro-paths: [directorypath]
snapshot-paths: [directorypath]
docs-paths: [directorypath]
asset-paths: [directorypath]
packages-install-path: directorypath
clean targets: [directorypath]
query-comment: string
require-dbt-version: version-range | [version-range]
flags:
<global-configs>
dbt-cloud:
project-id: project_id # Required
defer-env-id: environment # Optional
exposures:
+enabled: true | false.
quoting:
database: true | false
schema: true | false
identifier: true | false
metrics:
<metric-configs>
models:
<model-configs>
seeds:
<seed-configs>
semantic-models:
<semantic-model-configs>
saved-queries:
<saved-queries-configs>
snapshots:
<snapshot-configs>
sources:
<source-configs>
tests:
<test-configs>
vars:
<variables>
on-run-start: sql-statement | [sql-statement]
on-run-end: sql-statement | [sql-statement]
dispatch:
- macro_namespace: packagename
search_order: [packagename]
restrict-access: true | false
Model:
Models use SQL language that defines how your data is transformed .In a model, configuration file, you define the source and the target tables and their transformations. It is under the model directory of DBT project, and we can give name as per our convenience.
Below is the example:
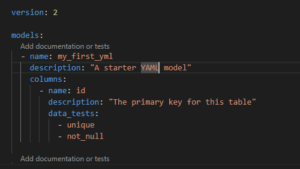
 This is the YAML file in model. Given name as “schema.yml”
This is the YAML file in model. Given name as “schema.yml”
Purpose of model YML file:
It configures the model level metadata such as tags, materialization, name, column which use for transforming the data
It looks like as below:
version: 2
models:
- name: my_first_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
data_tests:
- unique
- not_null
- name: my_second_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
data_tests:
- unique
- not_null
2.Seed:
Seeds used to load CSV files into data model. This is useful for staging before applying any
transformation.
Below is the example:
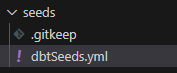
Purpose of Seeds YAML file:
To define the path of CSV file under seed directory and which column needs to transform in CSV file and load into the data warehouse tables.
Configuration file looks like as below:
version: 2
seeds:
- name: <name>
description: Raw data from a source
database: <database name>
schema: <database schema>
materialized: table
sql: |-
SELECT
id,
name
FROM <source_table>
Testing:
Testing is a key step in any project. Similarly, DBT create test folder to test unique constraints, not null values.
Create dbtTest.yml file under test folder of DBT project
And it looks like as below:
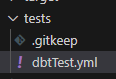
Purpose of test YML file as:
It helps to check data integrity quality and separates from the business logic
It looks like as below:
columns:
- name: order_id
tests:
- not_null
- unique
As we go through different YAML files in DBT and purpose for the same.
Conclusion:
dbt and its YAML files provide human readable way to manage data transformation. With dbt, we can easily create, transform, and test the data models and make valuable tools for data professionals. With both DBT and YAML, it empowers you to work more efficiently as data analyst. Data engineers or business analysts
Thanks for reading.
Source: Read MoreÂ

