
Key takeaways:
A unified architecture significantly reduces development complexity by eliminating synchronization challenges between separate vector and operational databases.
Data consistency is guaranteed through atomic transactions in unified systems, preventing “ghost documents” and other split architecture failures.
The total cost of ownership is typically lower with unified architectures due to consolidated infrastructure and reduced maintenance burden.
Developer velocity increases with unified approaches as teams can focus on building features rather than integration code and error handling.
MongoDB Atlas provides future-proofing benefits with integrated AI capabilities like vector search, automatic quantization and more.
AI demands more from databases, and the architectural decisions organizations make today directly affect their time‑to‑market and competitive edge. In the generative AI era, your database must support both high‑dimensional vector searches and fast transactional workloads to keep pace with rapid business and technological change.
In this piece, we examine the architectural considerations technology leaders and architects should consider when managing AI applications’ diverse data requirements, including high-dimensional vector embeddings for semantic search alongside traditional operational data (user profiles, content metadata, etc.). This dichotomy presents two distinct architectural approaches—split versus unified—each with significant implications for application performance, consistency, and developer experience.
Note: For technical leaders who want to equip their teams with the nuts and bolts details—or who need solid evidence to win over skeptical developers—we’ve published a comprehensive implementation guide. While this article focuses on the strategic considerations, the guide dives into the code-level realities that your development team will appreciate.
Why data architecture matters
Building successful AI products and features involves thinking ahead about the speed and cost of intelligence at scale. Whether you’re implementing semantic search for a knowledge base or powering a real-time recommendation engine, your database architecture underpins how quickly and reliably you can bring those features to market.
In the AI era, success no longer hinges solely on having innovative algorithms—it’s fundamentally determined by output accuracy and relevancy. This represents a profound shift: data architecture, once relegated to IT departments, has become everyone’s strategic concern. It directly influences how quickly your developers can innovate (developer velocity), how rapidly you can introduce new capabilities to the market (time-to-market), and how reliably your systems perform under real-world conditions (operational reliability).
In essence, your data architecture has become the foundation upon which your entire AI strategy either thrives or falters. Your data architecture is your data foundation.
Unlike traditional applications that dealt mostly with structured data and simple CRUD queries, AI applications generate and query vector representations of unstructured data (like text, images, and audio) to find “similar” items. These vectors are often stored in dedicated vector databases or search engines optimized for similarity search. At the same time, applications still need traditional queries (exact lookups, aggregations, transactions on business data). This raises a key fundamental architectural question:
Do we use separate specialized databases for these different workloads and data structures, or unify them in one system?
Let’s also take the opportunity to briefly address the concept of an “AI database” that has emerged to describe a system that handles both standard operational workloads and AI-specific operations such as vector search. In short, behind AI Search capabilities in modern AI applications, are AI retrieval techniques enabled by databases optimized for AI workloads.
Split architecture: Integrating a separate vector store
In a split architecture, vector operations and transactional data management are delegated to separate, specialized systems. A general purpose database (e.g., MongoDB, PostgreSQL) maintains operational data, while a dedicated vector store (e.g., Elasticsearch, Pinecone) manages embeddings and similarity search operations.
On the surface, this divide and conquer approach lets each system do what it’s best at.
The search engine or dedicated vector store can specialize in vector similarity queries, while the operational database handles updates and persistence. This leverages specialized optimizations in each system but introduces synchronization requirements between data stores.
Many AI teams have implemented semantic search and other AI functionalities this way, using an external vector index alongside their application database, with both systems kept in sync through custom middleware or application-level logic.
Split architecture characteristics:
Specialized systems: Each database is optimized for its role (e.g. the operational DB ensures fast writes, ACID transactions, and rich queries; the vector search engine provides efficient similarity search using indexes like HNSW for approximate nearest neighbor).
Data duplication: Vector embeddings (and often some identifiers or metadata) are duplicated in the vector store. The primary ID or key exists in both systems to link results.
Synchronization logic: The application must handle synchronization – for every create/update/delete of a record, you need to also update or delete the corresponding vector entry in the search index. This can be done via event streams, change capture, or in application code calling two systems.
Data querying: Multi-stage query patterns requiring cross-system coordination
Example stack: An example is using MongoDB as the source of truth for product documents, and Elasticsearch as a vector search engine for product description embeddings. The app writes to MongoDB, then indexes the embedding into Elasticsearch, and at query time does a vector search in Elasticsearch, then fetches the full document from MongoDB by ID.
This system pattern is what we hear from a number of AI teams that leverage MongoDB and… well, just about anything else that promises to make vectors dance faster.
It’s the architectural equivalent of wearing both a belt and suspenders—sure, your pants aren’t falling down, but you’re working awfully hard to solve what could be a simpler problem. These teams often find themselves building more synchronization code than actual features, turning what should be AI innovation into a complex juggling act of database coordination.
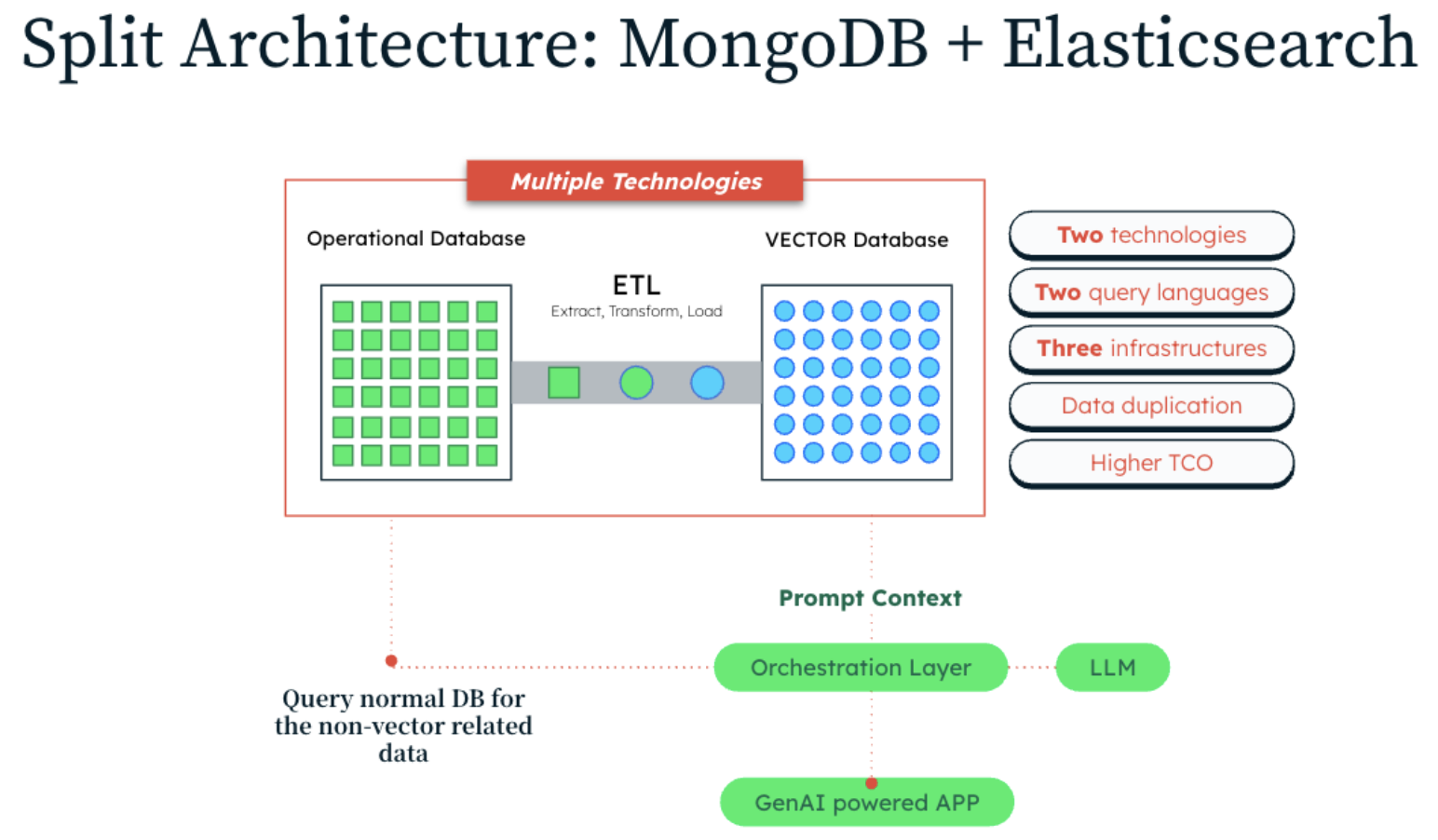
Putting belts and suspenders aside, the notable point is that splitting the architecture comes at a cost.
You now have two sources of truth that need to stay in sync. Every time you add or update data, you must index the vector in the search engine. Every query involves multiple round trips – one to the search service to find relevant items, and another to the database to fetch full details.
This added complexity can slow development and introduces potential points of failure. Operating a split system introduces challenges, as we’ll discuss, around consistency (e.g. “ghost” records when the two systems get out of sync) and added complexity in development and maintenance.
In extremely high-scale or ultra-low-latency use cases (e.g., >1B vectors or <1 ms NN SLAs), a dedicated vector engine such as FAISS or Milvus may still outperform a general-purpose database on raw similarity-search throughput. However, MongoDB Atlas’s Search Nodes isolate vector search workloads onto separate, memory-optimized instances—allowing you to scale and tune search performance independently of your database nodes, often delivering the low-latency guarantees modern AI applications require.
Unified architecture with MongoDB Atlas: One platform for AI data
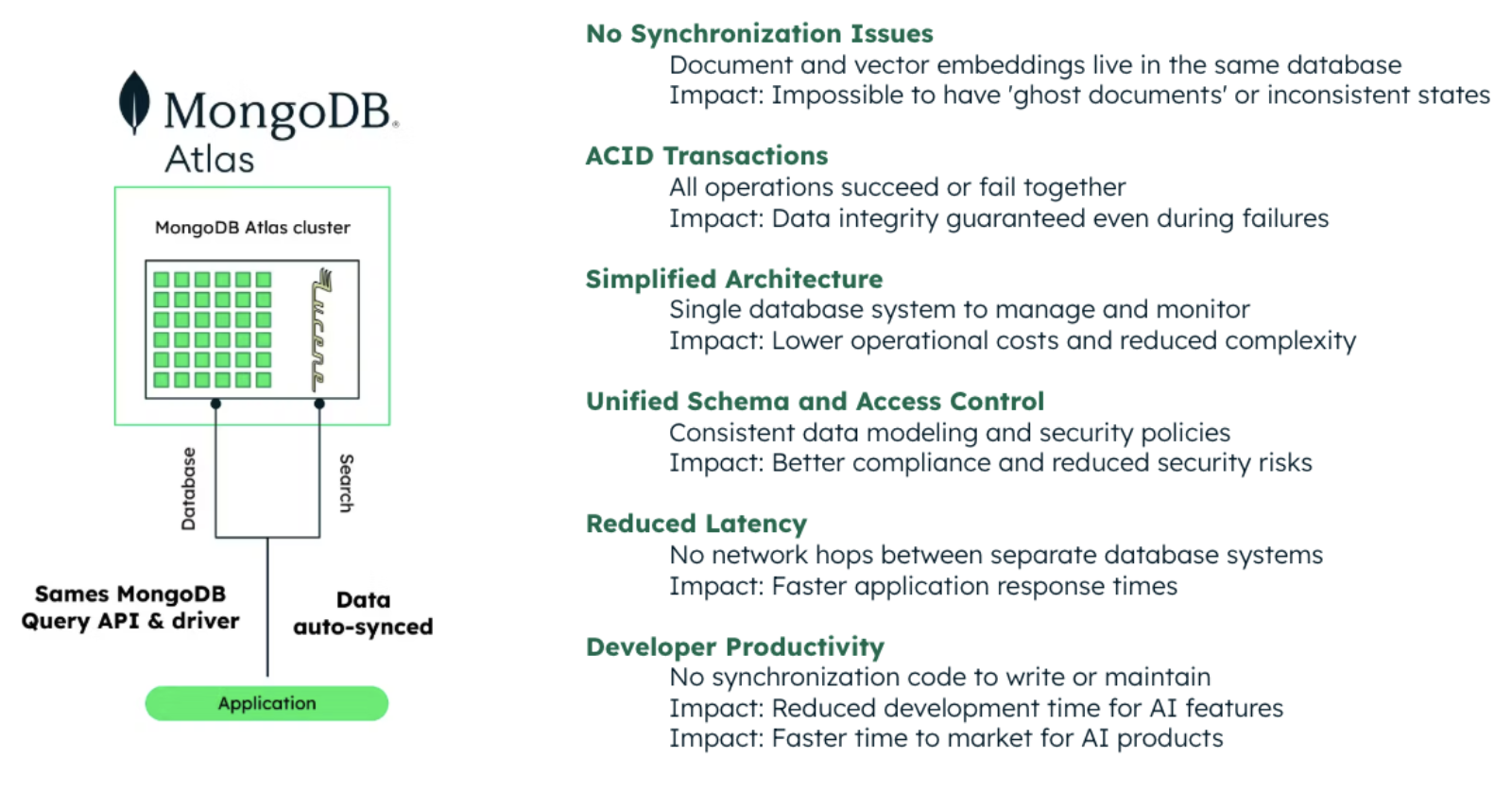
In a unified architecture, a single database platform handles both operational data and vector search functionalities. MongoDB Atlas Vector Search integrates vector indexing and search directly into the MongoDB database.
This architectural pattern simplifies the data model by storing embeddings alongside associated data in the same document structure. The database system internally manages vector indexing (using algorithms like HNSW) and provides integrated query capabilities across both vector and traditional data patterns.
In practice, this means your application can execute one query (to MongoDB) that filters and finds data based on vector similarity, without needing a second system. This means all data – your application’s documents and their vector representations – live in one place, under one ACID-compliant transactional system for your AI workload.
Unified architecture characteristics:
Single source of truth: Both the raw data and the vector indexes reside in one database. For example, MongoDB Atlas allows storing vector fields in documents and querying them with integrated vector search operators. There is no need to duplicate or sync data between different systems.
Atomic operations: Updates to a document and its vector embedding occur in one atomic transaction or write operation. This guarantees strong consistency – your vector index can’t drift from your document data. If a transaction fails, none of the changes (neither the document nor its embedding) are committed. This eliminates issues like “ghost documents” (we’ll define this shortly) because it’s impossible to have an embedding without its corresponding document in the same database.
Unified query capabilities: The query language (e.g. MongoDB’s MQL) can combine traditional filters, full-text search, and vector similarity search in one query. This hybrid search capability means you can, for instance, find documents where category = “Tech” and embedding is similar to a query vector – all in one go. You don’t have to do two queries in different systems and then merge results in your application.
Operational simplicity: There’s only one system to manage, secure, scale, and monitor. In a managed cloud platform like MongoDB Atlas, you get a fully managed service that handles both operational and vector workloads, often with features to optimize each (for example, dedicated “search nodes” that handle search indexing and queries so that heavy vector searches don’t impact transactional workload performance).
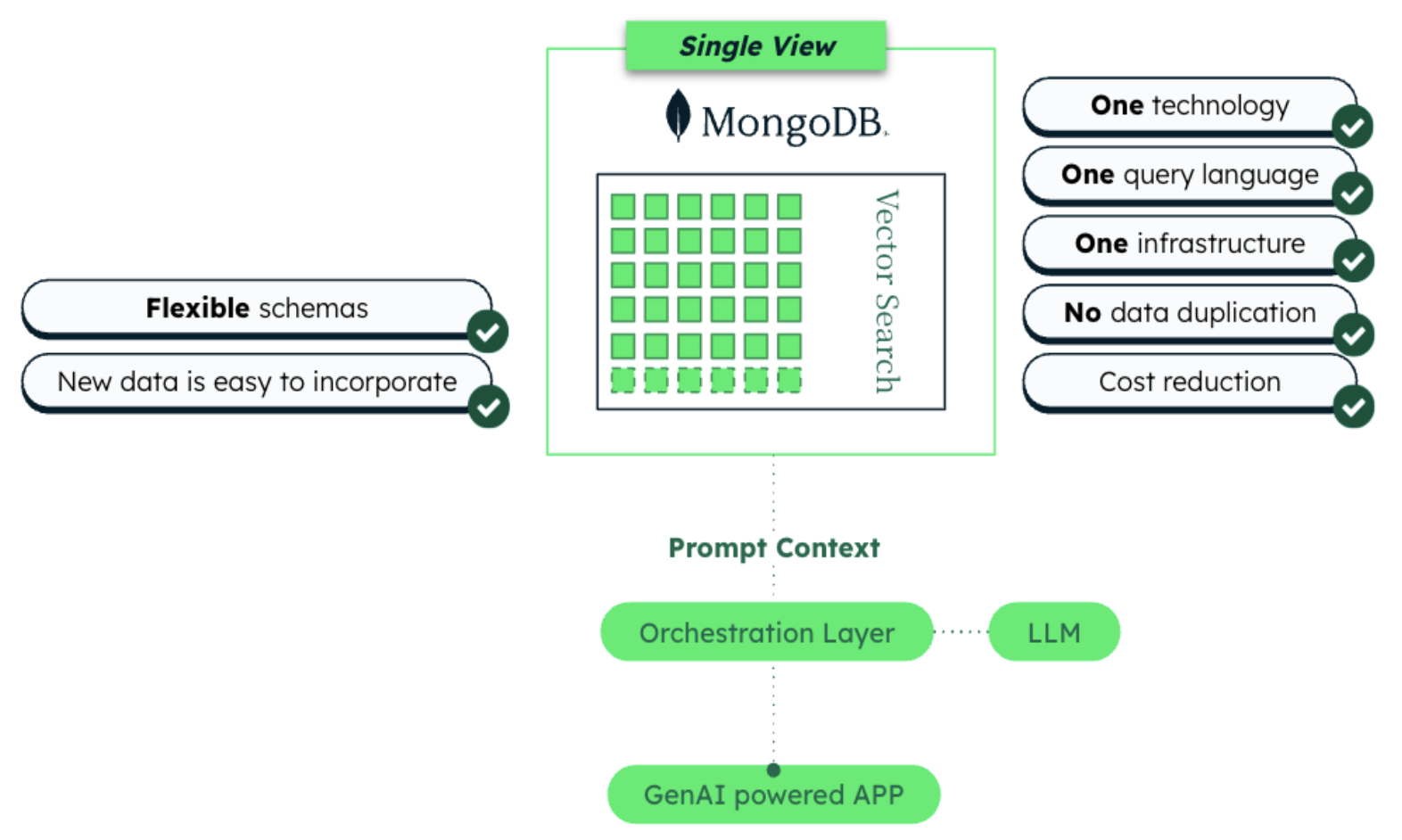
MongoDB Atlas integrates an Atlas Vector Search engine (built on Apache Lucene, same technology used in some dedicated vector search engines) directly into the database. This allows developers to store high-dimensional vectors in documents and run similarity searches using indexes powered by algorithms like HNSW (Hierarchical Navigable Small World graphs) for approximate nearest neighbor (ANN) search.
Additional features like vector
quantization (to compress vectors for efficiency) and hybrid search (combining vector and text searches) are supported out-of-the-box and constructed with the MongoDB Query Language (MQL).
All of this occurs under the umbrella of the MongoDB Atlas database’s transaction engine and security architecture. In short, the unified approach aims to provide the best of both worlds – the rich functionality of a specialized vector store and the reliability/consistency of a single operational datastore.
A strategic consideration for decision makers
For technical leaders managing both innovation and budgets, the unified approach presents a compelling financial case alongside its technical merits.
If your organization is already leveraging MongoDB as your operational database—as thousands of enterprises worldwide do—the path to AI enablement becomes remarkably streamlined. Rather than allocating budget for an entirely new vector database system, with all the associated licensing, infrastructure, and staffing costs, you can extend your existing MongoDB investment to handle vector workloads.
Your teams already understand MongoDB’s architecture, security model, and operational characteristics. Adding vector capabilities becomes an incremental skill addition rather than a steep learning curve for an entirely new system. For projects already in flight, migrating vector data or generating new embeddings within your existing MongoDB infrastructure can be accomplished without disrupting ongoing operations.
Technical overview of split vs. unified architecture
To illustrate the practical implications of each architecture, let’s observe high level implementation and operational considerations for a knowledge base question-answering application. Both approaches enable vector similarity search, but with notable differences in implementation complexity and consistency guarantees.
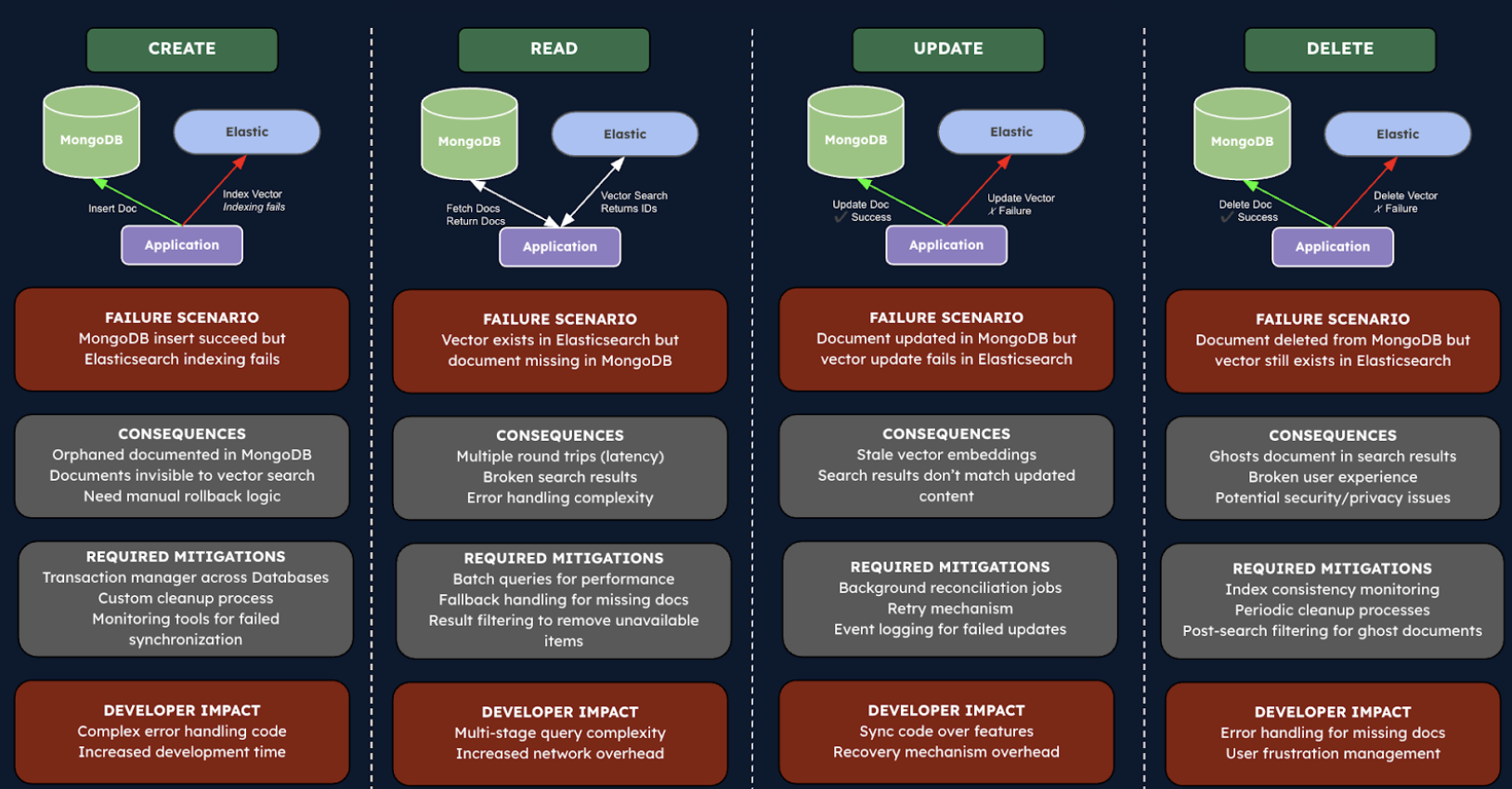
In a split architecture (e.g. using MongoDB + Elasticsearch): We store the article content and metadata in MongoDB, and store the embedding vectors in an Elasticsearch index. At query time, we’ll search the Elasticsearch index by vector similarity to get a list of top article IDs, then retrieve those articles from MongoDB by their IDs.
There are several key operations that are involved in a dual database architecture:
Creation: During document creation, the application must coordinate insertions across both systems. First, the document is stored in MongoDB, then its vector embedding is generated and stored in Elasticsearch. If either operation fails, manual rollback logic is needed to maintain consistency. For example, if the MongoDB insertion succeeds but the Elasticsearch indexing fails, developers must implement custom cleanup code to delete the orphaned MongoDB document.
Read: Vector search becomes a multi-stage process in a split architecture. The application first queries Elasticsearch to find similar vectors, retrieves only the document IDs, then makes a second round-trip to MongoDB to fetch the complete documents matching those IDs. This introduces additional network latency and requires error handling for cases where documents exist in one system but not the other.
Update: Updating content presents significant synchronization challenges. After updating a document in MongoDB, the application must also update the corresponding vector in Elasticsearch. If the Elasticsearch update fails after the MongoDB update succeeds, the systems become out of sync, with the vector search returning outdated or incorrect results. There’s no atomic transaction spanning both systems, requiring complex recovery mechanisms.
Deletion: Deletion operations face similar synchronization issues. When a document is deleted from MongoDB but the corresponding deletion in Elasticsearch fails, “ghost documents” appear in search results – vectors pointing to documents that no longer exist. Users receive search results they cannot access, creating a confusing experience and potential security concerns if sensitive information remains indirectly accessible through preview content stored in Elasticsearch.
Each of these operations requires careful error handling, retry mechanisms, monitoring systems, and background reconciliation processes to maintain consistency between the two databases. And notably, the complexity compounds over time, with synchronization issues becoming more difficult to detect and resolve as the data volume grows, ultimately impacting both developer productivity and user experience.
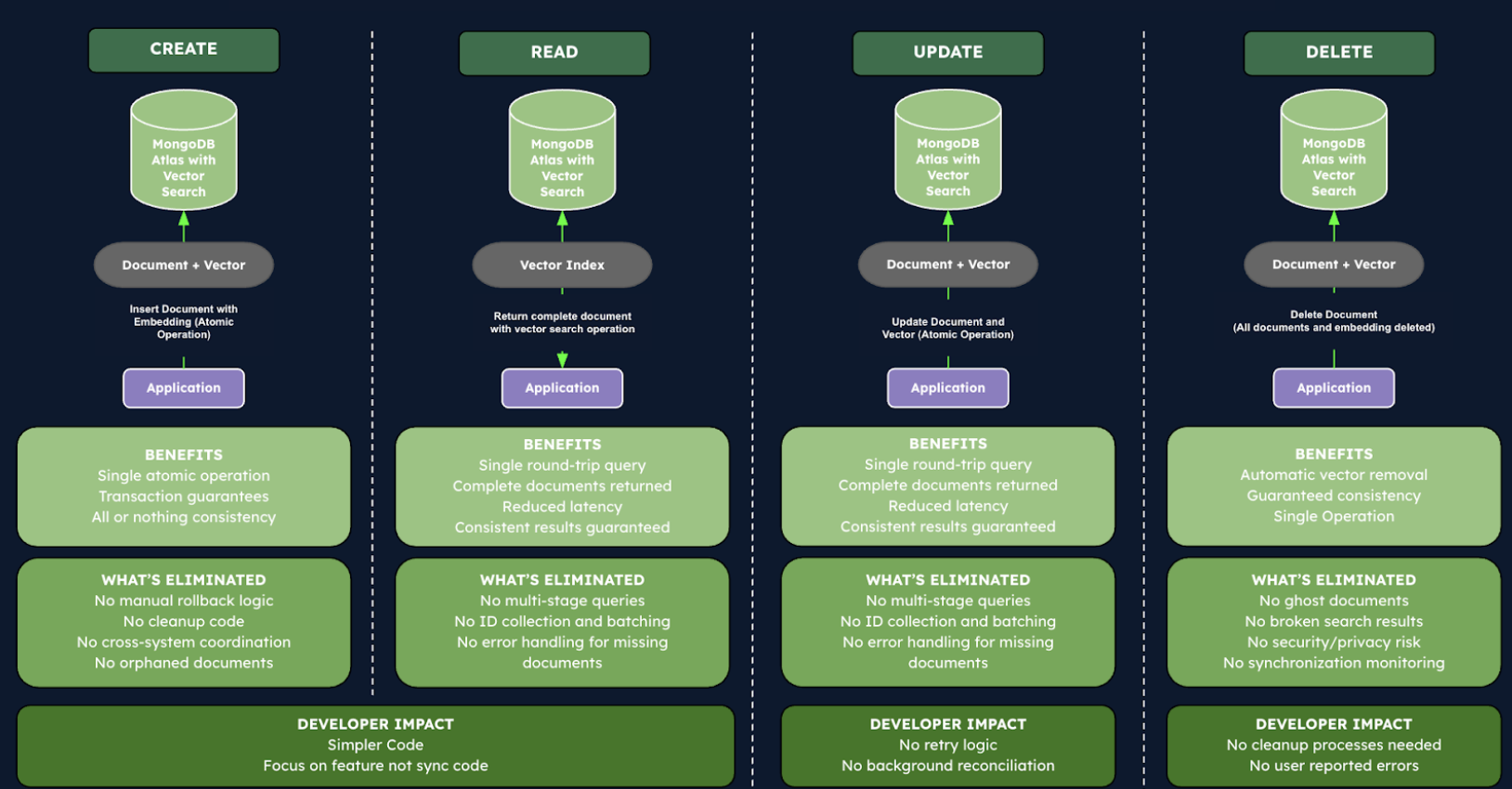
In a unified architecture (using MongoDB Atlas Vector Search): We store both the article data and its embedding vector in a single MongoDB document. An Atlas Vector Search index on the embedding field allows us to perform a similarity search directly within MongoDB using a single query. The database will internally use the vector index to find nearest neighbors and return the documents.
Let’s examine how the same operations simplify dramatically in a unified architecture:
Creation: Document creation becomes an atomic operation. The application stores both the document and its vector embedding in a single MongoDB document with one insert operation. Either the entire document (with its embedding) is stored successfully, or nothing is stored at all. There’s no need for custom rollback logic or cleanup code since MongoDB’s transaction guarantees ensure data integrity without additional application code.
Read: Vector search is streamlined into a single step. Using MongoDB’s aggregation pipeline with Atlas Vector Search, the application queries for similar vectors and retrieves the complete documents in a single round-trip. There’s no need to coordinate between separate systems or handle inconsistencies, as the vector search is directly integrated with document retrieval, substantially reducing both latency and code complexity.
Update: Document updates maintain perfect consistency. When updating a document’s content, the application can atomically update both the document and its vector embedding in a single operation. MongoDB’s transactional guarantees ensure that either both are updated or neither is, eliminating the possibility of out-of-sync data representations. Developers no longer need to implement complex recovery mechanisms for partial failures.
Deletion: The ghost document problem vanishes entirely. When a document is deleted, its vector embedding is automatically removed as well, since they exist in the same document. There’s no possibility of orphaned vectors or inconsistent search results. This ensures that search results always reflect the current state of the database, improving both reliability and security.
This unified approach eliminates the entire category of synchronization challenges inherent in split architectures. Developers can focus on building features rather than synchronization mechanisms, monitoring tools, and recovery processes. The system naturally scales without increasing complexity, maintaining consistent performance and reliability even as data volumes grow. Beyond the technical benefits, this translates to faster development cycles, more reliable applications, and ultimately a better experience for end users who receive consistently accurate search results.
The vector search and document retrieval happen in one round-trip to the database, which fundamentally transforms both the performance characteristics and operational simplicity of AI-powered applications.
Syncing data: Challenges and “ghost documents”
One of the biggest challenges with the split architecture is data synchronization. Because there are two sources of truth (the operational DB and the vector index), any change to data must be propagated to both. In practice, perfect synchronization is hard — network glitches, bugs, or process failures can result in one store updating while the other doesn’t. This can lead to inconsistencies that are difficult to detect and resolve.
A notorious example in a split setup is the “ghost document” scenario. A ghost document refers to a situation where the vector search returns a reference to a document that no longer exists (or no longer matches criteria) in the primary database.
For instance, suppose an article was deleted or marked private in MongoDB but its embedding was not removed from Elasticsearch. A vector search might still retrieve its ID as a top result – leading your application to try to fetch a document that isn’t there or shouldn’t be shown. From a user’s perspective, this could surface a result that is broken or stale.
Let’s go back to our practical scenario earlier: imagine a knowledge base system for customer support where articles are constantly being updated and occasionally removed when they become outdated. When a support agent deletes an article about a discontinued product, the deletion occurs in MongoDB successfully, but due to a network timeout, the corresponding vector deletion in Elasticsearch fails. And yes, that happens, especially with applications handling millions of requests daily.
Later, when a customer searches for solutions related to that discontinued product, the vector search in Elasticsearch identifies the now deleted article as highly relevant and returns its ID. When the application attempts to fetch the full content from MongoDB using this ID, it discovers the document no longer exists.
The customer sees a broken link or an error message instead of helpful content, creating a confusing and frustrating experience.
What’s particularly insidious about this problem is that it can manifest in various ways across the application. Beyond complete document deletion issues, you might encounter:
Stale embeddings: A document is updated in MongoDB with new content, but the vector in Elasticsearch still represents the old version, causing search results that don’t match the actual content.
Permission inconsistencies: A document’s access permissions change in MongoDB (e.g., from public to private), but it still appears in vector search results for users who shouldn’t access it.
Partial updates: Only some fields get updated across the systems, leading to mismatched metadata between what’s shown in search previews versus the actual document.
In production environments, development teams often resort to implementing complex workarounds to mitigate these synchronization issues:
Background reconciliation jobs that periodically compare documents across both systems and repair inconsistencies
Outbox patterns where operations are logged to a separate store and retried until successful
Custom monitoring systems specifically designed to detect and alert on cross-database inconsistencies
Manual intervention processes for support teams to address user-reported discrepancies
All these mechanisms represent significant development effort that could otherwise be directed toward building features that deliver real business value. They also introduce additional points of failure and operational complexity.
Crucially, a unified architecture avoids this entire class of problems. Since there is only one database, a document that is deleted is automatically removed from any associated indexes within the same transaction. A unified data model makes it relatively impossible to have a vector without its document, because they are one and held in the same document. As a result, issues like ghost documents, stale vector references, or needing to catch up two datastores simply go away.
No synchronization needed – when documents and embeddings live in one database, you’ll reduce the risk of ghost documents or inconsistent reads.
Trade-offs and considerations
There are several key trade-offs you have to weigh when comparing split and unified architectures for AI data. As mentioned, your choice will affect system complexity, performance characteristics, scalability, cost, and development agility. For AI project leads and Enterprise AI leaders it’s vital to understand these considerations, below are a few:
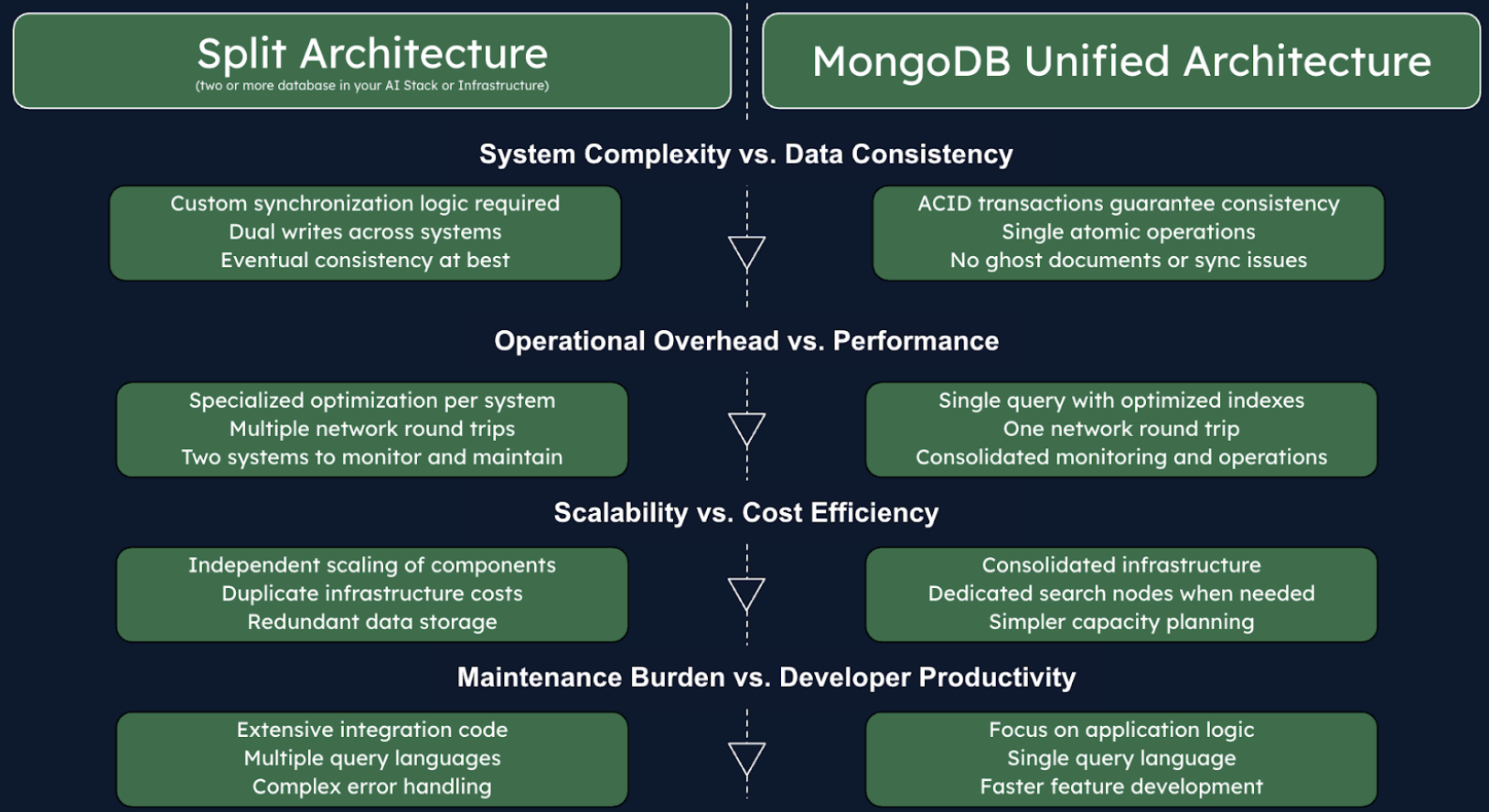
System Complexity vs. Data Consistency: Maintaining consistency in a split setup requires additional logic and increases system complexity. Every piece of data is effectively handled twice, introducing opportunities for inconsistency and complex failure modes. In a unified architecture, ACID transactions ensure that updates to data and its embedding vector occur together or not at all, simplifying the design and reducing custom error handling code.
Operational Overhead vs. Performance: A split architecture can leverage specialized engines optimized for similarity queries, but introduces network latency with multiple round trips and increases operational overhead with two systems to monitor. Unified architectures eliminate the extra network hop, potentially reducing query latency. MongoDB Atlas offers optimizations like vector quantization and dedicated search processing nodes that can match or exceed the performance of separate search engines.
Scalability vs. Cost Efficiency: Split architectures allow independent scaling of components but come with infrastructure cost duplication and data redundancy. A unified architecture consolidates resources while still enabling workload isolation through features like Atlas Search Nodes. This simplifies capacity planning and helps avoid over-provisioning multiple systems.
Maintenance Burden vs. Developer Velocity: Split architectures require substantial “glue code” for integration, dual writes, and synchronization, slowing development and complicating schema changes. Unified architectures let developers focus on application logic with fewer moving parts and a single query language, potentially accelerating time-to-market for AI features.
Future-Proofing: Simpler unified architectures make it easier and faster to adopt new capabilities as AI technology evolves. Split systems accumulate technical debt with each component upgrade, while unified platforms can incorporate new features transparently without redesigning integration points.
While some organizations may initially choose a split approach due to legacy systems or specialized requirements, MongoDB’s unified architecture with Atlas Vector Search now addresses many historical reasons for separate search engines, offering hybrid search capabilities, accuracy options, and optimization tools within a single database environment.
Choosing the right architecture for AI workloads
When should you choose a split architecture, and when does a unified architecture make more sense? The answer ultimately depends on your specific requirements and constraints.
Consider a Split Architecture if you already have significant infrastructure built around a specialized search or vector database and it’s meeting your needs. In some cases, extremely high-scale search applications might be deeply tuned on a separate engine, or regulatory requirements might dictate separate data stores.
A split approach can also make sense if one type of workload far outstrips the other (e.g., you perform vector searches on billions of items, but have relatively light transactional operations – though even then, a unified solution with the right indexing can handle surprising scale).
Just be prepared to invest in the tooling and engineering effort to keep the two systems in harmony. If you go this route, design your sync processes carefully and consider using change streams or event buses to propagate changes reliably. Also, weigh the operational cost: maintaining expertise in two platforms and the integration between them is non-trivial.
Consider a Unified Architecture if you are building a new AI-powered application or modernizing an existing one, and you want simplicity, consistency, and speed of development. If avoiding the pitfalls of data sync and reducing operational complexity are priorities, unified is a great choice.
A unified platform shines when your application needs tight integration between operational and vector data – for example, performing a semantic search with runtime filters on metadata, or updating content and immediately reflecting it in search results.
With a solution like MongoDB’s modern data platform, you get a fully managed, cloud-ready database that can handle both your online application needs and AI search needs under one roof. This leads to faster development cycles (since your team can work with one system and one query language) and greater confidence that your search results reflect the true state of your data at any moment.
Looking ahead, a unified architecture is arguably the more future-proof approach. AI capabilities evolve at an accelerated pace, so having your data in one place allows you to leverage new features immediately.
We work with AI customers building sophisticated AI applications, and one key observation is the requirement to streamline data processing operations within AI applications that leverage RAG pipelines or Agentic AI. Critical operations include chunking, embedding generation, vector search operation, and reranking.
We’ve also brought in Voyage AI’s state-of-the-art embedding models and rerankers to MongoDB. Soon, these models will reside within MongoDB Atlas and enable the conversion of data objects into embeddings and enforce an additional layer of data management in retrieval pipelines will all be within MongoDB Atlas. This step is one of the key ways MongoDB continues to bring intelligence to the data layer and creating a truly intelligent data foundation for AI applications.
MongoDB’s Atlas platform is continually expanding its AI-focused features – from vector search improvements to integration with data streams and real-time analytics – all while ensuring the core database guarantees (like ACID transactions and high availability) remain solid. This means you don’t have to re-architect your data layer to adopt the next big advancement in AI; your existing platform grows to support it.
Understandably, the split vs unified architecture debate is a classic example of balancing specialization against simplicity. Split systems can offer best-of-breed components for each task, but at the cost of complexity and potential inconsistency. Unified systems offer elegance and ease, bundling capabilities in one place, and have rapidly closed the gap in terms of features and performance.
Let’s end on this, MongoDB was built for change, and that ethos is exactly what organizations need as they navigate the AI revolution. By consolidating your data infrastructure and embracing technologies that unify capabilities, you equip your teams with the freedom to experiment and the confidence to execute. The future will belong to those who can harness AI and data together seamlessly. It’s time to evaluate your own architecture and make sure it enables you to ride the wave of AI innovation, and not be washed away by it.
In an AI-first era, the ability to adapt quickly and execute with excellence is what separates and defines leaders. The choice of database infrastructure is a pivotal part of that execution. Choose wisely – your next breakthrough might depend on it. Try MongoDB Atlas for free today, or head over to our Atlas Learning Hub to boost your MongoDB Atlas skills!
Source: Read More