
The CLIP framework has become foundational in multimodal representation learning, particularly for tasks such as image-text retrieval. However, it faces several limitations: a strict 77-token cap on text input, a dual-encoder design that separates image and text processing, and a limited compositional understanding that resembles bag-of-words models. These issues hinder its effectiveness in capturing nuanced, instruction-sensitive semantics. Although MLLMs like LLaVA, Qwen2-VL, and CogVLM offer significant advances in vision-language reasoning, their autoregressive next-token prediction objective restricts their ability to learn generalized, transferable embeddings. This has sparked growing interest in developing alternative methods that can combine the strengths of both contrastive learning and LLM-based reasoning.
Recent approaches aim to overcome these limitations by employing novel architectures and training strategies. For instance, E5-V proposes unimodal contrastive training for aligning cross-modal features, while VLM2Vec introduces the MMEB benchmark to convert advanced vision-language models into effective embedding generators. Models like LLM2Vec and NV-Embed enhance text-based representation learning by modifying the attention mechanisms in decoder-only LLMs. Despite these innovations, challenges such as handling long sequences, enabling better cross-modal fusion, and effectively distinguishing hard negatives in contrastive learning remain. As multimodal applications expand, there is a pressing need for representation learning methods that are both scalable and capable of fine-grained semantic alignment.
Researchers from institutions including The University of Sydney, DeepGlint, Tongyi Lab at Alibaba, and Imperial College London introduce UniME, a two-stage framework designed to improve multimodal representation learning using MLLMs. The first stage applies textual discriminative knowledge distillation from a strong LLM teacher to enhance the language encoder. The second stage employs hard negative enhanced instruction tuning, which involves filtering false negatives and sampling multiple challenging negatives per instance to improve the model’s discriminative and instruction-following abilities. Evaluations on the MMEB benchmark and various retrieval tasks show that UniME delivers consistent and significant improvements in both performance and compositional understanding.
The UniME framework introduces a two-stage method for learning universal multimodal embeddings using MLLMs. First, it employs textual discriminative knowledge distillation, where a student MLLM is trained using text-only prompts and supervised by a teacher model to enhance embedding quality. Then, a second stage—hard negative enhanced instruction tuning—improves cross-modal alignment and task performance by filtering false negatives and sampling hard negatives. This stage also leverages task-specific prompts to enhance instruction-following for various applications, such as retrieval and visual question answering. Together, these stages significantly boost UniME’s performance on both in- and out-of-distribution tasks.
The study evaluated UniME on Phi3.5-V and LLaVA-1.6 using PyTorch with DeepSpeed for efficient training across 8 NVIDIA A100 GPUs. Training consisted of two stages: a textual knowledge distillation phase using the NLI dataset (273,000 pairs) and a hard negative instruction tuning phase on 662,000 multimodal pairs. NV-Embed V2 served as the teacher model. UniME was evaluated on 36 MMEB benchmark datasets, achieving consistent improvements over baselines such as E5-V and VLM2Vec. Hard negatives significantly improved the model’s ability to distinguish subtle differences, thereby enhancing its performance, particularly in long-caption and compositional retrieval tasks. Ablation studies confirmed the effectiveness of both training stages and tuning parameters.
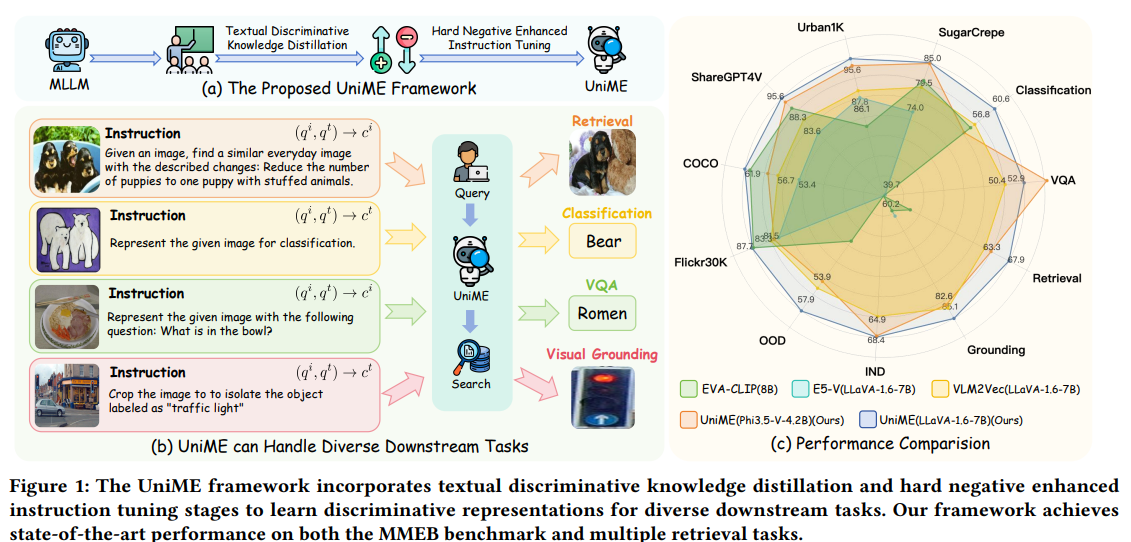
In conclusion, UniME is a two-stage framework designed to improve multimodal representation learning using MLLMs. In the first stage, UniME distills textual discriminative knowledge from a large language model to strengthen the language embeddings of the MLLM. In the second stage, it enhances learning through instruction tuning with multiple hard negatives per batch, reducing false negative interference and encouraging the model to distinguish challenging examples. Extensive evaluation on MMEB and various retrieval tasks demonstrates that UniME consistently boosts performance, offering strong discriminative and compositional abilities across tasks, thereby surpassing the limitations of prior models, such as CLIP.
Check out the Paper and Code. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on WorkshopThe post UniME: A Two-Stage Framework for Enhancing Multimodal Representation Learning with MLLMs appeared first on MarkTechPost.
Source: Read MoreÂ

