
Business intelligence (BI) plays a pivotal role in strategic decision-making. Enterprises collect massive amounts of data yet struggle to convert it into actionable insights. Conventional BI is reactive, constrained by predefined dashboards, and human-dependent, thus making it error-prone and non-scalable. Businesses today are data-rich but insight-poor.
Enter DataGenie, powered by MongoDB—BI reimagined for the modern enterprise. DataGenie autonomously tracks millions of metrics across the entire business datascape. It learns complex trends like seasonality, discovers correlations & causations, detects issues & opportunities, connects the dots across related items, and delivers 5 to 10 prioritized actionable insights as stories in natural language to non-data-savvy business users. This enables business leaders to make bold, data-backed decisions without the need for manual data analysis. With advanced natural language capabilities through Talk to Data, users can query their data conversationally, making analytics truly accessible.
The challenges: Why DataGenie needed a change
DataGenie processes large volumes of enterprise data on a daily basis for customers, tracking billions of time series metrics and performing anomaly detection autonomously to generate deep, connected insights for business users. The below diagram represents the functional layers of DataGenie.
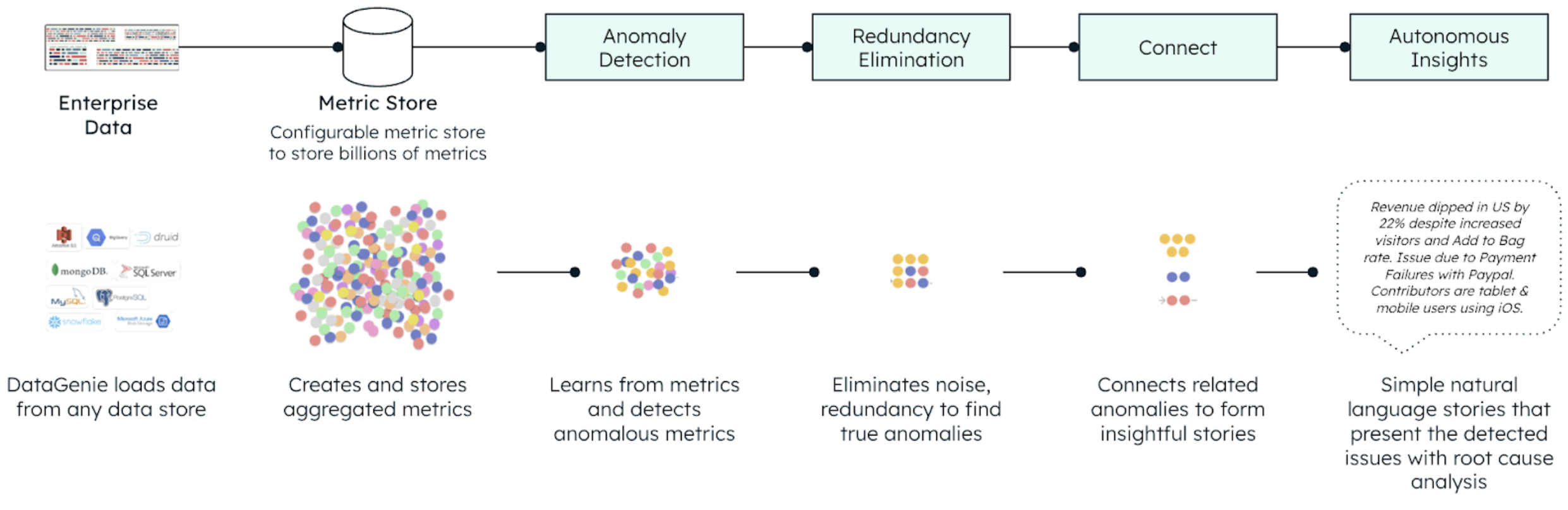
Central to the capability of DataGenie is the metrics store, which stores, rolls up, and serves billions of metrics. At DataGenie, we were using an RDBMS (PostgreSQL) as the metrics store.
As we scaled to larger enterprise customers, DataGenie processed significantly higher volumes of data. The complex feature sets we were building also required enormous flexibility and low latency in how we store & retrieve our metrics.
DataGenie had multiple components that served different purposes, and all of these had to be scaled independently to meet our sub-second latency requirements.
With PostgreSQL as the metrics store for quite some time and tried to squeeze it to the maximum extent possible at the cost of flexibility. Since we over-optimized the structure for performance, we lost the flexibility we required to build our next-gen features, which were extremely demanding
We defaulted to PostgreSQL for storing the insights (i.e. stories), again optimized for storage and speed, hurting us on the flexibility part
For the vector store, we had been using ChromaDB for storing all our vector embeddings. As the data volumes grew, the most challenging part was maintaining the data sync
We had to use a different data store for knowledge store and yet another technology for caching
The major problems we had were as follows:
Rigid schema that hindered flexibility for evolving data needs.
High latency & processing cost due to extensive preprocessing to achieve the desired structure
Slow development cycles that hampered rapid innovation
How MongoDB gave DataGenie a superpower
After extensive experimentation with time-series databases, document databases, and vector stores, we realized that MongoDB would be the perfect fit for us since it exactly solved all our requirements with a single database.
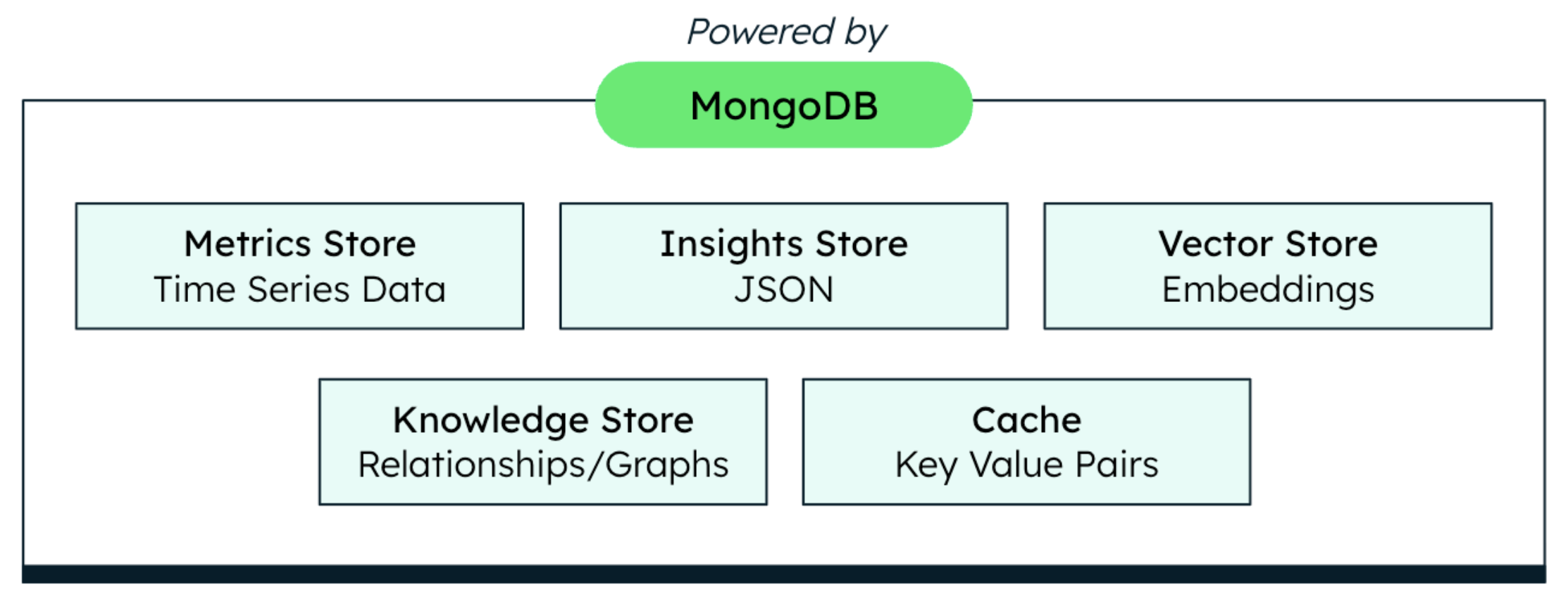
Metrics store
When we migrated to MongoDB, we achieved a remarkable reduction in query latency. Previously, complex queries on 120 million documents took around 3 seconds to execute. With MongoDB’s efficient architecture, we brought this down to an impressive 350-500 milliseconds for 500M+ docs, representing an 85-90% improvement in query speed for a much larger scale.
Additionally, for storing metrics, we transitioned to a key-value pair schema in MongoDB. This change allowed us to reduce our data volume significantly—from 300 million documents to just 10 million documents—thanks to MongoDB’s flexible schema and optimized storage. This optimization not only reduced our storage footprint for metrics but also enhanced query efficiency.
Insights store
By leveraging MongoDB for the insight service, we eliminated the need for extensive post-processing, which previously consumed substantial computational resources. This resulted in a significant cost advantage, reducing our Spark processing costs by 90% or more (from $80 to $8 per job).
Querying 10,000+ insights took a minute before. With MongoDB, the same task is now completed in under 6 seconds—a 10x improvement in performance. MongoDB’s flexible aggregation pipeline was instrumental in achieving these results. For example, we extensively use dynamic filter presets to control which insights are shown to which users, based on their role & authority. The MongoDB aggregation pipeline dynamically adapts to user configurations, retrieving only the data that’s relevant.
LLM service & vector store
The Genie+ feature in DataGenie is our LLM-powered application that unifies all DataGenie features through a conversational interface. We leverage MongoDB as a vector database to store KPI details, dimensions, and dimension values. Each vector document embeds essential metadata, facilitating fast and accurate retrieval for LLM-based queries. By serving as the vector store for DataGenie, MongoDB enables efficient semantic search, allowing the LLM to retrieve contextual, relevant KPIs, dimensions, and values with minimal latency, enhancing the accuracy and responsiveness of Genie+ interactions.
Additionally, integrating MongoDB Atlas Search for semantic search significantly improved performance. It provided faster, more relevant results while minimizing integration challenges.MongoDB’s schema-less design and scalable architecture also streamlined data management.
Knowledge store & cache
MongoDB’s schema-less design enables us to store complex, dynamic relationships and scale them with ease. We also shifted to using MongoDB as our caching layer.
Previously, having separate data stores made syncing and maintenance cumbersome. Centralizing this information in MongoDB simplified operations, enabled automatic syncing, and ensured consistent data availability across all features.
With MongoDB, DataGenie is reducing time-to-market for feature releases
Although we started the MongoDB migration to solve only our existing scalability and latency issues, we soon realized that just by migrating to MongoDB, we could imagine even bigger and more demanding features without engineering limitations.
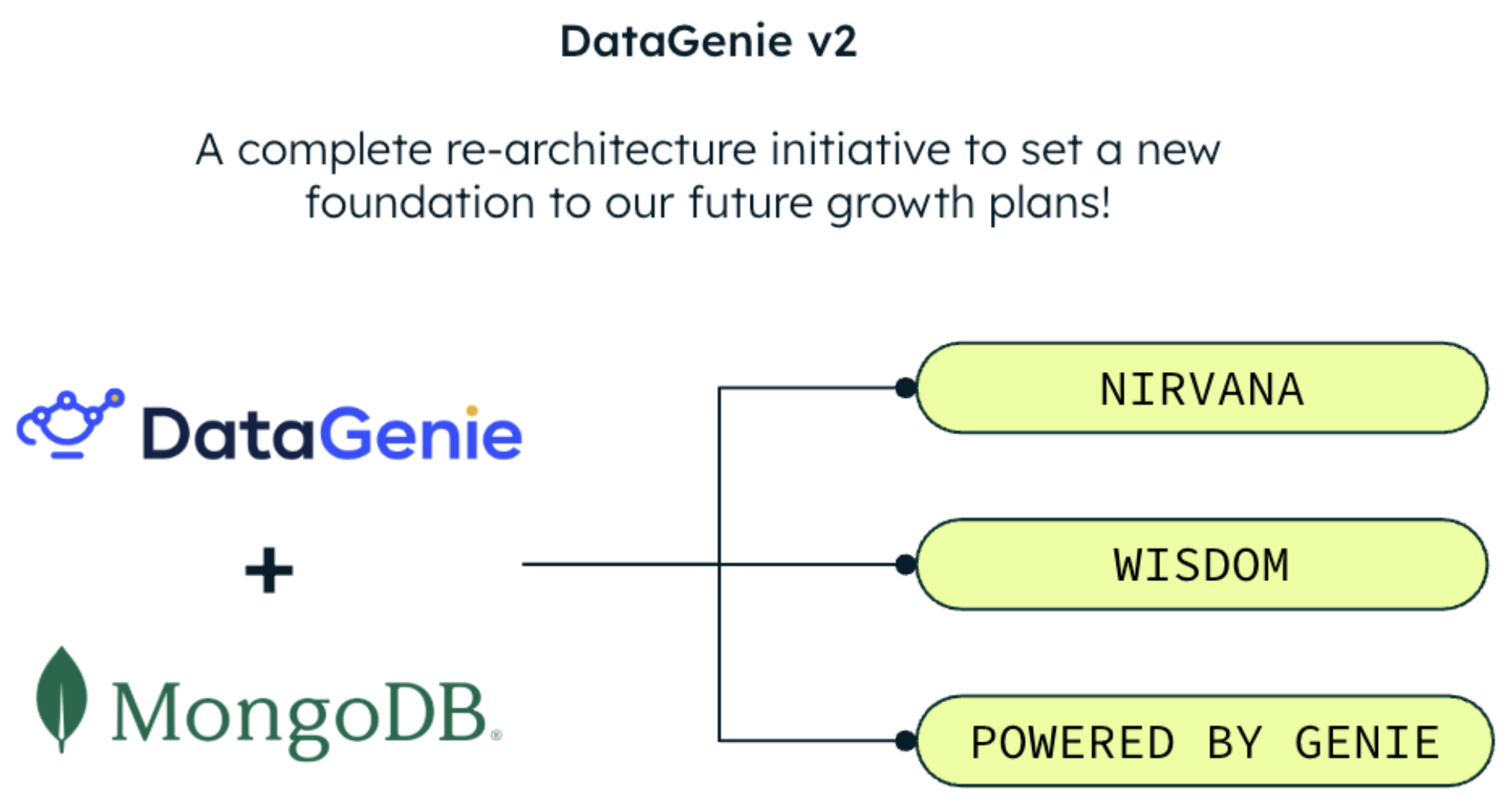
DataGenie engineering team refers v2 magic moment since migrating to MongoDB makes it a lot easier & flexible to roll out the following new features:
DataGenie Nirvana: A delay in the supply chain for a raw material can cascade into a revenue impact. Conventional analytics relies on complex ETL pipelines and data marts to unify disparate data and deliver connected dashboard metrics. DataGenie Nirvana eliminates the need for a centralized data lake by independently generating aggregate metrics from each source and applying advanced correlation and causation algorithms on aggregated data to detect hidden connections.
DataGenie Wisdom: Wisdom leverages an agentic framework & knowledge stores, to achieve two outcomes:
Guided onboarding: Onboarding a new use case in DataGenie is as simple as explaining the business problem, success criteria, and sharing sample data – DataGenie autonomously configures itself for relevant metrics tracking to deliver the desired outcome.
Next best action: DataGenie autonomously surfaces insights – like a 10% brand adoption spike in a specific market and customer demographics. By leveraging enterprise knowledge bases and domain-specific learning, DataGenie would propose targeted marketing campaigns as the Next Best Action for this insight.
Powered by Genie: DataGenie offers powerful augmented analytics that can be quickly configured for any use case and integrated through secure, high-performance APIs. This powers data products in multiple verticals, including Healthcare & FinOps, to deliver compelling augmented analytics as a premium add-on, drastically reducing their engineering burden and GTM risk.
All of these advanced features require enormous schema flexibility, low latency aggregation, and a vector database that’s always in sync with the metrics & insights. That’s exactly what we get with MongoDB!
Powered by MongoDB Atlas, DataGenie delivers actionable insights to enterprises, helping them unlock new revenue potential and reduce costs. The following are some of the DataGenie use cases in Retail:
Demand shifts & forecasting: Proactively adjust inventory or revise marketing strategies based on product demand changes.
Promotional effectiveness: Optimize marketing spend by understanding which promotions resonate with which customer segments.
Customer segmentation & personalization: Personalize offers based on customer behavior and demographics.
Supply chain & logistics: Minimize disruptions by identifying potential bottlenecks and proposing alternative solutions.
Inventory optimization: Streamline inventory management by flagging potential stockouts or overstock.
Fraud & loss prevention: Detect anomalies in transaction data that may signal fraud or errors.
Customer retention & loyalty: Propose retention strategies to address customer churn.
Staffing optimization: Optimize customer support staffing.
Final thoughts
Migrating to MongoDB did more than just solve DataGenie’s scalability and latency challenges – it unlocked new possibilities. The flexibility of MongoDB allowed DataGenie to innovate faster and conceptualize new features such as Nirvana, Wisdom, and ultra-efficient microservices.
This transformation stands as a proof of concept for future product companies considering partnering with MongoDB. The partnership between DataGenie and MongoDB is a testament to how the right technology choices can drive massive business value, improving performance, scalability, and cost-efficiency.
Ready to unlock deeper retail insights? Head over to our retail page to learn more.
Check out our Atlas Learning Hub to boost your MongoDB skills.
Source: Read More

