


Multimodal reasoning is an evolving field that integrates visual and textual data to enhance machine intelligence. Traditional artificial intelligence models excel at processing either text or images but often struggle when required to reason across both formats. Analyzing charts, graphs, mathematical symbols, and complex visual patterns alongside textual descriptions is crucial for applications in education, scientific problem-solving, and autonomous decision-making. Despite advancements in language models, their limitations in multimodal reasoning remain a significant challenge. Developing AI systems that can bridge the gap between perception and reasoning is a key focus for researchers aiming to improve the logical interpretation of mixed-data inputs.
A primary issue in multimodal reasoning is the inability of existing AI models to perform structured, logical inference when analyzing images. While large language models demonstrate strong reasoning capabilities in textual contexts, they fail to derive conclusions from visual information accurately. This shortcoming is evident in tasks that require a combination of perception and step-by-step reasoning, such as solving visual mathematics problems, interpreting diagrams, or understanding scientific schematics. Current models often ignore images’ deeper contextual meaning or rely on superficial pattern recognition rather than detailed logical analysis. Without a robust method for systematically integrating image and text data, these models continue to underperform on reasoning-based tasks.
Several techniques have been proposed to improve multimodal reasoning but exhibit significant limitations. Some models use predefined thinking templates that attempt to structure reasoning in a rigid format, restricting flexibility in problem-solving. Others rely on direct imitation of human-annotated responses, which enables them to generate plausible-sounding answers but cannot generalize beyond familiar examples. These approaches fail when encountering novel problems that require adaptive reasoning. Moreover, the absence of comprehensive benchmarks for evaluating multimodal reasoning capabilities prevents accurate performance assessment, making it difficult to determine the true effectiveness of new AI models.
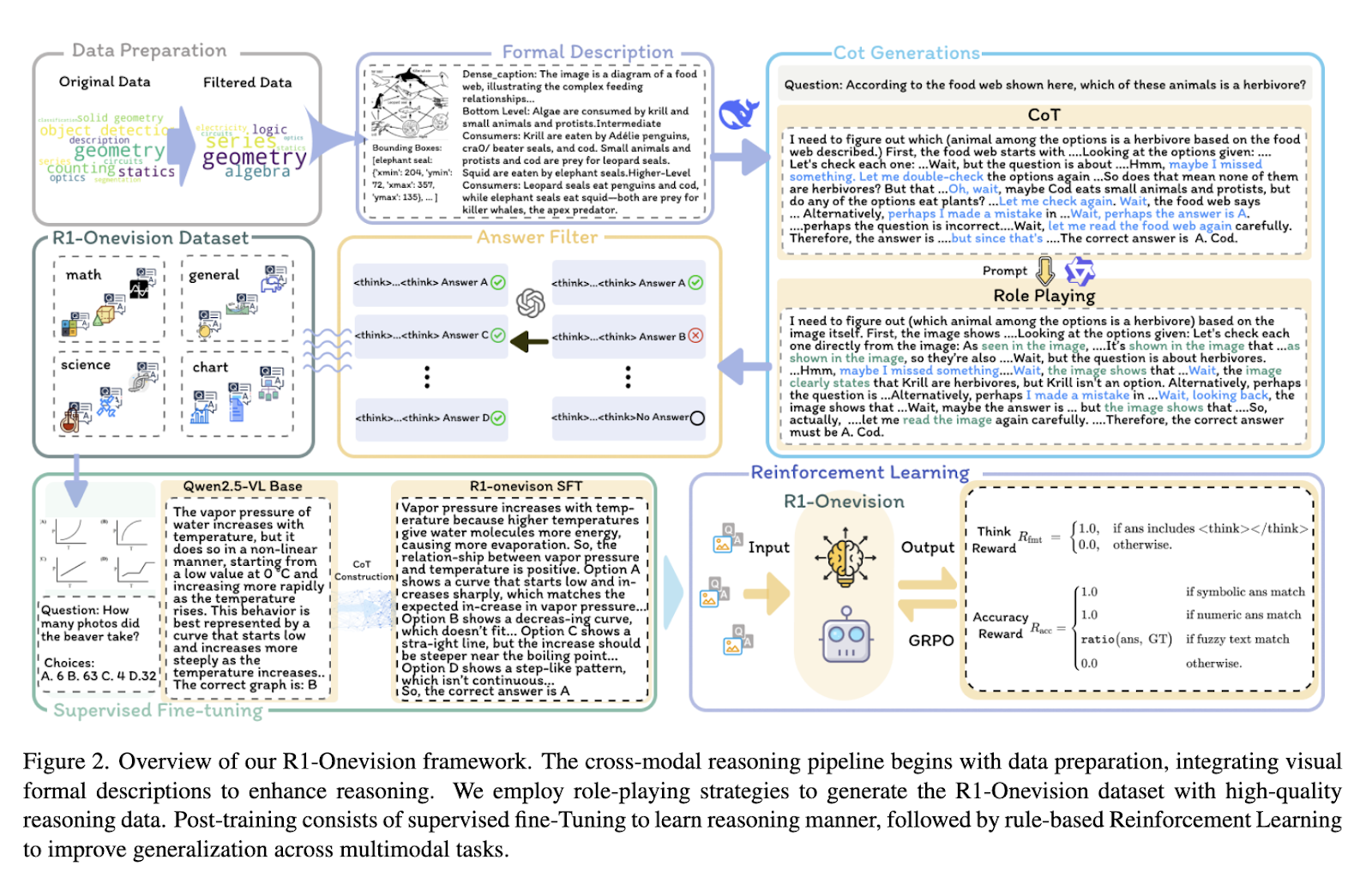
To address these issues, researchers from Zhejiang University, Tencent Inc., and Renmin University of China introduced R1-Onevision. The model is designed to bridge the gap between visual perception and structured reasoning by implementing a cross-modal formalization technique. Instead of relying solely on image-based feature extraction, the model converts visual content into structured textual representations, allowing it to process images with the same depth as textual data. This approach enables the model to conduct step-by-step logical inference, significantly improving its ability to analyze complex visual information. The researchers aim to enhance the model’s decision-making accuracy across various tasks by integrating structured reasoning pathways.
The methodology behind R1-Onevision consists of a multi-stage process that strengthens reasoning capabilities at different levels. A cross-modal reasoning pipeline initially extracts structured descriptions from images, transforming them into precise textual representations. This enables the model to conduct language-based reasoning on visual data. The dataset developed for training, called R1-Onevision-Bench, includes diverse visual reasoning problems from subjects such as mathematics, physics, and logic-based deduction. The researchers applied supervised fine-tuning (SFT) to establish structured thinking patterns in the model. Reinforcement learning (RL) was incorporated to improve performance further, allowing the model to refine its reasoning through iterative training on increasingly complex problems. This combination of structured data transformation, supervised training, and reinforcement optimization ensures that the model develops a more reliable problem-solving process.

Experimental evaluations show that R1-Onevision achieves superior results to leading multimodal models, including GPT-4o and Qwen2.5-VL. On the MathVision benchmark, it attained an accuracy of 29.9%, surpassing several open-source alternatives. When tested on MathVerse, it achieved 46.4% accuracy for standard problems and 40.0% for vision-only challenges. Further, on the MathVista benchmark, R1-Onevision outperformed its predecessors by 4.1%, demonstrating its effectiveness in structured visual reasoning. The model also showed strong generalization across diverse test conditions, indicating that integrating cross-modal formalization significantly improves problem-solving accuracy. These results highlight the impact of structured reasoning pathways in multimodal AI, providing a clear advantage over previous approaches.
The introduction of R1-Onevision represents a significant advancement in multimodal reasoning. By addressing key challenges in visual-text integration, the researchers have developed a model capable of reasoning across diverse problem types with higher accuracy. The use of cross-modal formalization not only enhances logical inference but also lays the foundation for future developments in AI-driven problem-solving. As AI continues to evolve, models like R1-Onevision demonstrate the importance of structured reasoning in improving machine intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
The post This AI Paper Introduces R1-Onevision: A Cross-Modal Formalization Model for Advancing Multimodal Reasoning and Structured Visual Interpretation appeared first on MarkTechPost.
Source: Read MoreÂ

