




Large-scale reinforcement learning (RL) training of language models on reasoning tasks has become a promising technique for mastering complex problem-solving skills. Currently, methods like OpenAI’s o1 and DeepSeek’s R1-Zero, have demonstrated remarkable training time scaling phenomenon. Both models’ benchmark performance and response length consistently and steadily increase without any sign of saturation as the training computation scales up. Inspired by these advancements, researchers in this paper have explored this new scaling phenomenon by conducting large-scale RL training directly on base models and referred to this approach as Reasoner-Zero training.
Researchers from StepFun and Tsinghua University have proposed Open-Reasoner-Zero (ORZ), an open-source implementation of large-scale reasoning-oriented RL training for language models. It represents a significant advancement in making advanced RL training techniques accessible to the broader research community. ORZ enhances diverse reasoning skills under verifiable rewards, including arithmetic, logic, coding, and common-sense reasoning tasks. It addresses critical challenges in training stability, response length optimization, and benchmark performance improvements through a comprehensive training strategy. Unlike previous approaches that provided limited implementation details, ORZ offers detailed insights into its methodology and best practices.
The ORZ framework utilizes the Qwen2.5-{7B, 32B} as the base model, and implements direct large-scale RL training without preliminary fine-tuning steps. The system leverages a scaled-up version of the standard PPO algorithm, optimized specifically for reasoning-oriented tasks. The training dataset consists of carefully curated question-answer pairs focusing on STEM, Math, and diverse reasoning tasks. The architecture incorporates a specialized prompt template designed to enhance inference computation capabilities. The implementation is built on OpenRLHF, featuring significant improvements including a flexible trainer, GPU collocation generation, and advanced offload-backload support mechanisms for efficient large-scale training.
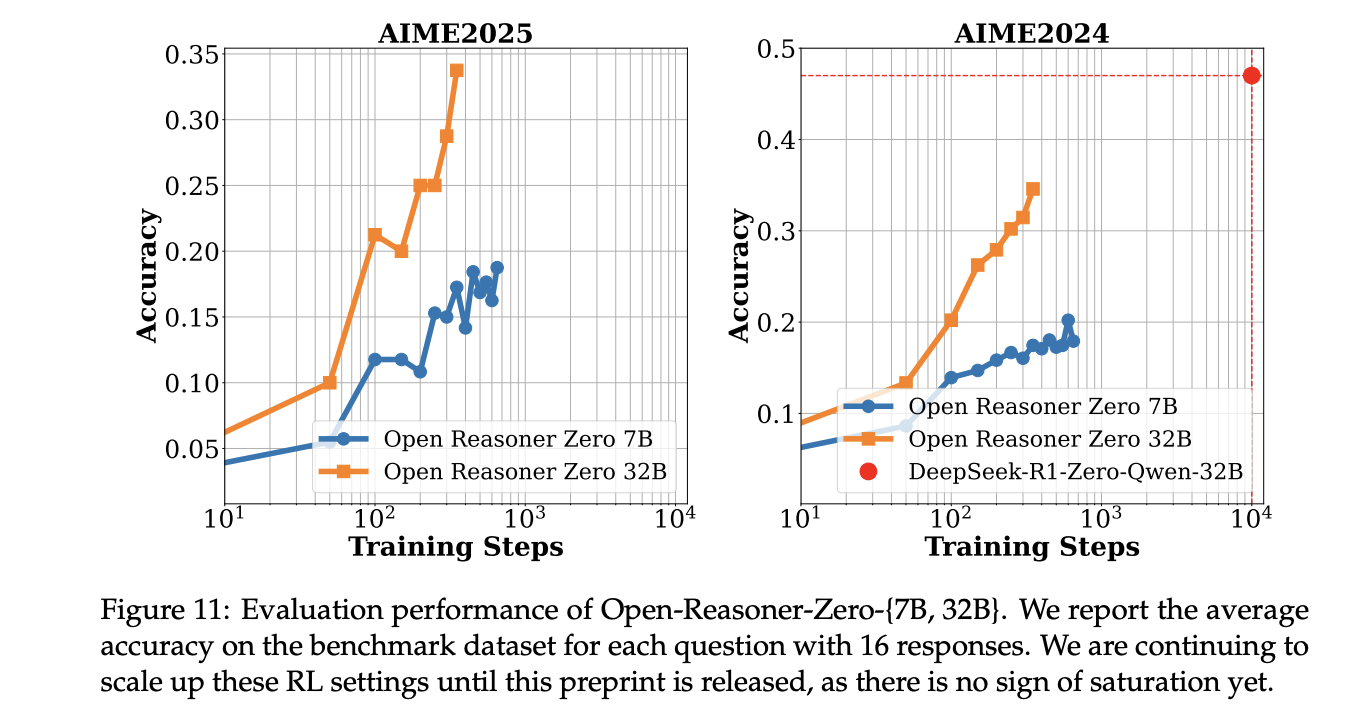
The training results demonstrate significant performance improvements across multiple metrics for both the 7B and 32B variants of Open-Reasoner-Zero. Training curves reveal consistent enhancements in reward metrics and response lengths, with a notable “step moment” phenomenon indicating sudden improvements in reasoning capabilities. During Response Length Scale-up vs DeepSeek-R1-Zero, the Open-Reasoner-Zero-32B model achieves comparable response lengths to DeepSeek-R1-Zero (671B MoE) with only 1/5.8 of the training steps. This efficiency validates the effectiveness of the minimalist approach to large-scale RL training.
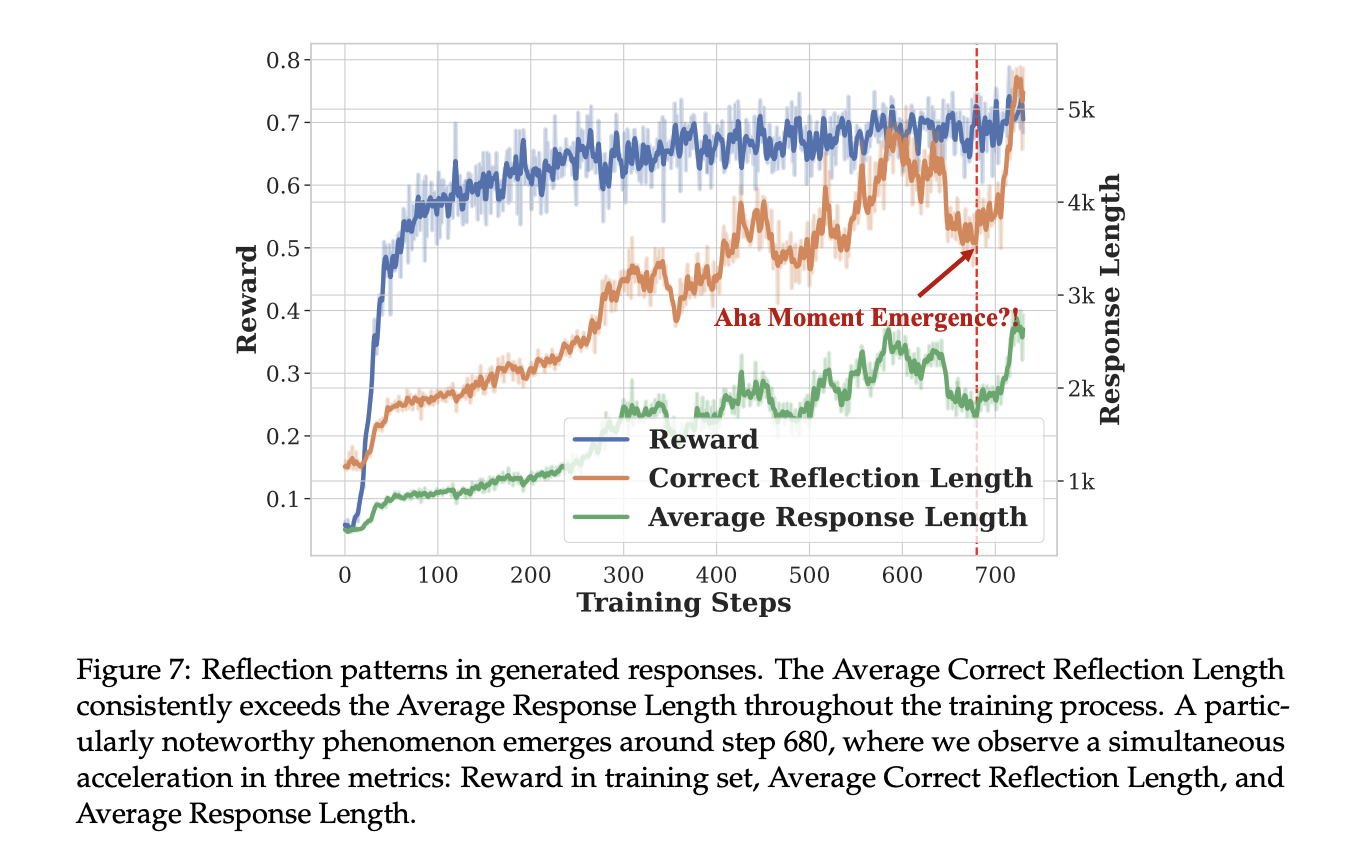
The main experimental results show that Open-Reasoner-Zero performs exceptionally well across multiple evaluation metrics, particularly in the 32B configuration. It achieves superior results compared to DeepSeek-R1-Zero-Qwen2.5-32B on the GPQA DIAMOND benchmark while requiring only 1/30 of the training steps, showcasing remarkable training efficiency. Moreover, the 7B variant exhibits interesting learning dynamics, with steady accuracy improvements and dramatic response length growth patterns. A distinctive “step moment” phenomenon has been observed during evaluation, characterized by sudden increases in both reward and response length, particularly evident in GPQA DIAMOND and AIME2024 benchmarks.
In this paper, researchers introduced Open-Reasoner-Zero, representing a significant milestone in democratizing large-scale reasoning-oriented RL training for language models. The research shows that a simplified approach using vanilla PPO with GAE and rule-based reward functions can achieve competitive results compared to more complex systems. The successful implementation without KL regularization proves that complex architectural modifications may not be necessary for achieving strong reasoning capabilities. By open-sourcing the complete training pipeline and sharing detailed insights, this work establishes a foundation for future research in scaling language model reasoning abilities, and this is just the beginning of a new scaling trend in AI development.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Open-Reasoner-Zero: An Open-source Implementation of Large-Scale Reasoning-Oriented Reinforcement Learning Training appeared first on MarkTechPost.
Source: Read MoreÂ
