




The ambition to accelerate scientific discovery through AI has been longstanding, with early efforts such as the Oak Ridge Applied AI Project dating back to 1979. More recent advancements in foundation models have demonstrated the feasibility of fully automated research pipelines, enabling AI systems to autonomously conduct literature reviews, formulate hypotheses, design experiments, analyze results, and even generate scientific papers. Additionally, they can streamline scientific workflows by automating repetitive tasks, allowing researchers to focus on higher-level conceptual work. However, despite these promising developments, the evaluation of AI-driven research remains challenging due to the lack of standardized benchmarks that can comprehensively assess their capabilities across different scientific domains.
Recent studies have addressed this gap by introducing benchmarks that evaluate AI agents on various software engineering and machine learning tasks. While frameworks exist to test AI agents on well-defined problems like code generation and model optimization, most current benchmarks do not fully support open-ended research challenges, where multiple solutions could emerge. Furthermore, these frameworks often lack flexibility in assessing diverse research outputs, such as novel algorithms, model architectures, or predictions. To advance AI-driven research, there is a need for evaluation systems that incorporate broader scientific tasks, facilitate experimentation with different learning algorithms, and accommodate various forms of research contributions. By establishing such comprehensive frameworks, the field can move closer to realizing AI systems capable of independently driving meaningful scientific progress.
Researchers from the University College London, University of Wisconsin–Madison, University of Oxford, Meta, and other institutes have introduced a new framework and benchmark for evaluating and developing LLM agents in AI research. This system, the first Gym environment for ML tasks, facilitates the study of RL techniques for training AI agents. The benchmark, MLGym-Bench, includes 13 open-ended tasks spanning computer vision, NLP, RL, and game theory, requiring real-world research skills. A six-level framework categorizes AI research agent capabilities, with MLGym-Bench focusing on Level 1: Baseline Improvement, where LLMs optimize models but lack scientific contributions.
MLGym is a framework designed to evaluate and develop LLM agents for ML research tasks by enabling interaction with a shell environment through sequential commands. It comprises four key components: Agents, Environment, Datasets, and Tasks. Agents execute bash commands, manage history, and integrate external models. The environment provides a secure Docker-based workspace with controlled access. Datasets are defined separately from tasks, allowing reuse across experiments. Tasks include evaluation scripts and configurations for diverse ML challenges. Additionally, MLGym offers tools for literature search, memory storage, and iterative validation, ensuring efficient experimentation and adaptability in long-term AI research workflows.
The study employs a SWE-Agent model designed for the MLGYM environment, following a ReAct-style decision-making loop. Five state-of-the-art models—OpenAI O1-preview, Gemini 1.5 Pro, Claude-3.5-Sonnet, Llama-3-405b-Instruct, and GPT-4o—are evaluated under standardized settings. Performance is assessed using AUP scores and performance profiles, comparing models based on Best Attempt and Best Submission metrics. OpenAI O1-preview achieves the highest overall performance, with Gemini 1.5 Pro and Claude-3.5-Sonnet closely following. The study highlights performance profiles as an effective evaluation method, demonstrating that OpenAI O1-preview consistently ranks among the top models across various tasks.
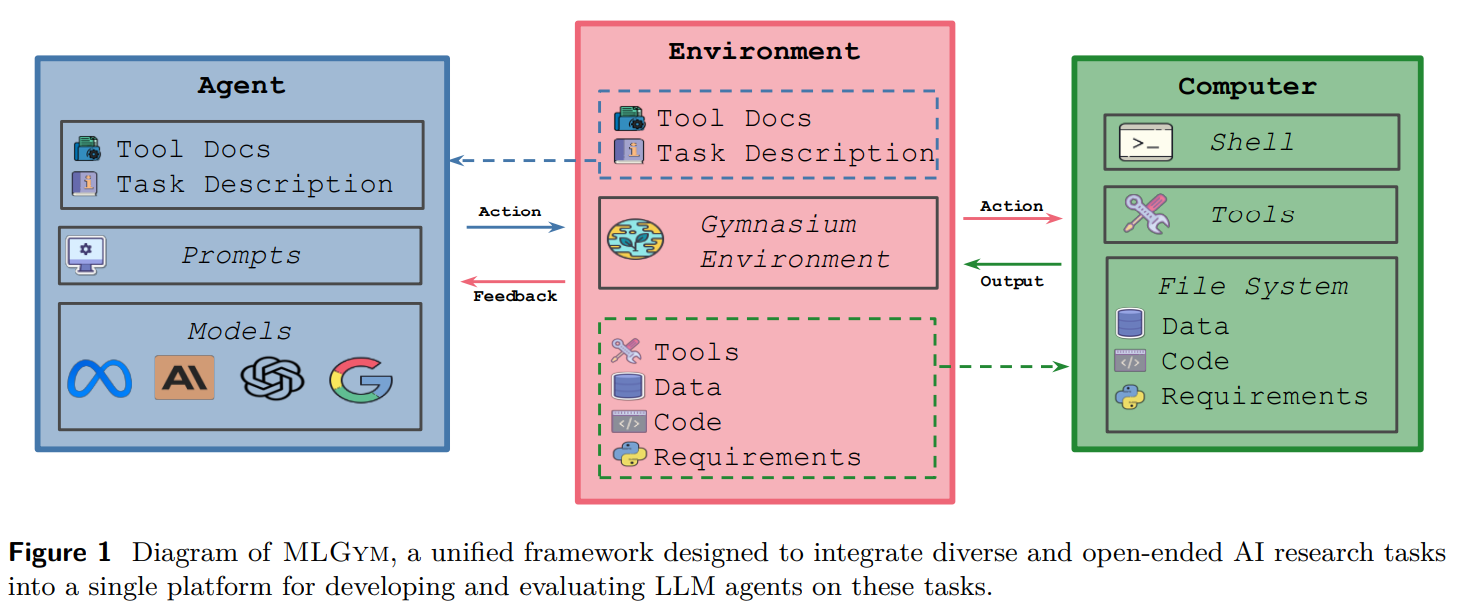
In conclusion, the study highlights the potential and challenges of using LLMs as scientific workflow agents. MLGym and MLGymBench demonstrate adaptability across various quantitative tasks but reveal improvement gaps. Expanding beyond ML, testing interdisciplinary generalization, and assessing scientific novelty are key areas for growth. The study emphasizes the importance of data openness to enhance collaboration and discovery. As AI research progresses, advancements in reasoning, agent architectures, and evaluation methods will be crucial. Strengthening interdisciplinary collaboration can ensure that AI-driven agents accelerate scientific discovery while maintaining reproducibility, verifiability, and integrity.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Meta AI Introduces MLGym: A New AI Framework and Benchmark for Advancing AI Research Agents appeared first on MarkTechPost.
Source: Read MoreÂ

