




Large Language Models (LLMs) face significant challenges in complex reasoning tasks, despite the breakthrough advances achieved through Chain-of-Thought (CoT) prompting. The primary challenge lies in the computational overhead introduced by longer CoT sequences, which directly impacts inference latency and memory requirements. The autoregressive nature of LLM decoding means that as CoT sequences grow longer, there is a proportional increase in processing time and memory usage in attention layers where computational costs scale quadratically. Finding a balance between maintaining reasoning accuracy and computational efficiency has become a critical challenge, as attempts to reduce reasoning steps often compromise the model’s problem-solving capabilities.
Various methodologies have been developed to address the computational challenges of Chain-of-Thought (CoT) reasoning. Some approaches focus on streamlining the reasoning process by simplifying or skipping certain thinking steps, while others attempt to generate steps in parallel. A different strategy involves compressing reasoning steps into continuous latent representations, enabling LLMs to reason without generating explicit word tokens. Moreover, prompt compression techniques to handle complex instructions and long-context inputs more efficiently range from using lightweight language models to generate concise prompts, employing implicit continuous tokens for task representation, and implementing direct compression by filtering for high-informative tokens.
Researchers from The Hong Kong Polytechnic University and the University of Science and Technology of China have proposed TokenSkip, an approach to optimize CoT processing in LLMs. It enables models to skip less important tokens within CoT sequences while maintaining connections between critical reasoning tokens, with adjustable compression ratios. The system works by first constructing compressed CoT training data through token pruning, followed by a supervised fine-tuning process. Initial testing across multiple models, including LLaMA-3.1-8B-Instruct and Qwen2.5-Instruct series shows promising results, particularly in maintaining reasoning capabilities while significantly reducing computational overhead.
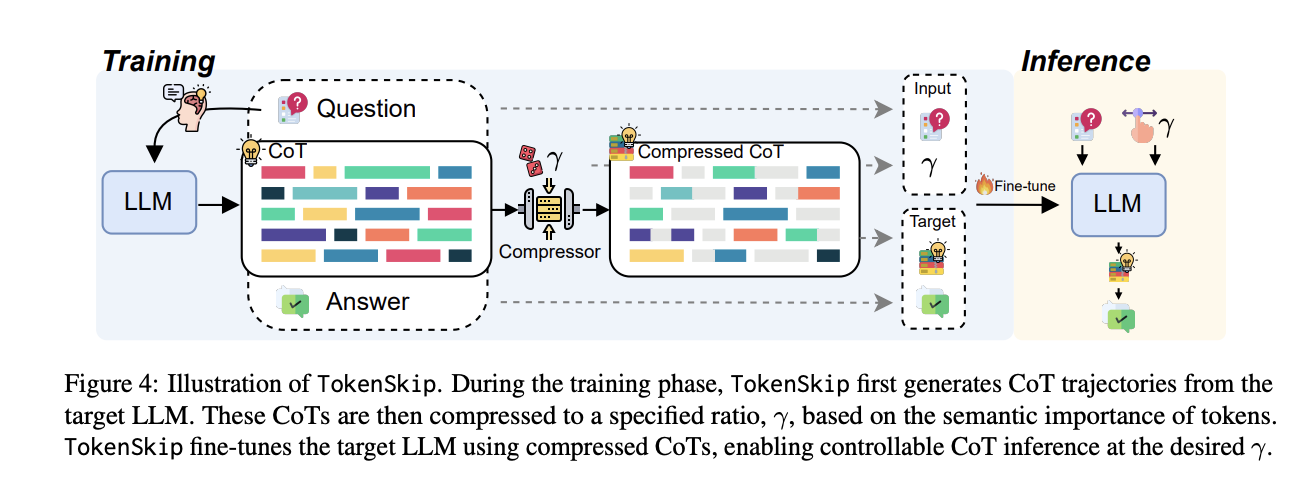
TokenSkip’s architecture is built on the fundamental principle that different reasoning tokens contribute varying levels of importance to reaching the final answer. It contains two main phases: training data preparation and inference. In the training phase, the system generates CoT trajectories using the target LLM, and Each remaining trajectory undergoes pruning with a randomly selected compression ratio. The token pruning process is guided by an “importance scoring” mechanism. TokenSkip maintains the autoregressive decoding approach during inference but enhances efficiency by enabling LLMs to skip less important tokens. The structure of the input format is such that the question and compression ratio gets separated by end-of-sequence tokens.
The results show that larger language models are more adept at maintaining performance while achieving higher compression rates. The Qwen2.5-14B-Instruct model achieves remarkable results with only a 0.4% performance drop while reducing token usage by 40%. TokenSkip shows superior performance when compared with alternative approaches like prompt-based reduction and truncation. While prompt-based reduction fails to achieve target compression ratios and truncation leads to significant performance degradation, TokenSkip maintains the specified compression ratio while preserving reasoning capabilities. On the MATH-500 dataset, it achieves a 30% reduction in token usage with less than a 4% performance drop.
In this paper, researchers introduced TokenSkip which represents a significant advancement in optimizing CoT processing for LLMs by introducing a controllable compression mechanism based on token importance. The method’s success lies in maintaining reasoning accuracy while significantly reducing computational overhead by selectively preserving critical tokens and skipping less important ones. The approach has proven effective with LLMs, showing minimal performance degradation even at substantial compression ratios. This research opens new possibilities for advancing efficient reasoning in LLMs, establishing a foundation for future developments in computational efficiency while maintaining robust reasoning capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post TokenSkip: Optimizing Chain-of-Thought Reasoning in LLMs Through Controllable Token Compression appeared first on MarkTechPost.
Source: Read MoreÂ
