




Organizations face significant challenges when deploying LLMs in today’s technology landscape. The primary issues include managing the enormous computational demands required to process high volumes of data, achieving low latency, and ensuring optimal balance between CPU-intensive tasks, such as scheduling and memory allocation, and GPU-intensive computations. Repeatedly processing similar inputs further compounds the inefficiencies in many systems, leading to redundant computations that slow down overall performance. Also, generating structured outputs like JSON or XML in real-time introduces further delays, making it difficult for applications to deliver fast, reliable, cost-effective performance at scale.
SGLang is an open-source inference engine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. Its design utilizes an innovative approach that reduces redundant computations and enhances overall efficiency, thereby enabling organizations to manage better the complexities associated with LLM deployment.
RadixAttention is central to SGLang, which reuses shared prompt prefixes across multiple requests. This approach effectively minimizes the repeated processing of similar input sequences, improving throughput. The technique is advantageous in conversational interfaces or retrieval-augmented generation applications, where similar prompts are frequently processed. By eliminating redundant computations, the system ensures that resources are used more efficiently, contributing to faster processing times and more responsive applications.
Another critical feature of SGLang is its zero-overhead batch scheduler. Earlier inference systems often suffer from significant CPU overhead due to tasks like batch scheduling, memory allocation, and prompt preprocessing. In many cases, these operations result in idle periods for the GPU, which in turn hampers overall performance. SGLang addresses this bottleneck by overlapping CPU scheduling with ongoing GPU computations. The scheduler keeps the GPUs continuously engaged by running one batch ahead and preparing all necessary metadata for the next batch. Profiling has shown that this design reduces idle time and achieves measurable speed improvements, especially in configurations that involve smaller models and extensive tensor parallelism.
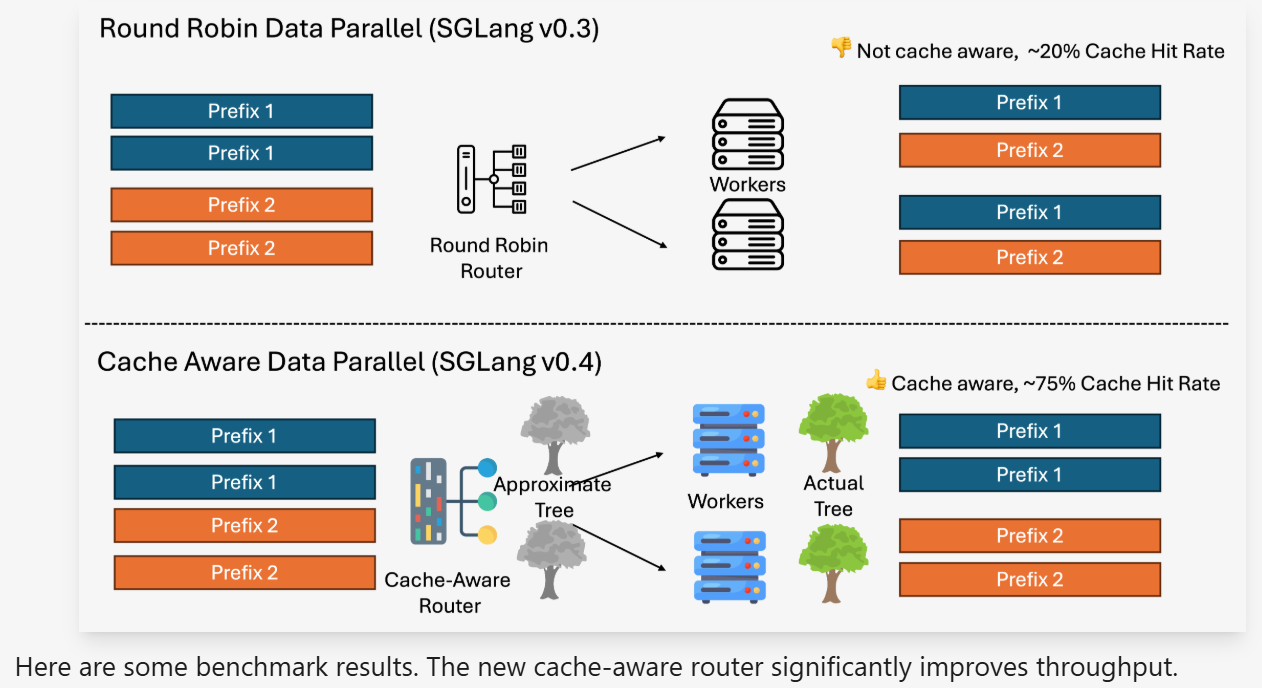
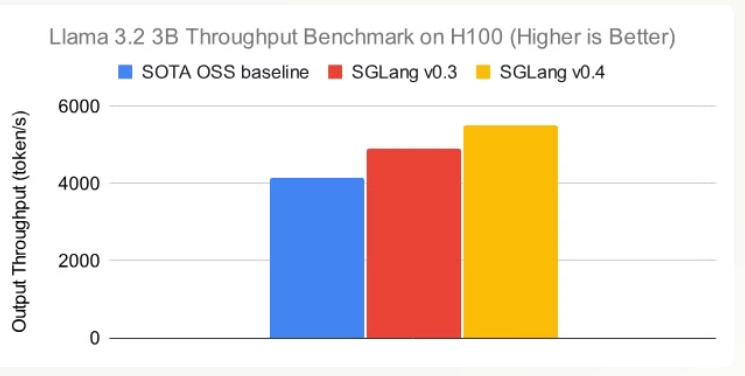
SGLang also incorporates a cache-aware load balancer that departs from conventional load balancing methods such as round-robin scheduling. Traditional techniques often ignore the state of the key-value (KV) cache, leading to inefficient resource use. In contrast, SGLang’s load balancer predicts the cache hit rates of different workers and directs incoming requests to those with the highest likelihood of a cache hit. This targeted routing increases throughput and enhances cache utilization. The mechanism relies on an approximate radix tree that reflects the current cache state on each worker, and it lazily updates this tree to impose minimal overhead. The load balancer, implemented in Rust for high concurrency, is especially well suited for distributed, multi-node environments.
In addition to these features, SGLang supports data parallelism attention, a strategy particularly tailored for DeepSeek models. While many modern models use tensor parallelism, which can lead to duplicated KV cache storage when scaling across multiple GPUs, SGLang employs a different method for models utilizing multi-head latent attention. In this approach, individual data parallel workers independently handle various batches, such as prefill, decode, or idle. The attention-processed data is then aggregated across workers before passing through subsequent layers, such as a mixture-of-experts layer, and later redistributed.
SGLang also excels in the efficient generation of structured outputs. Many inference systems struggle with the real-time decoding of formats like JSON, which can be a critical requirement in many applications. SGLang addresses this by integrating a specialized grammar backend known as xgrammar. This integration streamlines the decoding process, allowing the system to generate structured outputs up to ten times faster than other open-source alternatives. This capability is especially valuable when rapidly producing machine-readable data, essential for downstream processing or interactive applications.
Several high-profile companies have recognized SGLang’s practical benefits. For example, ByteDance channels a large portion of its internal NLP pipelines through this engine, processing petabytes of data daily. Similarly, xai has reported substantial cost savings by leveraging optimized scheduling and effective cache management, resulting in a notable reduction in serving expenses. These real-world applications highlight SGLang’s ability to operate efficiently at scale, delivering performance improvements and cost benefits.
SGLang is released under the Apache 2.0 open-source license and is accessible for academic research and commercial applications. Its compatibility with OpenAI standards and the provision of a Python API allows developers to integrate it seamlessly into existing workflows. The engine supports many models, including popular ones such as Llama, Mistral, Gemma, Qwen, DeepSeek, Phi, and Granite. It is designed to work across various hardware platforms, including NVIDIA and AMD GPUs, and integrates advanced quantization techniques like FP8 and INT4. Future enhancements will include FP6 weight and FP8 activation quantization, faster startup times, and cross-cloud load balancing.
Several Key Takeaways from the research on SGLang include:
- SGLang addresses critical challenges in deploying large language models by optimizing the balance between CPU and GPU tasks.
- RadixAttention minimizes redundant computations, improving throughput in conversational and retrieval scenarios.
- A zero-overhead batch scheduler overlaps CPU scheduling with GPU operations to ensure continuous processing and reduce idle time.
- A cache-aware load balancer efficiently predicts cache hit rates and routes requests, boosting overall performance and cache utilization.
- Data parallelism attention reduces memory overhead and enhances decoding throughput for multi-head latent attention models.
- The integration of xgrammar allows for the rapid generation of structured outputs, significantly improving processing speed for formats like JSON.
- SGLang’s practical benefits are demonstrated by its adoption in large-scale production environments, which contribute to substantial cost savings and performance improvements.
Check out the GitHub Repo, Documentation and Technical Details. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post SGLang: An Open-Source Inference Engine Transforming LLM Deployment through CPU Scheduling, Cache-Aware Load Balancing, and Rapid Structured Output Generation appeared first on MarkTechPost.
Source: Read MoreÂ

