




Large Language models (LLMs) operate by predicting the next token based on input data, yet their performance suggests they process information beyond mere token-level predictions. This raises questions about whether LLMs engage in implicit planning before generating complete responses. Understanding this phenomenon can lead to more transparent AI systems, improving efficiency and making output generation more predictable.
One challenge in working with LLMs is predicting how they will structure responses. These models generate text sequentially, making controlling the overall response length, reasoning depth, and factual accuracy challenging. The lack of explicit planning mechanisms means that although LLMs generate human-like responses, their internal decision-making remains opaque. As a result, users often rely on prompt engineering to guide outputs, but this method lacks precision and does not provide insight into the model’s inherent response formulation.
Existing techniques to refine LLM outputs include reinforcement learning, fine-tuning, and structured prompting. Researchers have also experimented with decision trees and external logic-based frameworks to impose structure. However, these methods do not fully capture how LLMs internally process information.

The Shanghai Artificial Intelligence Laboratory research team has introduced a novel approach by analyzing hidden representations to uncover latent response-planning behaviors. Their findings suggest that LLMs encode key attributes of their responses even before the first token is generated. The research team examined their hidden representations and investigated whether LLMs engage in emergent response planning. They introduced simple probing models trained on prompt embeddings to predict upcoming response attributes. The study categorized response planning into three main areas: structural attributes, such as response length and reasoning steps, content attributes including character choices in story-writing tasks, and behavioral attributes, such as confidence in multiple-choice answers. By analyzing patterns in hidden layers, the researchers found that these planning abilities scale with model size and evolve throughout the generation process.
To quantify response planning, the researchers conducted a series of probing experiments. They trained models to predict response attributes using hidden state representations extracted before output generation. The experiments showed that probes could accurately predict upcoming text characteristics. The findings indicated that LLMs encode response attributes in their prompt representations, with planning abilities peaking at the beginning and end of responses. The study further demonstrated that models of different sizes share similar planning behaviors, with larger models exhibiting more pronounced predictive capabilities.
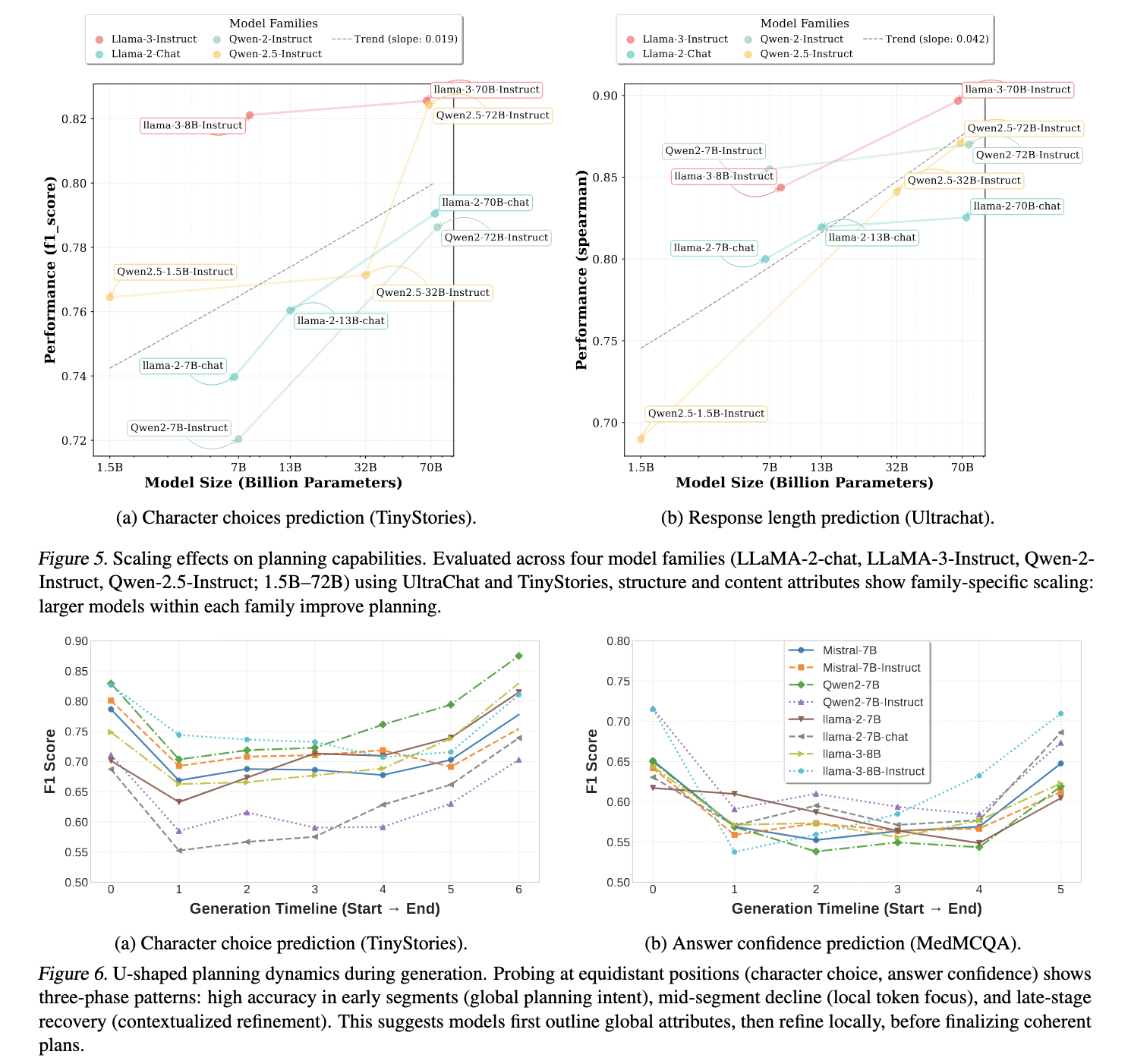
The experiments revealed substantial differences in planning capabilities between base and fine-tuned models. Fine-tuned models exhibited better prediction accuracy in structural and behavioral attributes, confirming that planning behaviors are reinforced through optimization. For instance, response length prediction showed high correlation coefficients across models, with Spearman’s correlation reaching 0.84 in some cases. Similarly, reasoning step predictions exhibited strong alignment with ground-truth values. Classification tasks such as character choice in story writing and multiple-choice answer selection performed significantly above random baselines, further supporting the notion that LLMs internally encode elements of response planning.
Larger models demonstrated superior planning abilities across all attributes. Within the LLaMA and Qwen model families, planning accuracy improved consistently with increased parameter count. The study found that LLaMA-3-70B and Qwen2.5-72B-Instruct exhibited the highest prediction performance, while smaller models like Qwen2.5-1.5B struggled to encode long-term response structures effectively. Further, layer-wise probing experiments indicated that structural attributes emerged prominently in mid-layers, while content attributes became more pronounced in later layers. Behavioral attributes, such as answer confidence and factual consistency, remained relatively stable across different model depths.
These findings highlight a fundamental aspect of LLM behavior: they do not merely predict the next token but plan broader attributes of their responses before generating text. This emergent response planning ability has implications for improving model transparency and control. Understanding these internal processes can help refine AI models, leading to better predictability and reduced reliance on post-generation corrections. Future research may explore integrating explicit planning modules within LLM architectures to enhance response coherence and user-directed customization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post This AI Paper Explores Emergent Response Planning in LLMs: Probing Hidden Representations for Predictive Text Generation appeared first on MarkTechPost.
Source: Read MoreÂ

