




The field of large language models has long been dominated by autoregressive methods that predict text sequentially from left to right. While these approaches power today’s most capable AI systems, they face fundamental limitations in computational efficiency and bidirectional reasoning. A research team from China has now challenged the assumption that autoregressive modeling is the only path to achieving human-like language capabilities, introducing an innovative diffusion-based architecture called LLaDA that reimagines how language models process information.
Current language models operate through next-word prediction, requiring increasingly complex computations as context windows grow. This sequential nature creates bottlenecks in processing speed and limits effectiveness on tasks requiring reverse reasoning. For instance, traditional autoregressive models suffer from the reversal curse—a phenomenon where models trained to predict the next token struggle with backward logical tasks. Consider poetry completion:
- Forward Task (Autoregressive Strength): Given the prompt “Roses are red,” models easily continue with “violets are blue.”
- Reversal Task (Autoregressive Weakness): Given “violets are blue,” the same models often fail to recall “Roses are red” as the preceding line.
This directional bias stems from their training to predict text strictly left-to-right. While masked language models (like BERT) exist, they traditionally use fixed masking ratios, limiting their generative capabilities. The researchers propose LLaDA (Large Language Diffusion with mAsking), which implements a dynamic masking strategy across diffusion steps to overcome these constraints (Illustrated in Fig. 2). Unlike autoregressive models, LLaDA processes tokens in parallel through a bidirectional framework, learning contextual relationships in all directions simultaneously.
LLaDA’s architecture employs a transformer without causal masking, trained through two phases:
- Pre-training: The model learns to reconstruct randomly masked text segments across 2.3 trillion tokens. Imagine repairing a damaged manuscript where words vanish unpredictably—LLaDA practices filling gaps in any order. For example:
- Start with a masked sentence: “[MASK] are red, [MASK] are blue.”
- Predict “violets” for the second blank first, then “Roses” for the first.
- Repeated masking/unmasking cycles eliminate directional bias.
- Supervised Fine-Tuning: The model adapts to instruction-response pairs by masking only the response portion, enabling task-specific refinement while retaining bidirectional understanding.
During generation, LLaDA starts with fully masked output fields and iteratively refines predictions through confidence-based remasking:
- At each diffusion step, the model predicts all masked tokens simultaneously.
- Low-confidence predictions (e.g., uncertain words in a poem’s opening line) are remasked for re-evaluation.
- This “semantic annealing” process repeats until coherent text emerges.
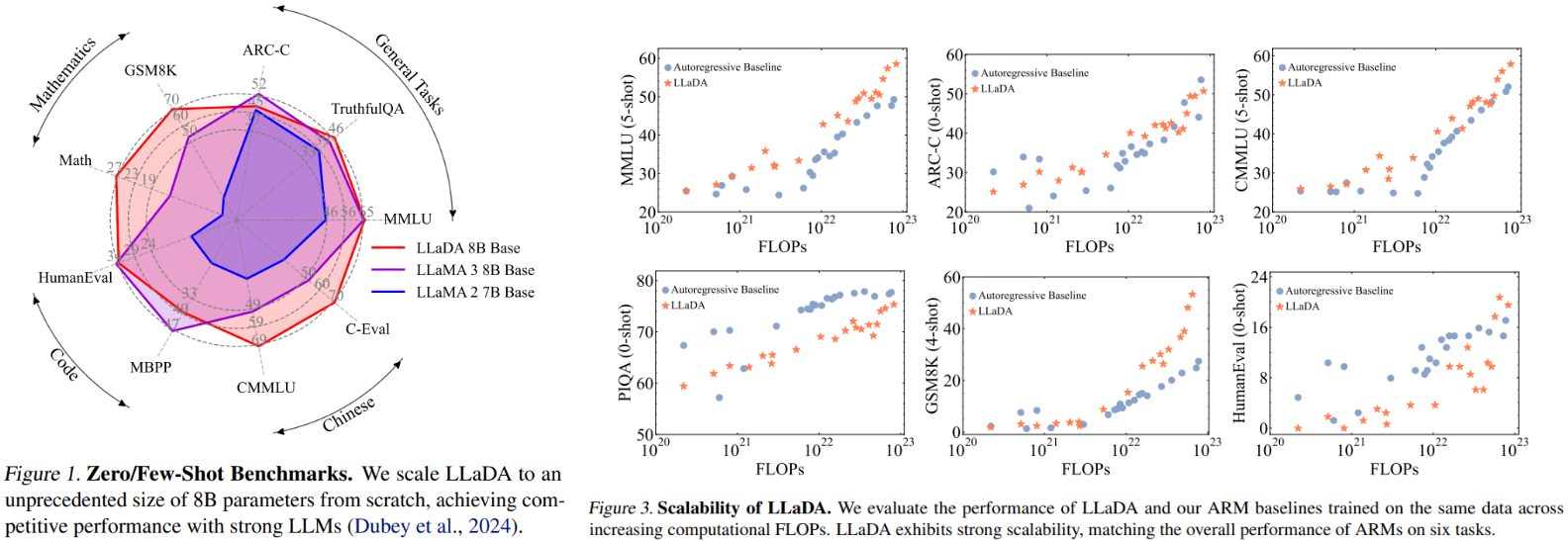
Performance evaluations reveal surprising capabilities. When scaled to 8 billion parameters, LLaDA matches or exceeds equivalent-sized autoregressive models like LLaMA2-7B across 15 benchmarks, excelling in mathematical reasoning (GSM8K) and Chinese tasks. Crucially, it overcomes the reversal curse:
- Achieved 42% accuracy on backward poem completion tasks vs. GPT-4’s 32%, while maintaining parity in forward generation.
- Demonstrated consistent performance on reversal QA tasks (e.g., “Who is Tom Cruise’s mother?” vs. “Who is Mary Lee Pfeiffer’s son?”), where autoregressive models often fail.
The model also shows efficient scaling—computational costs grow comparably to traditional architectures despite its novel approach. Notably, in tasks such as MMLU and GSM8K, LLaDA exhibits even stronger scalability.
In summary, this breakthrough suggests key language capabilities emerge from fundamental generative principles, not autoregressive designs alone. While current implementations lag slightly in tasks like MMLU (likely due to data quality variances), LLaDA establishes diffusion models as viable alternatives. The research opens doors to parallel generation and bidirectional reasoning, though challenges remain in inference optimization and alignment with human preferences. As the field explores these alternatives, we may be witnessing the early stages of a paradigm shift in how machines process language—one where models “think holistically” rather than being constrained to linear prediction.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post Breaking the Autoregressive Mold: LLaDA Proves Diffusion Models can Rival Traditional Language Architectures appeared first on MarkTechPost.
Source: Read MoreÂ

