




Large language models have demonstrated remarkable problem-solving capabilities and mathematical and logical reasoning. These models have been applied to complex reasoning tasks, including International Mathematical Olympiad (IMO) combinatorics problems, Abstraction and Reasoning Corpus (ARC) puzzles, and Humanity’s Last Exam (HLE) questions. Despite improvements, existing AI models often struggle with high-level problem-solving that requires abstract reasoning, formal verification, and adaptability. The growing demand for AI-driven problem-solving has led researchers to develop novel inference techniques that combine multiple methods and models to enhance accuracy and reliability.
The challenge with AI reasoning lies in verifying the correctness of solutions, particularly for mathematical problems requiring multiple steps and logical deductions. Traditional models perform well in straightforward arithmetic but struggle when faced with abstract concepts, formal proofs, and high-dimensional reasoning. An effective AI system must generate valid solutions while adhering to established mathematical principles. Current limitations have prompted researchers to explore advanced inference techniques that improve verification and enhance problem-solving reliability.

Several techniques have been implemented to address mathematical reasoning challenges. Zero-shot learning enables models to solve problems without prior exposure, while best-of-N sampling selects the most accurate solution from multiple generated responses. Monte Carlo Tree Search (MCTS) explores possible solutions through simulation, and theorem-proving software like Z3 assists in verifying logical statements. Despite their utility, these methods often lack robustness when faced with intricate problems requiring structured verification. This gap has led to the developing of a more comprehensive framework that integrates multiple inference strategies.
A team of researchers from Boston University, Google, Columbia University, MIT, Intuit, and Stanford introduced an innovative approach that combines diverse inference techniques with automatic verification. The research integrates test-time simulations, reinforcement learning, and meta-learning to enhance reasoning performance. By leveraging multiple models and problem-solving methodologies, the approach ensures that AI systems are not reliant on a single technique, thus increasing accuracy and adaptability. The system employs structured agent graphs to refine problem-solving pathways and adjust inference strategies based on task complexity.
The methodology revolves around verifying solutions for mathematical and logical problems through automated checks. For IMO problems, researchers implemented eight distinct methods, including LEAP, Z3, Monte Carlo Tree Search, and Plan Search, to translate English-based solutions into formal proofs within the Lean theorem-proving environment. This allows for absolute verification of correctness. ARC puzzles are addressed using synthesized code solutions, validated through unit testing against training examples. HLE questions involving broader reasoning categories leverage best-of-N sampling as an imperfect verifier to improve solution selection. Reinforcement learning and test-time meta-learning refine the inference process by adjusting agent graph representations based on prior problem-solving performance.
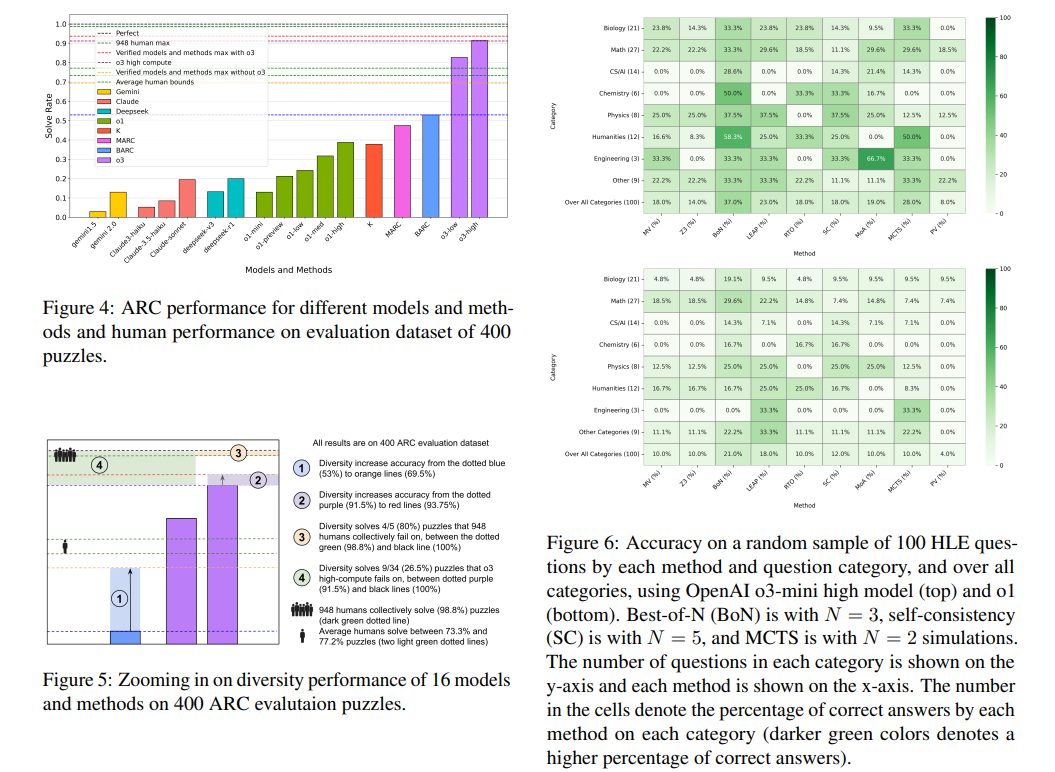
The performance of this approach demonstrated substantial improvements across multiple reasoning tasks. For IMO combinatorics problems, accuracy increased from 33.3% to 77.8%, showcasing a significant leap in AI capabilities for mathematical proof generation. Regarding HLE questions, accuracy rose from 8% to 37%, indicating enhanced problem-solving adaptability across multiple disciplines. The ARC puzzles, known for their complexity, saw an 80% success rate for previously unsolved problems attempted by 948 human participants. Further, the model successfully solved 26.5% of ARC puzzles that OpenAI’s o3 high-compute model failed to address. The research highlights the effectiveness of combining multiple inference models, demonstrating that aggregated methodologies outperform single-method approaches in complex reasoning tasks.
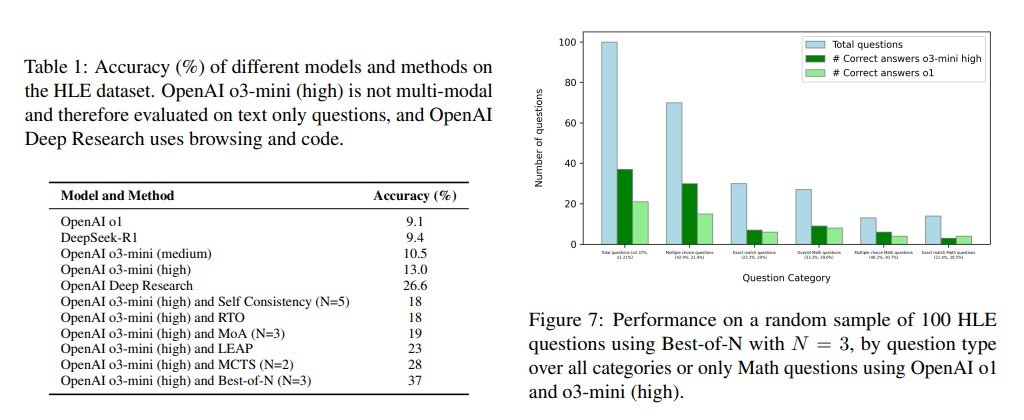
This study presents a transformative advancement in AI-driven reasoning by merging diverse inference strategies with automated verification systems. By leveraging multiple AI techniques and optimizing reasoning pathways through reinforcement learning, the research offers a scalable solution to complex problem-solving challenges. The results demonstrate that an AI system’s performance can be significantly enhanced through structured inference aggregation, paving the way for more sophisticated reasoning models in the future. This work contributes to AI’s broader application in mathematical problem-solving and logical verification, addressing fundamental challenges that have limited AI’s effectiveness in advanced reasoning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post This AI Paper Introduces Diverse Inference and Verification: Enhancing AI Reasoning for Advanced Mathematical and Logical Problem-Solving appeared first on MarkTechPost.
Source: Read MoreÂ

