




Large language models (LLMs) process extensive datasets to generate coherent outputs, focusing on refining chain-of-thought (CoT) reasoning. This methodology enables models to break down intricate problems into sequential steps, closely emulating human-like logical reasoning. Generating structured reasoning responses has been a major challenge, often requiring extensive computational resources and large-scale datasets to achieve optimal performance. Recent efforts aim to enhance the efficiency of LLMs, ensuring they require less data while maintaining high reasoning accuracy.
One of the primary difficulties in improving LLM reasoning is training them to generate long CoT responses with structured self-reflection, validation, and backtracking. While existing models have demonstrated progress, the training process often demands expensive fine-tuning on extensive datasets. Furthermore, most proprietary models keep their methodologies closed-source, preventing wider accessibility. The need for data-efficient training techniques that preserve reasoning capabilities has grown, pushing researchers to explore new methods that optimize performance without overwhelming computational costs. Understanding how LLMs can effectively acquire structured reasoning with fewer training samples is critical for future advancements.

Traditional approaches to improving LLM reasoning rely on fully supervised fine-tuning (SFT) and parameter-efficient techniques like Low-Rank Adaptation (LoRA). These techniques help models refine their reasoning processes without requiring comprehensive retraining on vast datasets. Several models, including OpenAI’s o1-preview and DeepSeek R1, have made strides in logical consistency but still require significant training data.
A research team from UC Berkeley introduced a novel training approach designed to enhance LLM reasoning with minimal data. Instead of relying on millions of training samples, they implemented a fine-tuning method that uses only 17,000 CoT examples. The team applied their method to the Qwen2.5-32B-Instruct model, leveraging both SFT and LoRA fine-tuning to achieve substantial performance improvements. Their approach emphasizes optimizing the structural integrity of reasoning steps rather than the content itself. By refining logical consistency and minimizing unnecessary computational overhead, they successfully trained LLMs to reason more effectively while using significantly fewer data samples. The team’s approach also improves cost efficiency, making it accessible for a broader range of applications without requiring proprietary datasets.
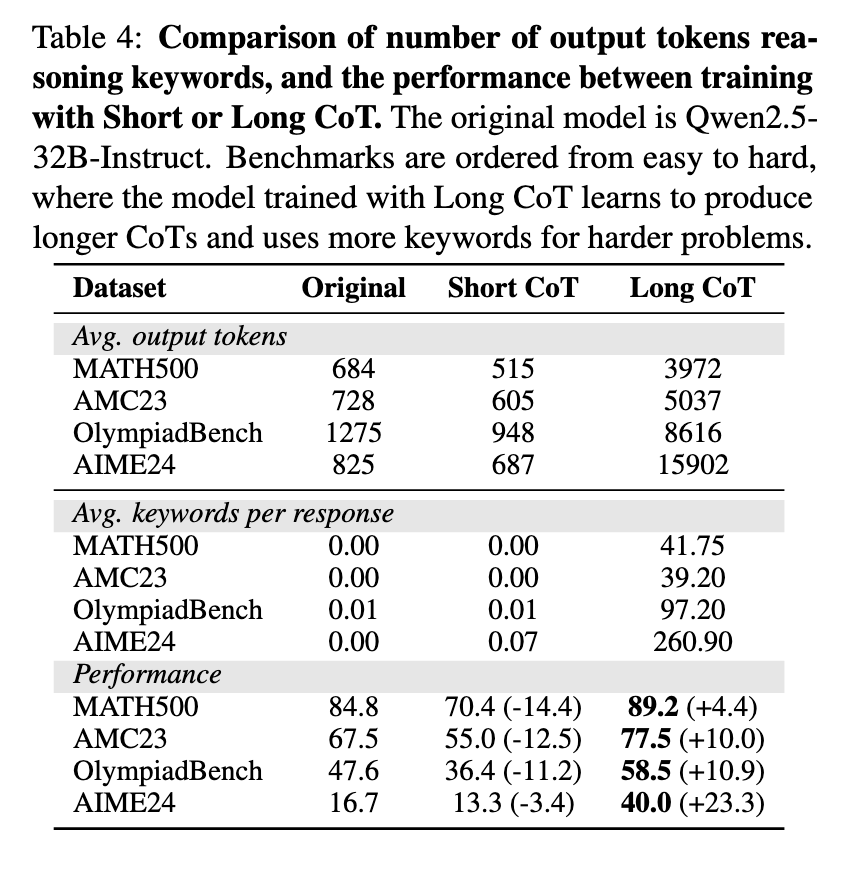
The research demonstrates that the structure of CoT plays a crucial role in enhancing LLM reasoning performance. Experiments revealed that altering the logical structure of training data significantly impacted model accuracy, whereas modifying individual reasoning steps had minimal effect. The team conducted controlled trials where they randomly shuffled, deleted, or inserted reasoning steps to observe their influence on performance. Results indicated that disrupting the logical sequence of CoT significantly degraded accuracy while preserving its structure and maintaining optimal reasoning capabilities. LoRA fine-tuning allowed the model to update fewer than 5% of its parameters, offering an efficient alternative to full fine-tuning while maintaining competitive performance.
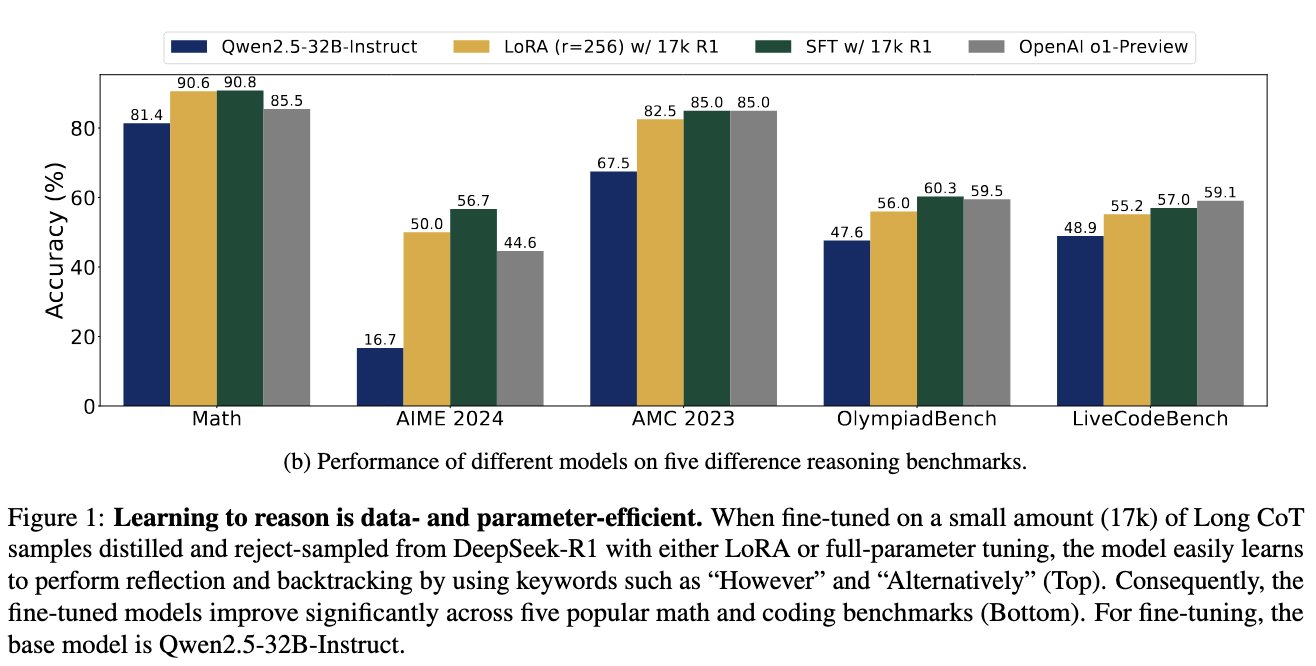
Performance evaluations showcased remarkable improvements in reasoning capabilities. The Qwen2.5-32B-Instruct model trained with 17,000 CoT samples achieved a 56.7% accuracy rate on AIME 2024, marking a 40.0% improvement. The model also scored 57.0% on LiveCodeBench, reflecting an 8.1% increase. On Math-500, it attained 90.8%, a 6.0% rise from previous benchmarks. Similarly, it achieved 85.0% on AMC 2023 (+17.5%) and 60.3% on OlympiadBench (+12.7%). These results demonstrate that efficient fine-tuning techniques can enable LLMs to achieve competitive results comparable to proprietary models like OpenAI’s o1-preview, which scored 44.6% on AIME 2024 and 59.1% on LiveCodeBench. The findings reinforce that structured reasoning training allows models to enhance performance without excessive data requirements.
The study highlights a significant breakthrough in improving LLM reasoning efficiency. By shifting the focus from large-scale data reliance to structural integrity, the researchers have developed a training methodology that ensures strong logical coherence with minimal computational resources. The approach reduces the dependence on extensive datasets while maintaining robust reasoning capabilities, making LLMs more accessible and scalable. The insights gained from this research pave the way for optimizing future models, demonstrating that structured fine-tuning strategies can effectively enhance LLM reasoning without compromising efficiency. This development marks a step forward in making sophisticated AI reasoning models more practical for widespread use.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post This AI Paper from UC Berkeley Introduces a Data-Efficient Approach to Long Chain-of-Thought Reasoning for Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ

