




Large language model (LLM) post-training focuses on refining model behavior and enhancing capabilities beyond their initial training phase. It includes supervised fine-tuning (SFT) and reinforcement learning to align models with human preferences and specific task requirements. Synthetic data is crucial, allowing researchers to evaluate and optimize post-training techniques. However, open research in this domain is still in its early stages, facing data availability and scalability limitations. Without high-quality datasets, analyzing the performance of different fine-tuning strategies and assessing their effectiveness in real-world applications becomes difficult.
One of the primary challenges in this field is the scarcity of large-scale, publicly available synthetic datasets suitable for LLM post-training. Researchers must access diverse conversational datasets to conduct meaningful comparative analyses and improve alignment strategies. The lack of standardized datasets limits the ability to evaluate post-training performance across different models. Moreover, large-scale data generation costs and computational requirements are prohibitive for many academic institutions. These factors create barriers to improving model efficiency and ensuring fine-tuned LLMs generalize well across tasks and user interactions.
Existing approaches to synthetic data collection for LLM training rely on a combination of model-generated responses and benchmark datasets. Datasets, such as WildChat-1M from Allen AI and LMSys-Chat-1M, provide valuable insights into synthetic data usage. However, they are often restricted in scale and model diversity. Researchers have developed various techniques to assess synthetic data quality, including LLM judge-based evaluations and efficiency metrics for runtime and VRAM usage. Despite these efforts, the field still lacks a comprehensive and publicly accessible dataset that allows for large-scale experimentation and optimization of post-training methodologies.
Researchers from New York University (NYU) introduced WILDCHAT-50M, an extensive dataset designed to facilitate LLM post-training. The dataset builds upon the WildChat collection and expands it to include responses from over 50 open-weight models. These models range from 0.5 billion to 104 billion parameters, making WILDCHAT-50M the largest and most diverse public dataset of chat transcripts. The dataset enables a broad comparative analysis of synthetic data generation models and is a foundation for further improving post-training techniques. By making WILDCHAT-50M publicly accessible, the research team aims to bridge the gap between industry-scale post-training and academic research.
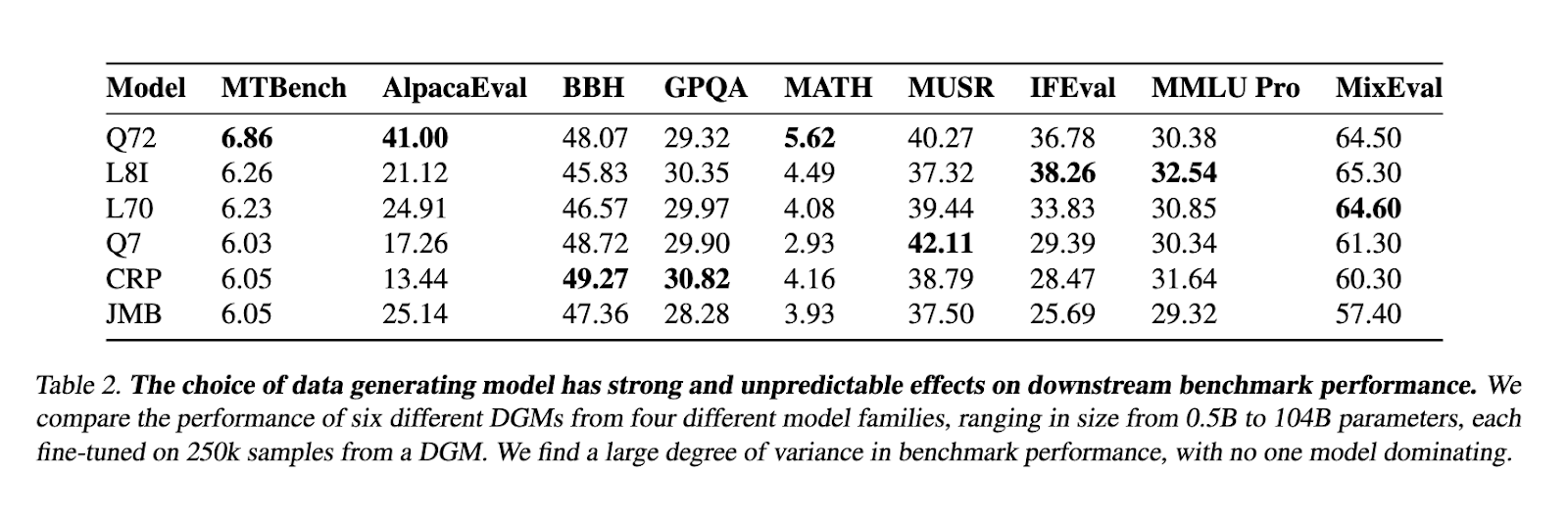
The dataset was developed by synthesizing chat transcripts from multiple models, each participating in over one million multi-turn conversations. The dataset comprises approximately 125 million chat transcripts, offering an unprecedented scale of synthetic interactions. The data collection process took place over two months using a shared research cluster of 12×8 H100 GPUs. This setup allowed researchers to optimize runtime efficiency and ensure a diverse range of responses. The dataset also served as the basis for RE-WILD, a novel supervised fine-tuning (SFT) mix that enhances LLM training efficiency. Through this approach, researchers successfully demonstrated that WILDCHAT-50M could optimize data usage while maintaining high levels of post-training performance.
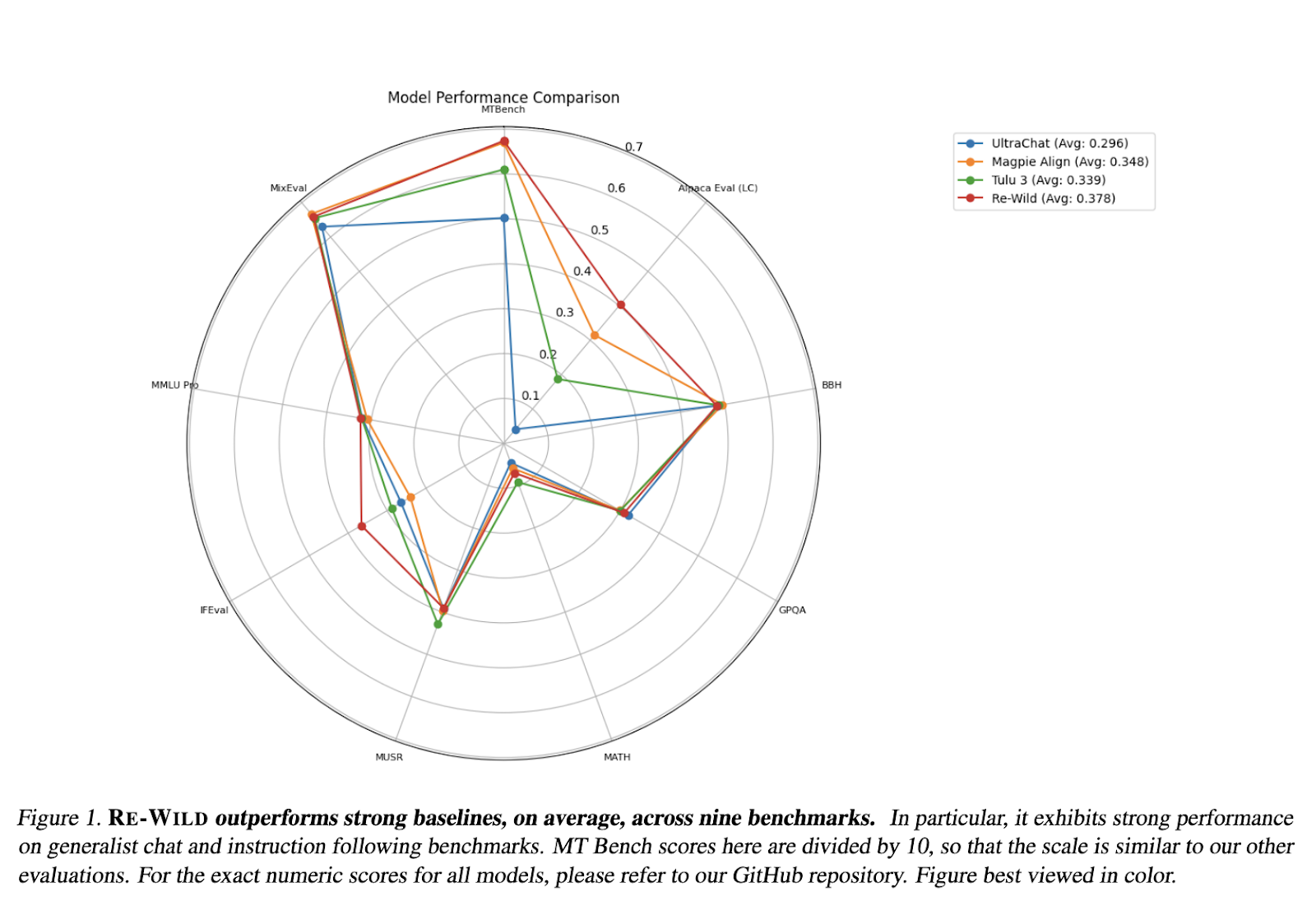
The effectiveness of WILDCHAT-50M was validated through a series of rigorous benchmarks. The RE-WILD SFT approach, based on WILDCHAT-50M, outperformed the Tulu-3 SFT mixture developed by Allen AI while using only 40% of the dataset size. The evaluation included multiple performance metrics, with specific improvements in response coherence, model alignment, and benchmark accuracy. The dataset’s ability to enhance runtime efficiency was also highlighted, with throughput efficiency analyses indicating substantial improvements in token processing speed. Further, models fine-tuned using WILDCHAT-50M demonstrated significant enhancements in instruction-following capabilities and overall chat performance across various evaluation benchmarks.
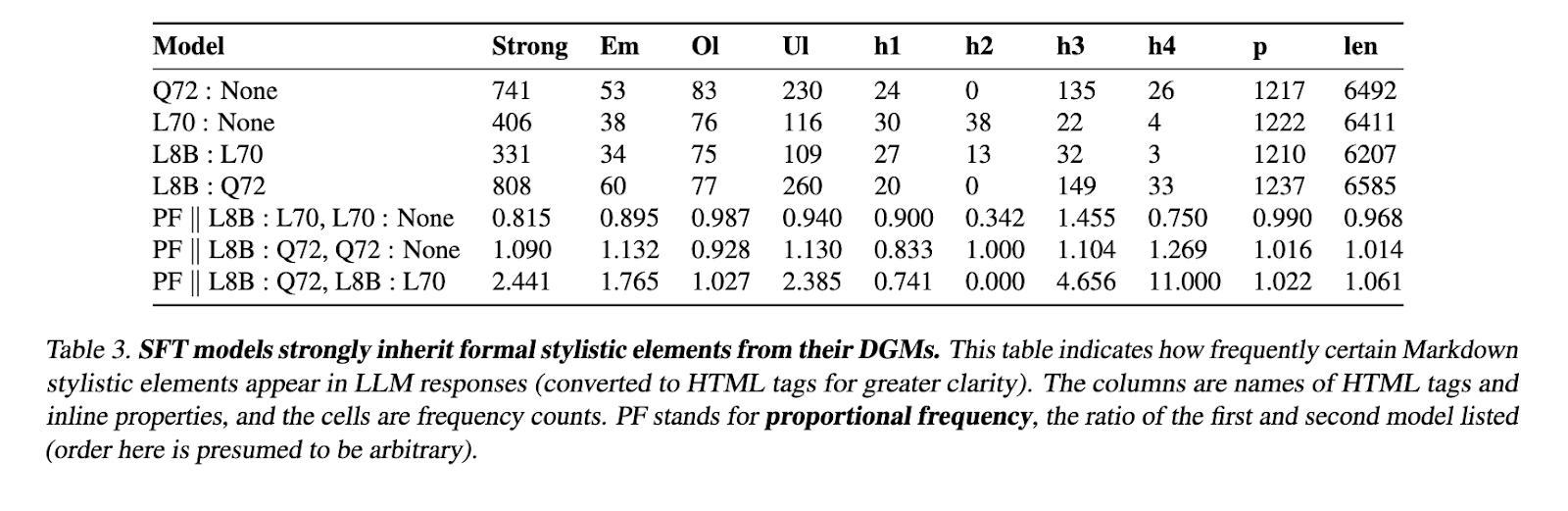
This research underscores the importance of high-quality synthetic data in LLM post-training and presents WILDCHAT-50M as a valuable resource for optimizing model alignment. By providing a large-scale, publicly available dataset, the researchers have enabled further advancements in supervised fine-tuning methodologies. The comparative analyses conducted in this study offer key insights into the effectiveness of different data generation models and post-training strategies. Moving forward, the introduction of WILDCHAT-50M is expected to support a broader range of academic and industrial research efforts, ultimately contributing to developing more efficient and adaptable language models.
Check out the Paper, Dataset on Hugging Face and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.

The post NYU Researchers Introduce WILDCHAT-50M: A Large-Scale Synthetic Dataset for Efficient LLM Post-Training appeared first on MarkTechPost.
Source: Read MoreÂ

