

Speaker verification technology seeks to reliably and accurately identify who is speaking in an audio clip. This technology would allow you to do things like unlock your phone, access your bank account, or join a secure video call with just your voice, but getting machines to reliably recognize human voices has proven surprisingly challenging, especially as these systems become more widely deployed in security-critical applications.
A new breakthrough from AI researchers at multiple institutions is changing the game by fundamentally rethinking how we process voice data. The central observation is that the traditional way in which AI systems have processed speech for at least a decade has a fundamental flaw in the form of a faulty underlying assumption that has gone unnoticed, until now.
The result – “Golden-Gemini” – addresses this flaw to achieve significantly better recognition accuracy while actually reducing computational requirements. In this blog we’ll overview this new approach and what it means for Speech AI technology.
Key Takeaways
- Problem: Current AI speech recognition systems treat voice data like images, ignoring fundamental differences between time and frequency information
- Key insight: preserve temporal (time-based) information while compressing frequency data
- Results: Better accuracy and lower computational costs than traditional approaches
- Impact: Could improve various speech AI applications, from security systems to emotion recognition
The Problem with Current Approaches
Most modern speaker verification systems rely on deep learning models that were originally designed to process images. These Convolutional Neural Networks (CNNs) – particularly ResNet varieties – have revolutionized computer vision by treating images like a grid on which local spatial relationships can be learned. For example, these sorts of models can learn to detect the edges of objects, allowing us to do things like segment images.

When these sorts of networks operate on images, they learn these local features without preference to a particular direction. In other words, if we rotated our image, the model would have no trouble learning how to do the same task. This is because there is no difference between the intrinsic qualities of different spatial directions. The properties of space do not change if you consider left to right vs up and down, and in fact these concepts can be flipped if you lay on your side. In other words, space respects some basic symmetries – rotational, translational, and scale invariance – which the models therefore learn to respect during training.
But speech is fundamentally different. When you speak, your voice creates complex patterns that unfold over time, producing varying frequencies that capture your unique vocal characteristics. These patterns – visible in spectrograms as time-frequency representations like the one below – don’t obey the same symmetries. The temporal domain captures critical sequential information about how your voice changes, while the frequency domain represents the distribution of energy across different pitch levels at each moment.
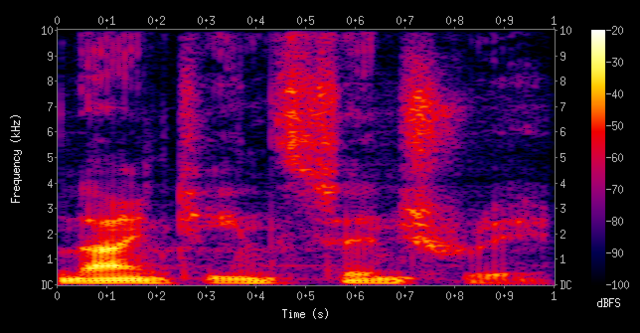
Convolutional Networks process such spectrograms as images. That is, despite the fact that the spectrogram above is just a visual representation of the underlying speech data, this representation itself is what is passed into speech processing systems.
This causes a problem – CNNs implicitly assume that the different directions in an image are effectively interchangeable. This assumption holds for the normal spatial images that CNNs were originally invented for, but it breaks down when passing in images of spectrograms, in which the frequency and time directions are not equivalent or interchangeable.
The current approach of processing images fails to account for this asymmetry. This means that crucial temporal patterns that could help distinguish between speakers might be lost or degraded as the signal passes through the network. For example, speaker-specific characteristics like speaking rate, pronunciation patterns, and voice modulation are primarily encoded in how the signal changes over time – yet current architectures might inadvertently discard some of this valuable temporal information in pursuit of computational efficiency. This information even partially encodes aspects such as sex, age, and emotion, so discarding this paralinguistic structure by failing to recognize the symmetry assumptions of standard CNNs limits their performance in many applications.
It is easy to forget or not realize that this assumption is even being made when using a CNN, and indeed it seems that it has gone unnoticed by researchers up until now. But the Golden-Gemini researchers have identified it and invented a novel solution in recognition of this mismatch between processing behavior and underlying symmetries (or lack thereof).
The Golden Gemini Solution
The researchers’ breakthrough comes from a deceptively simple insight: when processing speech for speaker verification, we should prioritize preserving temporal information over frequency information. This “Golden-Gemini Hypothesis” suggests that, in order to properly leverage the unique characteristics that identify a speaker, we need to focus on better using the temporal changes in voice patterns than in the specific frequency distributions at a given moment.
To implement this insight, the team developed a new approach to configuring ResNet architectures. Rather than using the traditional compression configuration that reduces both time and frequency domains similarly, they identified two optimal configurations that carefully preserve temporal resolution while allowing more aggressive downsampling in the frequency domain without losing relevant information. This specialized approach allows the network to maintain fine-grained temporal information about speaking patterns while still achieving efficient computation.
Investigation Method
The authors investigated different compression strategies by systematically exploring various temporal and frequency downsampling configurations in neural networks for speaker verification. They visualized these configurations using a novel trellis diagram approach that maps out different possible compression paths.
In these diagrams, the x-axis represents the temporal compression factor while the y-axis shows the frequency compression factor. Each point represents a final compression profile, while the paths between points show different sequences of compression operations used to achieve that profile. These paths are significant because each step along a path represents a compression operation followed by neural network processing layers – the network performs feature extraction and analysis on the compressed representations before the next compression occurs.
For instance, the black line demonstrates a balanced compression approach, where both temporal and frequency domain are repeatedly halved, with neural network processing occurring between each compression step, to achieve a final 1/8th compression in both directions. This sequential nature of compression-then-processing is why different paths to the same final compression point can yield different results – early compression gives fewer computations but might lose important information before it can be processed, while late compression preserves more information for processing but requires more computational resources.
The performance of each configuration is indicated by circle size (larger is better) and accompanied by detailed metrics: model accuracy (EER, where lower is better), parameter count (in millions), and memory requirements (in gigabytes). This visualization method allowed the authors to systematically compare different compression strategies and their impacts on both performance and computational efficiency.
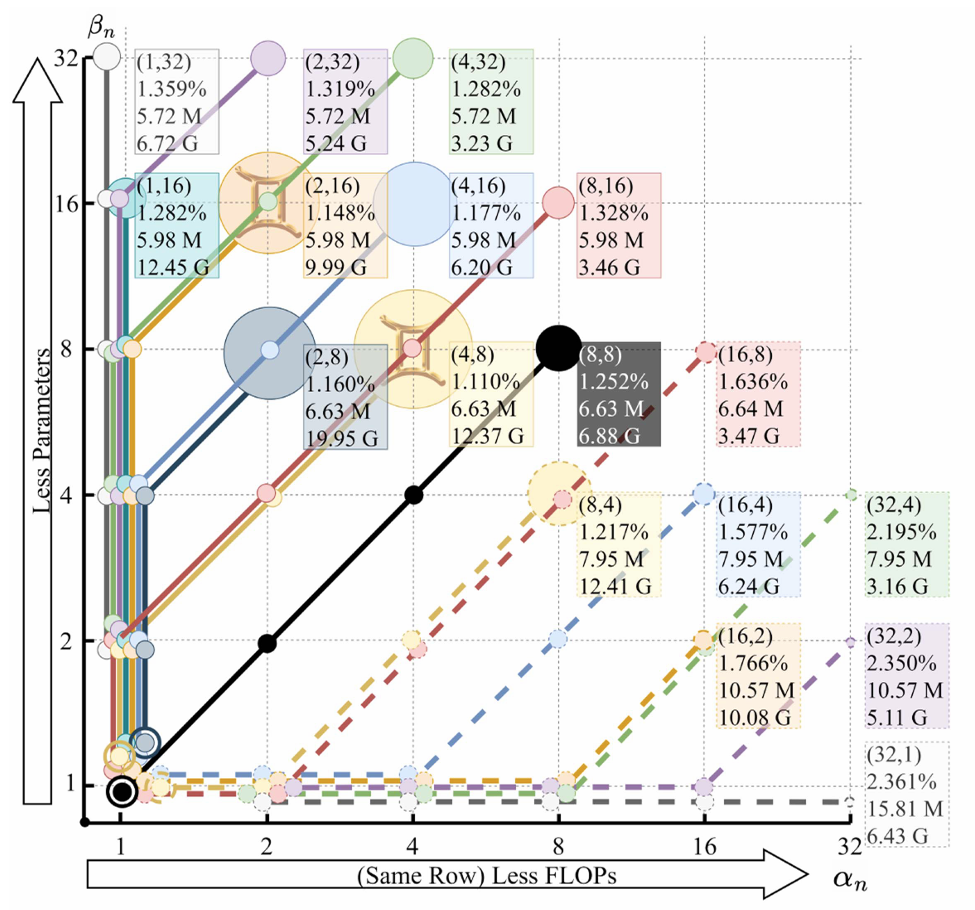
Less FLOPs vs Less Parameters
By performing more aggressive frequency downsampling, the parameter count of the model is lowered; however, with low temporal downsampling there will still be a high number of FLOPs because the model still has to be applied to the entirety of the audio.
Conversely, with aggressive temporal downsampling the FLOPs count is lowered because the network is being applied across a compressed audio representation, but with low frequency downsampling the model that is being applied may still have a high parameter count. While a higher parameter count will lead to a greater number of FLOPs than a lower parameter account (all things equal), the temporal downsampling has a much greater impact on total FLOPs.
This is why the frequency downsampling axis in the above chart is labeled “Less Parameters”, while the temporal downsampling axis in the above chart is labeled “Less FLOPs”
Key Findings and Results
Performance vs. Compression Strategy
The visualization reveals that configurations preserving temporal information while aggressively compressing frequency information (shown in the top-left region) consistently outperform other approaches. This is evident from the larger performance circles in this region compared to the bottom-right, directly supporting the authors’ core hypothesis about the relative importance of temporal information. Some configurations demonstrate comprehensive improvements across all metrics – for example, the (8,16) compression profile outperforms (32,2) in accuracy, model size, and memory requirements.
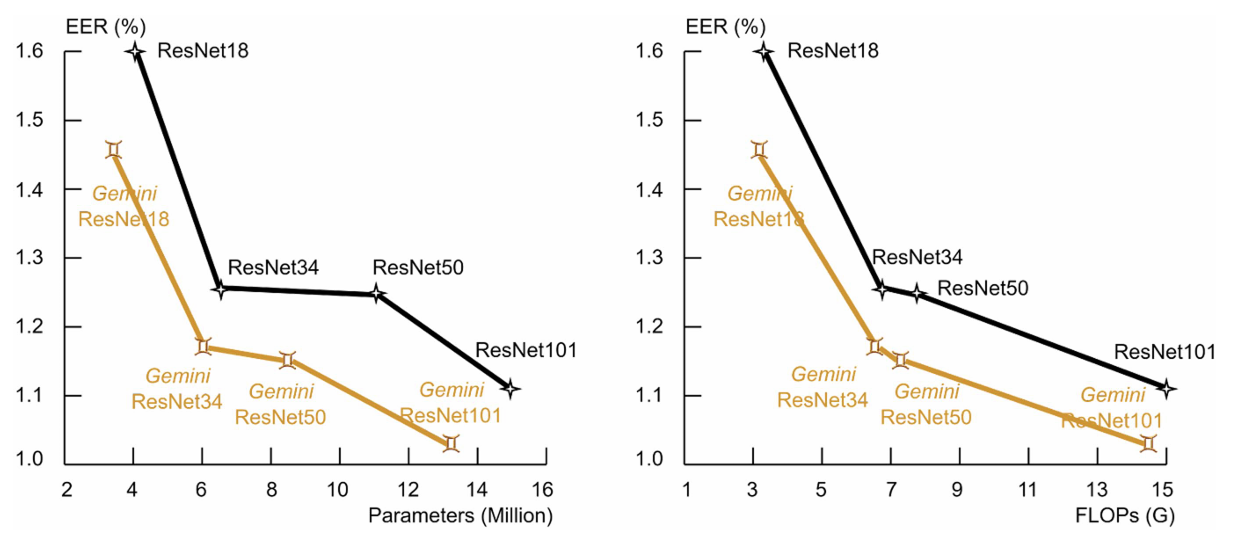
Golden Gemini Performance Metrics
The power of this solution lies in its elegant simplicity – rather than adding architectural complexity or computational overhead, it achieves improvements through a more thoughtful understanding of how temporal and frequency information should be processed. The authors’ systematic investigation of compression strategies revealed that careful choices about when and how to compress different domains can lead to both better performance and lower computational costs.
The results are remarkable – Golden Gemini consistently improves relative performance by 8% on EER and 12% on minDCF (two canonical metrics), while actually reducing the number of parameters by 16.5% and computational operations by 4.1% compared to traditional approaches. It’s a rare case where better performance comes with lower computational cost – achieved not through elaborate architectural changes, but through a more thoughtful approach to processing the underlying signal
Versatility and Robustness
What’s particularly noteworthy is the solution’s versatility. The researchers tested Golden Gemini across different model sizes (from ResNet18 to ResNet101), different training conditions (with and without data augmentation), and various architectural modifications. In each case, the approach maintained its performance advantages. Even when applied to state-of-the-art models like DF-ResNet, Golden Gemini provided additional performance gains, pushing the boundaries of what’s possible in speaker verification.
Real-World Application
Most importantly, these improvements held up under real-world conditions. On challenging cross-domain scenarios where the test conditions differ significantly from training conditions, Golden Gemini maintained its edge. For example, on the challenging CNCeleb dataset, which tests how well models generalize to different recording conditions and speaking styles, the approach achieved significant error reductions while using fewer computational resources. This robust performance across diverse scenarios suggests that Golden Gemini isn’t just a laboratory success – it’s a practical advancement ready for real-world deployment.
What This Means for the Future
The Golden Gemini approach isn’t just theoretically elegant – it delivers impressive real-world performance improvements, such as up to 8% relative EER improvements with 16.5% fewer parameters, across a wide range of testing scenarios. This kind of simultaneous improvement in both accuracy and efficiency is rare in deep learning research.
The Golden Gemini approach demonstrates that thoughtful speech theory choices can yield simultaneous improvements in accuracy and efficiency – a valuable finding for both research and practical applications. By prioritizing temporal information preservation while reducing computational requirements, this work suggests new directions for developing more efficient speech processing systems.
The practical implications are significant for voice-based security applications. The approach’s combination of improved accuracy and reduced computational requirements enables more robust speaker verification on devices with limited processing power. This could benefit applications ranging from banking authentication to smart home systems.
The principles demonstrated in this work may extend beyond speaker verification. The researchers have shown promising results in adapting the approach to related tasks like speaker diarization, emotion recognition, and anti-spoofing systems. With the code and pre-trained models publicly available, other researchers can build upon these findings to potentially improve efficiency across various speech processing applications.
If you want to learn more about compression methods in AI, check out our video on Residual Vector Quantization:
Otherwise, check out more of our blog to learn about all things AI, or follow us on Twitter to stay in the loop when we release new content.
Source: Read MoreÂ
