




Reinforcement learning (RL) trains agents to make sequential decisions by maximizing cumulative rewards. It has diverse applications, including robotics, gaming, and automation, where agents interact with environments to learn optimal behaviors. Traditional RL methods fall into two categories: model-free and model-based approaches. Model-free techniques prioritize simplicity but require extensive training data, while model-based methods introduce structured learning but are computationally demanding. A growing area of research aims to bridge these approaches and develop more versatile RL frameworks that function efficiently across different domains.
A persistent challenge in RL is the absence of a universal algorithm capable of performing consistently across multiple environments without exhaustive parameter tuning. Most RL algorithms are designed for specific applications, necessitating adjustments to work effectively in new settings. Model-based RL methods generally demonstrate superior generalization but at the cost of greater complexity and slower execution speeds. On the other hand, model-free methods are easier to implement but often lack efficiency when applied to unfamiliar tasks. Developing an RL framework that integrates the strengths of both approaches without compromising computational feasibility remains a key research objective.
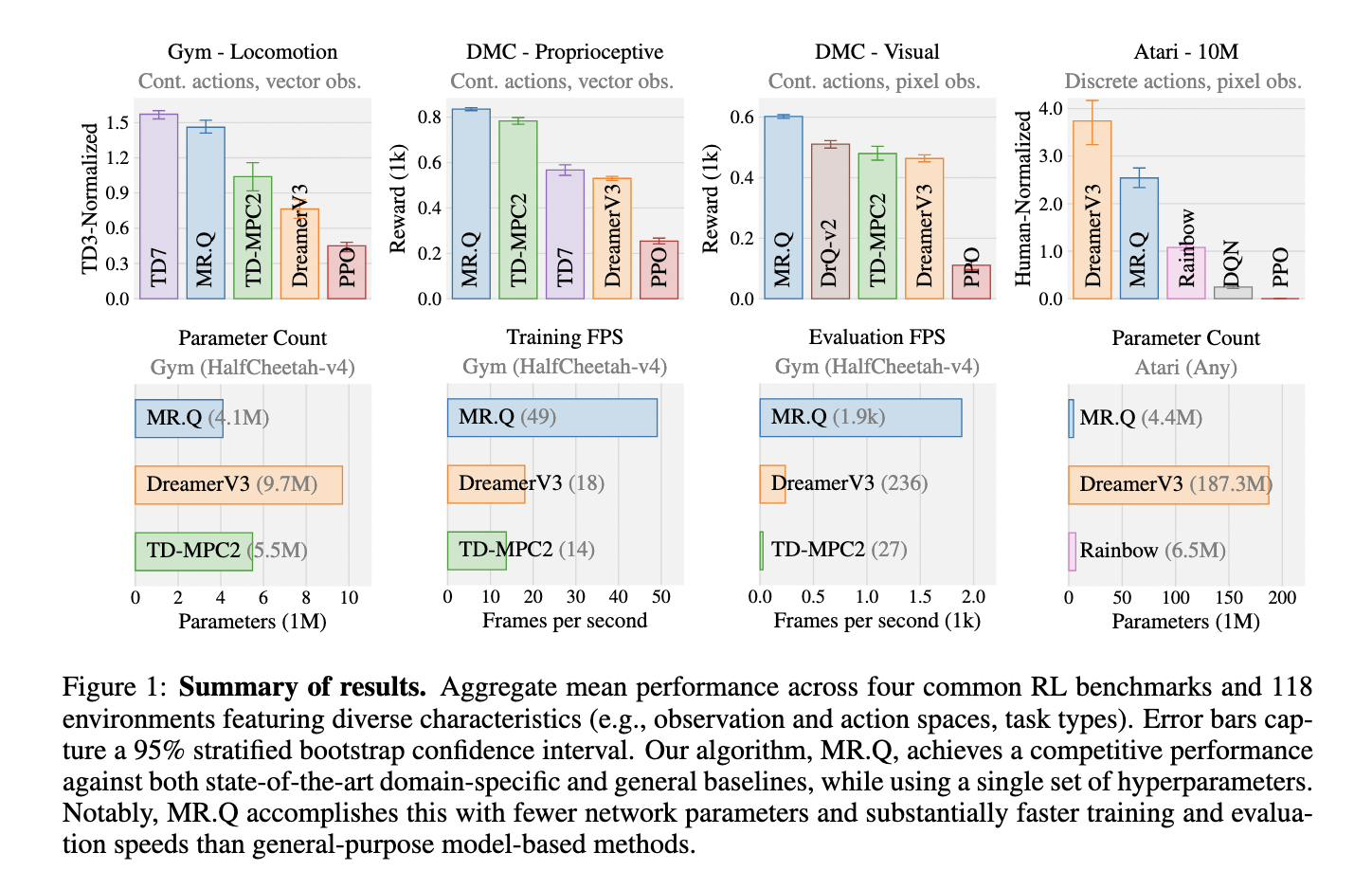
Several RL methodologies have emerged, each with trade-offs between performance and efficiency. Model-based solutions such as DreamerV3 and TD-MPC2 have achieved substantial results across different tasks but rely heavily on complex planning mechanisms and large-scale simulations. Model-free alternatives, including TD3 and PPO, offer reduced computational demands but require domain-specific tuning. This disparity underscores the need for an RL algorithm that combines adaptability and efficiency, enabling seamless application across various tasks and environments.
A research team from Meta FAIR introduced MR.Q, a model-free RL algorithm incorporating model-based representations to improve learning efficiency and generalization. Unlike traditional model-free approaches, MR.Q leverages a representation learning phase inspired by model-based objectives, enabling the algorithm to function effectively across different RL benchmarks with minimal tuning. This approach allows MR.Q to benefit from the structured learning signals of model-based methods while avoiding the computational overhead associated with full-scale planning and simulated rollouts.
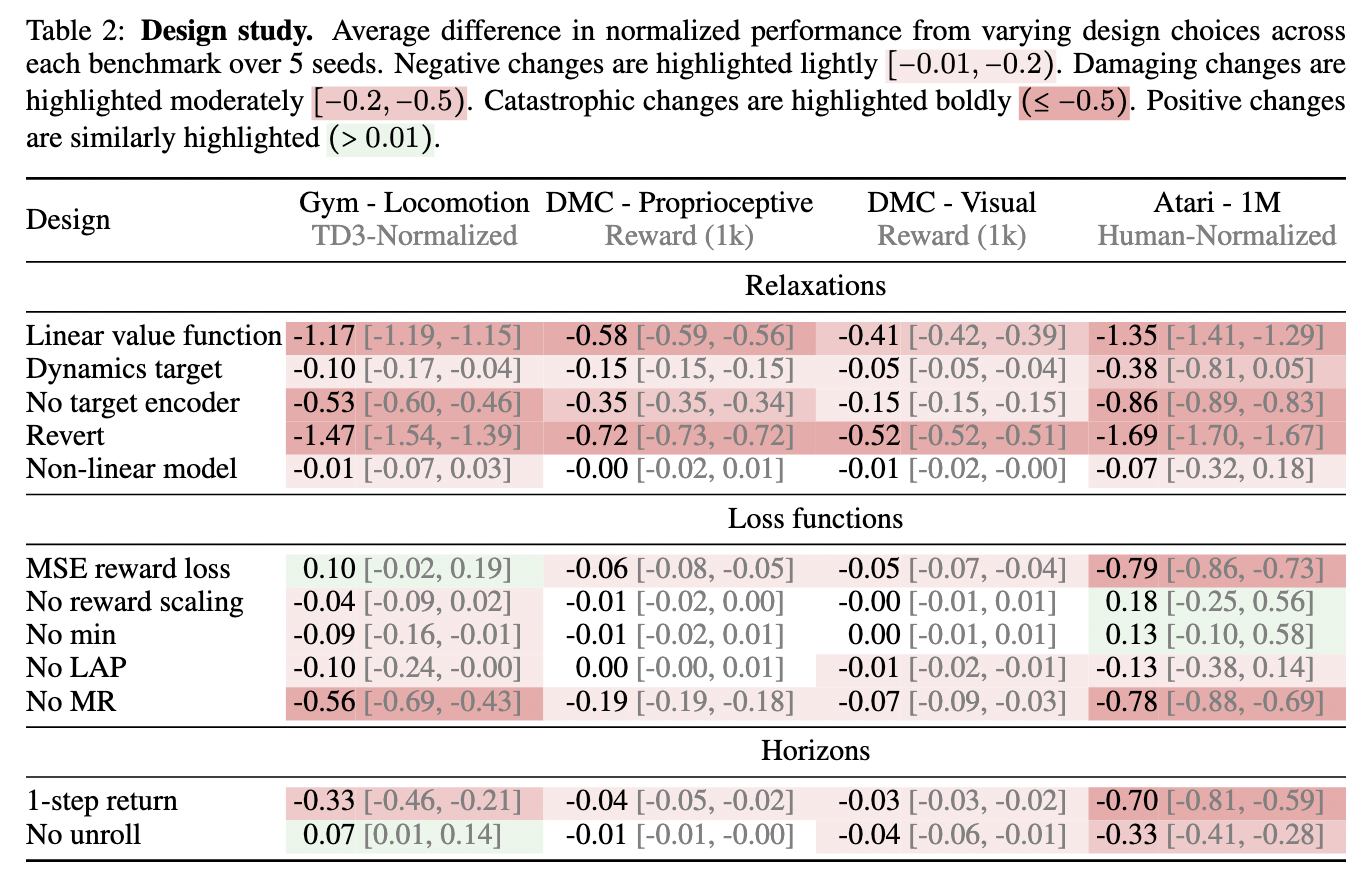
The MR.Q framework maps state-action pairs into embeddings that maintain an approximately linear relationship with the value function. These embeddings are then processed through a non-linear function to retain consistency across different environments. The system integrates an encoder that extracts relevant features from state and action inputs, enhancing learning stability. Further, MR.Q employs a prioritized sampling technique and a reward scaling mechanism to improve training efficiency. The algorithm achieves robust performance across multiple RL benchmarks while maintaining computational efficiency by focusing on an optimized learning strategy.
Experiments conducted across four RL benchmarks—Gym locomotion tasks, DeepMind Control Suite, and Atari—demonstrate that MR.Q achieves strong results with a single set of hyperparameters. The algorithm outperforms conventional model-free baselines like PPO and DQN while maintaining comparable performance to DreamerV3 and TD-MPC2. MR.Q achieves competitive results while utilizing significantly fewer computational resources, making it a practical choice for real-world applications. In the Atari benchmark, MR.Q performs particularly well in discrete-action spaces, surpassing existing methods. MR.Q demonstrates strong performance in continuous control environments, surpassing model-free baselines such as PPO and DQN while maintaining competitive results compared to DreamerV3 and TD-MPC2. The algorithm achieves significant efficiency improvements across benchmarks without requiring extensive reconfiguration for different tasks. The evaluation further highlights MR.Q’s ability to generalize effectively without requiring extensive reconfiguration for new tasks.
The study underscores the benefits of incorporating model-based representations into model-free RL algorithms. MR.Q marks a step toward developing a truly versatile RL framework by enhancing efficiency and adaptability. Future advancements could refine its approach to address challenges such as hard exploration problems and non-Markovian environments. The findings contribute to the broader goal of making RL techniques more accessible and effective for many applications, positioning MR.Q as a promising tool for researchers and practitioners seeking robust RL solutions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Meta AI Introduces MR.Q: A Model-Free Reinforcement Learning Algorithm with Model-Based Representations for Enhanced Generalization appeared first on MarkTechPost.
Source: Read MoreÂ
