

: A Novel Post-Training Quantization Method Designed to Enhance the Efficiency of Large Language Models (LLMs)")


Post-training quantization (PTQ) focuses on reducing the size and improving the speed of large language models (LLMs) to make them more practical for real-world use. Such models require large data volumes, but strongly skewed and highly heterogeneous data distribution during quantization presents considerable difficulties. This would inevitably expand the quantization range, making it, in most values, a less accurate expression and reducing general performance in model precision. While PTQ methods aim to address these issues, challenges remain in effectively distributing data across the entire quantization space, limiting the potential for optimization and hindering broader deployment in resource-constrained environments.
Current Post-training quantization (PTQ) methods of large language models (LLMs) focus on weight-only and weight-activation quantization. Weight-only methods, such as GPTQ, AWQ, and OWQ, attempt to reduce memory usage by minimizing quantization errors or addressing activation outliers but fail to optimize precision for all values fully. Techniques like QuIP and QuIP# use random matrices and vector quantization but remain limited in handling extreme data distributions. Weight-activation quantization aims to speed up inference by quantizing both weights and activations. Yet, methods like SmoothQuant, ZeroQuant, and QuaRot struggle to manage the dominance of activation outliers, causing errors in most values. Overall, these methods rely on heuristic approaches and fail to optimize data distribution across the entire quantization space, which limits performance and efficiency.
To address the limitations of heuristic post-training quantization (PTQ) methods and the lack of a metric for assessing quantization efficiency, researchers from the Houmo AI, Nanjing University, and Southeast University proposed the Quantization Space Utilization Rate (QSUR) concept. QSUR measures how effectively weight and activation distributions utilize the quantization space, offering a quantitative basis to evaluate and improve PTQ methods. The metric leverages statistical properties like eigenvalue decomposition and confidence ellipsoids to calculate the hypervolume of weight and activation distributions. QSUR analysis shows how linear and rotational transformations affect quantization efficiency, with specific techniques reducing inter-channel disparities and minimizing outliers to enhance performance.
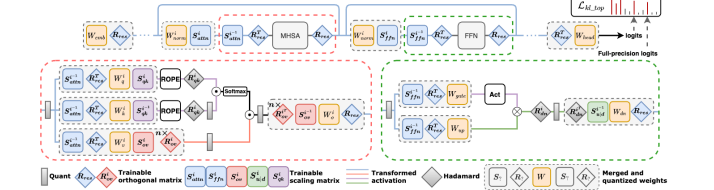
Researchers proposed the OSTQuant framework, which combines orthogonal and scaling transformations to optimize large language models’ weight and activation distributions. This approach integrates learnable equivalent transformation pairs of diagonal scaling and orthogonal matrices, guaranteeing computational efficiency while preserving equivalence at quantization. It reduces overfitting without compromising the output of the original network at the time of inference. OSTQuant uses inter-block learning to propagate transformations globally across LLM blocks, employing techniques like Weight Outlier Minimization Initialization (WOMI) for effective initialization. The method achieves higher QSUR, reduces runtime overhead, and enhances quantization performance in LLMs.
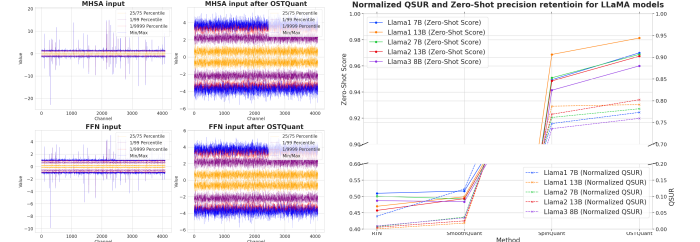
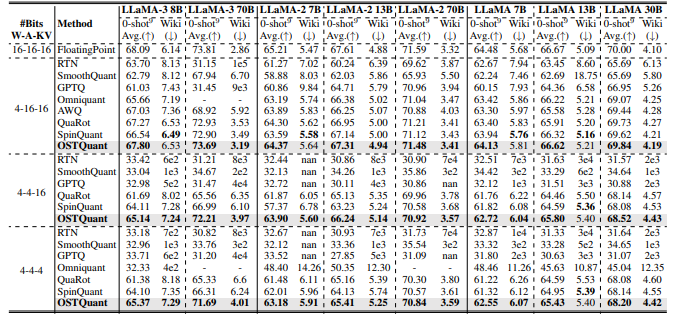
For evaluation purposes, researchers applied OSTQuant to the LLaMA family (LLaMA-1, LLaMA-2, and LLaMA-3) and assessed performance using perplexity on WikiText2 and nine zero-shot tasks. Compared to methods like SmoothQuant, GPTQ, Quarot, and SpinQuant, OSTQuant consistently outperformed them, achieving at least 99.5% floating-point accuracy under the 4-16-16 setup and significantly narrowing performance gaps. LLaMA-3-8B incurred only a 0.29-point drop in zero-shot tasks, compared to losses exceeding 1.55 points for others. In harder scenarios, OSTQuant was better than SpinQuant and gained as much as 6.53 points by LLaMA-2 7B in the 4-4-16 setup. The KL-Top loss function provided a better fitting of semantics and reduced noise, thus enhancing performance and lowering gaps in the W4A4KV4 by 32%. These outcomes showed that OSTQuant is more effective at outlier handling and ensuring distributions are more unbiased.

In the end, the proposed method optimized the data distributions in the quantization space based on the QSUR metric and the loss function, KL-Top, improving the performance of large language models. With low calibration data, it diminished noise and preserved semantic richness compared to existing quantization techniques, achieving high performance in multiple benchmarks. This framework can serve as a basis for future work, starting a process that will be instrumental in perfecting quantization techniques and making models more efficient for applications requiring high computation efficiency in resource-constrained settings.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post Quantization Space Utilization Rate (QSUR): A Novel Post-Training Quantization Method Designed to Enhance the Efficiency of Large Language Models (LLMs) appeared first on MarkTechPost.
Source: Read MoreÂ

