




AI has entered an era of the rise of competitive and groundbreaking large language models and multimodal models. The development has two sides, one with open source and the other being propriety models. DeepSeek-R1, an open-source AI model developed by DeepSeek-AI, a Chinese research company, exemplifies this trend. Its emergence has challenged the dominance of proprietary models such as OpenAI’s o1, sparking discussions on cost efficiency, open-source innovation, and global technological leadership in AI. Let’s delve into the development, capabilities, and implications of DeepSeek-R1 while comparing it with OpenAI’s o1 system, considering the contributions of both spaces.
DeepSeek-R1
DeepSeek-R1 is the great output of DeepSeek-AI’s innovative efforts in open-source LLMs to enhance reasoning capabilities through reinforcement learning (RL). The model’s development significantly departs from traditional AI training methods that rely heavily on supervised fine-tuning (SFT). Instead, DeepSeek-R1 employs a multi-stage pipeline combining cold-start, RL, and supervised data to create a model capable of advanced reasoning.
The Development Process
DeepSeek-R1 leverages a unique multi-stage training process to achieve advanced reasoning capabilities. It builds on its predecessor, DeepSeek-R1-Zero, which employed pure RL without relying on SFT. While DeepSeek-R1-Zero demonstrated remarkable capabilities in reasoning benchmarks, it faced challenges such as poor readability and language inconsistencies. DeepSeek-R1 adopted a more structured approach to address these limitations, integrating cold-start data, reasoning-oriented RL, and SFT.
The development began with collecting thousands of high-quality examples of long Chains of Thought (CoT), a foundation for fine-tuning the DeepSeek-V3-Base model. This cold-start phase emphasized readability and coherence, ensuring outputs were user-friendly. The model was then subjected to a reasoning-oriented RL process using Group Relative Policy Optimization (GRPO). This innovative algorithm enhances learning efficiency by estimating rewards based on group scores rather than using a traditional critic model. This stage significantly improved the model’s reasoning capabilities, particularly in math, coding, and logic-intensive tasks. Following RL convergence, DeepSeek-R1 underwent SFT using a dataset of approximately 800,000 samples, including reasoning and non-reasoning tasks. This process broadened the model’s general-purpose capabilities and enhanced its performance across benchmarks. Also, the reasoning capabilities were distilled into smaller models, such as Qwen and Llama, enabling the deployment of high-performance AI in computationally efficient forms.
Technical Excellence and Benchmark Performance
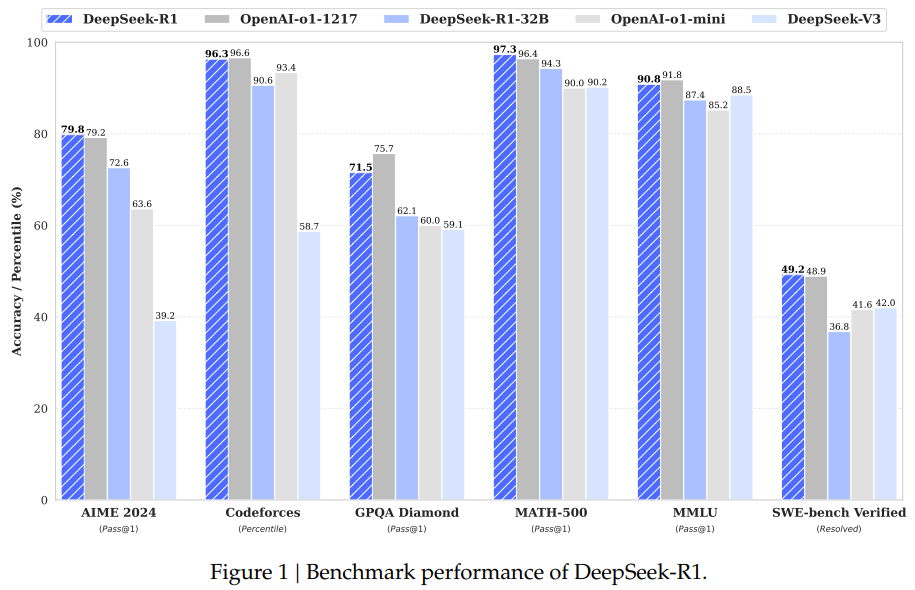
DeepSeek-R1 has established itself as a formidable AI model, excelling in benchmarks across multiple domains. Some of its key performance highlights include:
- Mathematics: The model achieved a Pass@1 score of 97.3% on the MATH-500 benchmark, comparable to OpenAI’s o1-1217. This result underscores its ability to handle complex problem-solving tasks.
- Coding: On the Codeforces platform, DeepSeek-R1 achieved an Elo rating of 2029, placing it in the top percentile of participants. It also outperformed other models in benchmarks like SWE Verified and LiveCodeBench, solidifying its position as a reliable tool for software development.
- Reasoning Benchmarks: DeepSeek-R1 achieved a Pass@1, scoring 71.5% on GPQA Diamond and 79.8% on AIME 2024, demonstrating its advanced reasoning capabilities. Its novel use of CoT reasoning and RL achieved these results.
- Creative Tasks: DeepSeek-R1 excelled in creative and general question-answering tasks beyond technical domains, achieving an 87.6% win rate on AlpacaEval 2.0 and 92.3% on ArenaHard.
Key Features of DeepSeek-R1 include:
- Architecture: DeepSeek-R1 utilizes a Mixture of Experts (MoE) design with 671 billion parameters, activating only 37 billion parameters per forward pass. This structure allows for efficient computation and scalability, making it suitable for local execution on consumer-grade hardware.
- Training Methodology: Unlike traditional models that rely on supervised fine-tuning, DeepSeek-R1 employs an RL-based training approach. This enables the model to autonomously develop advanced reasoning capabilities, including CoT reasoning and self-verification.
- Performance Metrics: Initial benchmarks indicate that DeepSeek-R1 excels in various areas:
- MATH-500 (Pass@1): 97.3%, surpassing OpenAI’s o1 which achieved 96.4%.
- Codeforces Rating: Close competition with OpenAI’s top ratings (2029 vs. 2061).
- C-Eval (Chinese Benchmarks): Achieving a record accuracy of 91.8%.
- Cost Efficiency: DeepSeek-R1 is reported to deliver performance comparable to OpenAI’s o1 at approximately 95% lower cost, which could significantly alter the economic landscape of AI development and deployment.
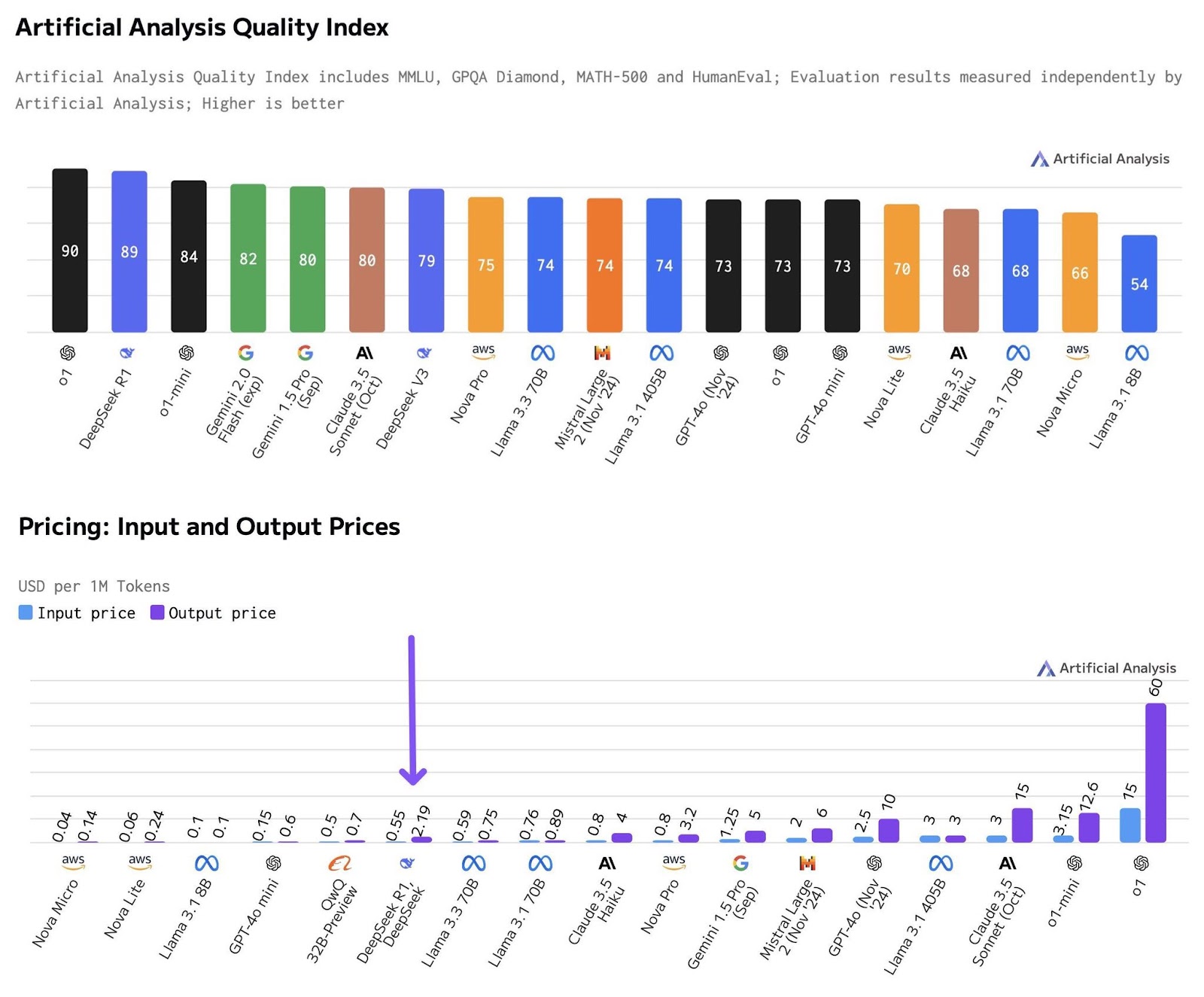
OpenAI’s o1
OpenAI’s o1 models are known for their state-of-the-art reasoning and problem-solving abilities. They were developed by focusing on large-scale SFT and RL to refine their reasoning capabilities. The o1 series excels at CoT reasoning, which involves breaking down complex and detailed tasks into manageable steps. This approach has led to exceptional mathematics, coding, and scientific reasoning performance.
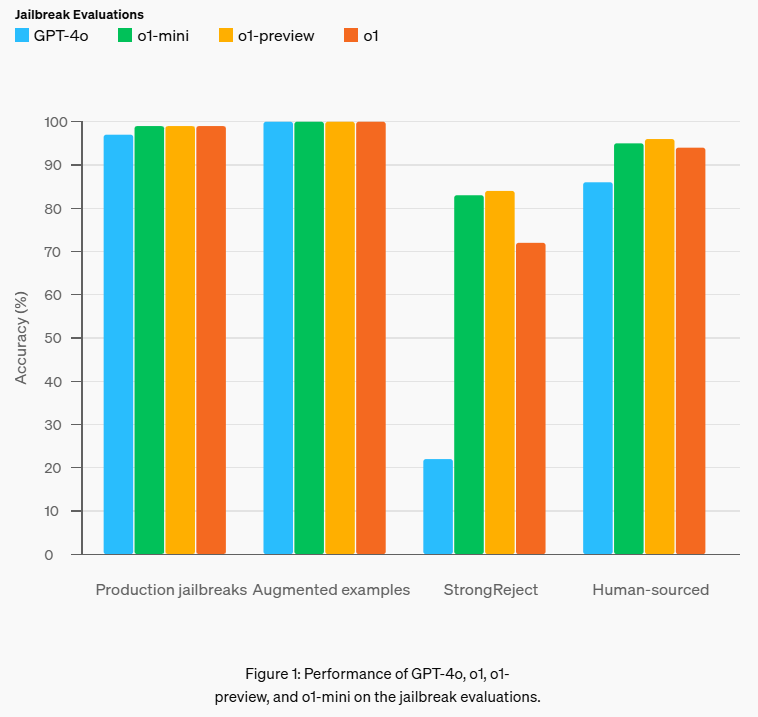
A main strength of the o1 series is its focus on safety and compliance. OpenAI has implemented rigorous safety protocols, including external red-teaming exercises and ethical evaluations, to minimize risks associated with harmful outputs. These measures ensure the models align with ethical guidelines, making them suitable for high-stakes applications. Also, the o1 series is highly adaptable, excelling in diverse applications ranging from creative writing and conversational AI to multi-step problem-solving.
Key Features of OpenAI’s o1:
- Model Variants: The o1 family includes three versions:
- o1: The full version with advanced capabilities.
- o1-mini: A smaller, more efficient model optimized for speed while maintaining strong performance.
- o1 pro mode: The most powerful variant, utilizing additional computing resources for enhanced performance.
- Reasoning Capabilities: The o1 models are optimized for complex reasoning tasks and demonstrate significant improvements over previous models. They are particularly strong in STEM applications, where they can perform at levels comparable to PhD students on challenging benchmark tasks.
- Performance Benchmarks:
- On the American Invitational Mathematics Examination (AIME), the o1 pro mode scored 86%, significantly outperforming the standard o1, which scored 78%, showcasing its math capabilities.
- In coding benchmarks such as Codeforces, the o1 models achieved high rankings, indicating strong coding performance.
- Multimodal Capabilities: The o1 models can handle text and image inputs, allowing for comprehensive analysis and interpretation of complex data. This multimodal functionality enhances their application across various domains.
- Self-Fact-Checking: Self-fact-checking improves accuracy and reliability, particularly in technical domains like science and mathematics.
- Chain-of-Thought Reasoning: The o1 models utilize large-scale reinforcement learning to engage in complex reasoning processes before generating responses. This approach helps them refine their outputs and recognize errors effectively.
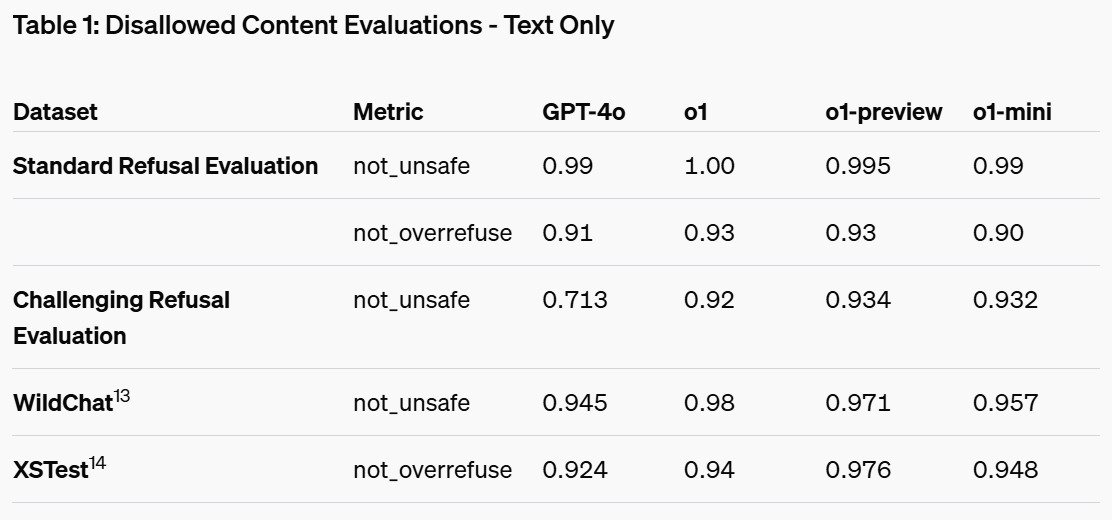
- Safety Features: Enhanced bias mitigation and improved content policy adherence ensure that the responses generated by the o1 models are safe and appropriate. For instance, they achieve a not-unsafe score of 0.92 on the Challenging Refusal Evaluation.
A Comparative Analysis: DeepSeek-R1 vs. OpenAI o1
Strengths of DeepSeek-R1
- Open-Source Accessibility: DeepSeek-R1’s open-source framework democratizes access to advanced AI capabilities, fostering innovation within the research community.
- Cost Efficiency: DeepSeek-R1’s development leveraged cost-effective techniques, enabling its deployment without the financial barriers often associated with proprietary models.
- Technical Excellence: GRPO and reasoning-oriented RL have equipped DeepSeek-R1 with cutting-edge reasoning abilities, particularly in mathematics and coding.
- Distillation for Smaller Models: By distilling its reasoning capabilities into smaller models, DeepSeek-R1 expands its usability. It offers high performance without excessive computational demands.
Strengths of OpenAI o1
- Comprehensive Safety Measures: OpenAI’s o1 models prioritize safety and compliance, making them reliable for high-stakes applications.
- General Capabilities: While DeepSeek-R1 focuses on reasoning tasks, OpenAI’s o1 models excel in various applications, including creative writing, knowledge retrieval, and conversational AI.
The Open-Source vs. Proprietary Debate
The emergence of DeepSeek-R1 has reignited the debate over the merits of open-source versus proprietary AI development. Proponents of open-source models argue that they accelerate innovation by pooling collective expertise and resources. Also, they promote transparency, which is vital for ethical AI deployment. On the other hand, proprietary models often claim superior performance due to their access to proprietary data and resources. The competition between these two paradigms represents a microcosm of the broader challenges in the AI landscape: balancing innovation, cost management, accessibility, and ethical considerations. After the release of DeepSeek-R1, Marc Andreessen tweeted on X, “Deepseek R1 is one of the most amazing and impressive breakthroughs I’ve ever seen — and as open source, a profound gift to the world.”
Conclusion
The emergence of DeepSeek-R1 marks a transformative moment for the open-source AI industry. Its open-source nature, cost efficiency, and advanced reasoning capabilities challenge the dominance of proprietary systems and redefine the possibilities for AI innovation. In parallel, OpenAI’s o1 models set safety and general capability benchmarks. Together, these models reflect the dynamic and competitive nature of the AI landscape.
Sources
- https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
- https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero
- https://openai.com/index/openai-o1-system-card/
- https://openai.com/index/introducing-openai-o1-preview/
- https://x.com/i/trending/1882832103395701128
- https://x.com/pmarca/status/1882719769851474108
- https://twitter.com/TheShortBear/status/1882783200998498542/photo/1
Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post DeepSeek-R1 vs. OpenAI’s o1: A New Step in Open Source and Proprietary Models appeared first on MarkTechPost.
Source: Read MoreÂ

