




Aligning large language models (LLMs) with human values is essential as these models become central to various societal functions. A significant challenge arises when model parameters cannot be updated directly because the models are fixed or inaccessible. In these cases, the focus is on adjusting the input prompts to make the model’s outputs match the desired results. However, this technique lacks a solid theoretical foundation, and its effectiveness and ability to achieve the best results are uncertain compared to methods that adjust the model’s parameters. The key issue is whether prompt optimization can fully address alignment challenges without requiring direct adjustments to the model itself.

Current methods for aligning large language models (LLMs), such as reinforcement learning from human feedback (RLHF), rely heavily on fine-tuning model parameters. These include supervised fine-tuning, reward learning, and reinforcement learning-based optimization. Despite being efficient, they are resource-intensive and thus unsuitable for frozen or inaccessible models. The new alternatives, namely direct preference optimization and intuitive fine-tuning, rely on parameter updates, limiting their applicability scope. Recently, prompt optimization was discovered as an alternative that interacts with the input prompts to adjust the model responses. This technique does not have much theoretical clarity and has been subject to doubts over its ability to match the efficacy of parameter-based methods for alignment challenges.
To improve the alignment of large language models (LLMs), researchers from the University of Central Florida, the University of Maryland, and Purdue University proposed Align-Pro, a prompt optimization framework designed to align LLMs without modifying their parameters. This framework includes key steps such as supervised fine-tuning (SFT), reward learning, and reinforcement learning (RL). The RLHF process starts with SFT, which fine-tunes pre-trained models on human-generated datasets. Then, a reward model is trained using expert feedback to evaluate model responses, often using a pairwise comparison loss function. The fine-tuning with RL maximizes alignment by solving a KL-regularized optimization problem. Through such iterative fine-tuning of the model, model parameters get adjusted to be aligned better with human preferences. It fine-tuned a prompter model to influence the responses that the model generates. The framework explored how tuning parameters, such as the regularization coefficient (λ), controlled the optimization’s extent, ensuring efficient and computationally feasible alignment.
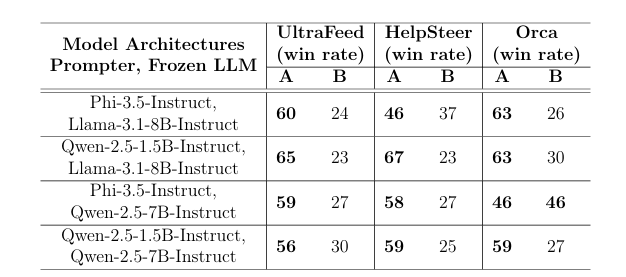
Researchers conducted experiments on the framework using two prompter models, P1 (Phi-3.5-Instruct) and P2 (Qwen-2.5-1.5B-Instruct), along with two frozen models, F1 and F2 (both Llama-3.1-8B-Instruct). The evaluation involved three configurations: no fine-tuning, Align-Pro with a fine-tuned prompter, and RLHF with a fine-tuned model. Performance was tested on three datasets: UltraFeedback, HelpSteer, and Orca, using metrics like mean reward, variance, and win rate comparison. Results showed Align-Pro consistently outperformed the no fine-tuning baseline across all datasets and architectures, with improved mean rewards, lower reward variance, and win rates as high as 67% (e.g., Qwen-2.5-1.5B-Instruct with Llama-3.1-8B-Instruct on HelpSteer) compared to the baseline. The results pointed out that the optimization efficiency in the framework works through prompts without changing the frozen models; standardized hyperparameters further support efficient computational sources.
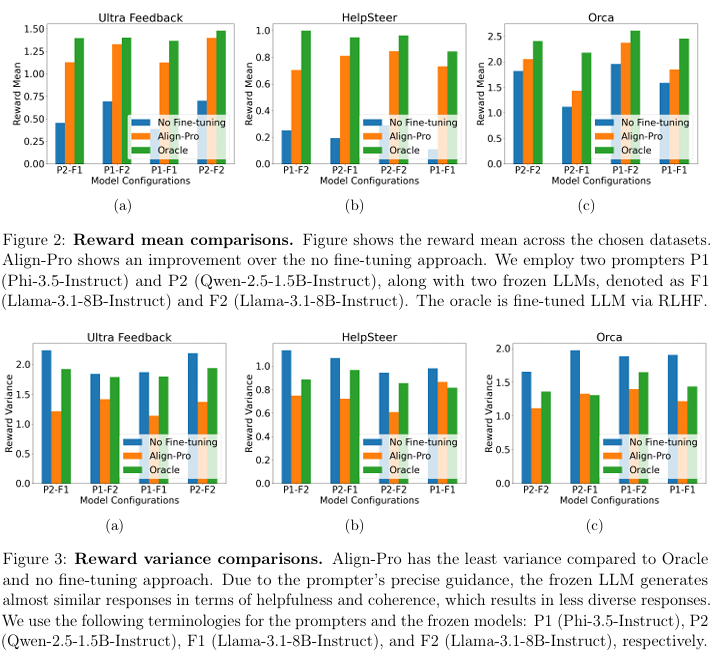
In conclusion, the proposed framework efficiently optimized prompts using a smaller, trainable model to generate prompts for frozen large language models. This reduced computational costs while retaining the LLM’s pre-trained capabilities. The framework outperformed baselines regarding mean rewards and win rates across various datasets and configurations without requiring fine-tuning of the LLM. This efficiency not only reassures the practicality of the framework but also its potential to impact future research in AI and machine learning significantly. The framework can be a baseline for future research, and possible advancements could include analyzing the impact of noise on prompt robustness, sequential prompter designs, and developing theoretical bounds that improve alignment performance in LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post Align-Pro: A Cost-Effective Alternative to RLHF for LLM Alignment appeared first on MarkTechPost.
Source: Read MoreÂ
