




One of the most significant and advanced capabilities of a multimodal large language model is long-context video modeling, which allows models to handle movies, documentaries, and live streams spanning multiple hours. However, despite the commendable advancements made in video comprehension in LLMs, including caption generation and question answering, many obstructions remain in processing extremely long videos. The most crucial of these is understanding the context brought by long videos.
Although much work has already been done in this domain, ranging from training on massive text and frame corpora to building an effective training system with long-context parallelism and data packing, these super-long multimodal contexts have significantly reduced models’ training and inference efficiency. Moreover, the redundancy introduced by frames further complicates model learning. An interesting direction in this field is the compression of video tokens, which shows great potential but suffers from a trade-off in detailed representations. This article presents the latest research on a new compression method for long-context multimodal modeling.
Researchers from the Shenzhen Institutes of Advanced Technology propose a hierarchical video token compression method (HiCo) with a practical context modeling system, VideoChat-Flash, tailored for processing long-context videos. HiCo addresses the visual redundancies in video information by compressing extended contexts from clip to video level to minimize computation while preserving all critical data. VideoChat-Flash, on the other hand, features a multi-stage short-to-long learning scheme along with a rich dataset of real-world long videos. It is an adequate long-video understanding of MLLM with a training infrastructure that supports high-degree sequence parallelism.
HiCo compresses tokens hierarchically to obtain high-density token representations and widen the context window. The authors sequentially segment long videos into shorter clips and feed them into the MLLM. The compression is based on spatiotemporal redundancies. HiCo further links the compressed tokens with user queries and exploits semantic correlations between clips and real-world embeddings to reduce the token quantity.
Next, in VideoChat-Flash, which employs a multi-stage short-to-long learning scheme and a corresponding data receipt, the authors begin supervised fine-tuning with short videos and associated captions and QAs, gradually shifting to long videos, and ultimately training on a mixed-length corpus. Short videos prove highly effective in enhancing basic visual perception and concisely expressing long videos. The authors provide a massive dataset for fine-tuning, encompassing 300,000 hours of videos with annotations spanning 2 billion words.
Another innovation proposed in the paper is a modified “Needle in a Haystack” (NIAH) task for multi-hop video configurations. Conventionally, the NIAH task evaluates a model by requiring it to locate an indicated image, find a target word, or answer a question in a video. Here, a target image is typically inserted into video frames, which the model can identify through visual distinction without understanding the context. To address this loophole, the authors proposed a new benchmark, “multi-hop needle in a video haystack,” which requires the model to locate a sequence of interconnected indicative images, where subsequent images can only be found using clues from the first image.
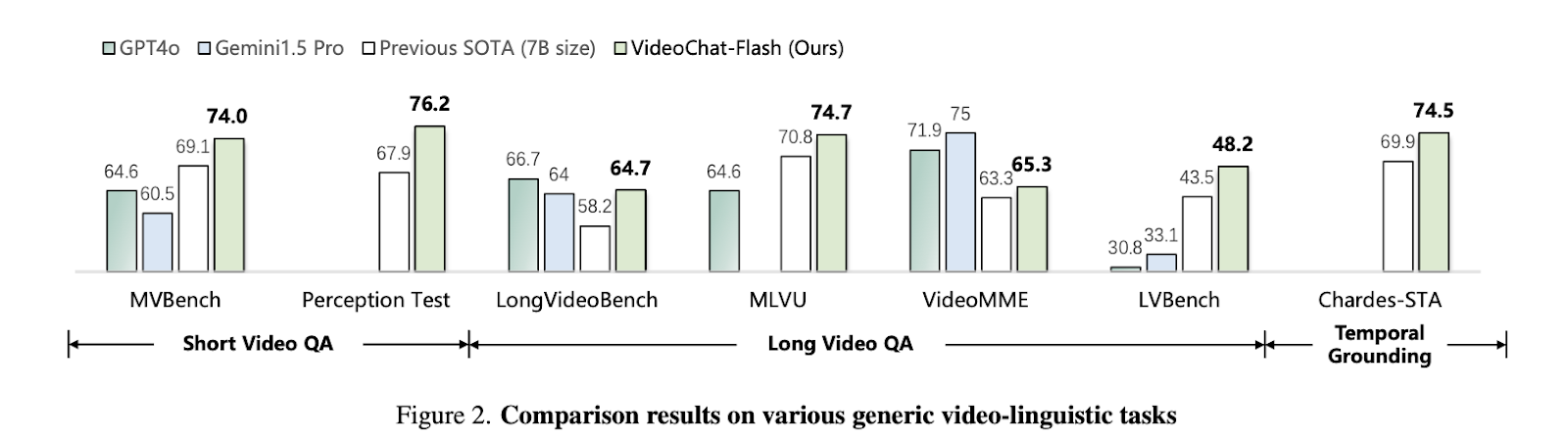
The proposed method achieved a computational reduction of up to two orders of magnitude in experiments. VideoChat-Flash, in particular, demonstrated remarkable performance on both mainstream short and long video benchmarks at 2B and 7B scales. The authors surpassed all other methods for the 7B scale model, proclaiming it as the new state-of-the-art in short video understanding. Even in long-video comprehension, their model outperformed previous open-source MLLMs, achieving SOTA in several benchmarks. The proposed model also exhibited strong temporal grounding capabilities, with zero-shot performance exceeding many renowned MLLMs. Additionally, VideoChat-Flash achieved an astounding accuracy of 99.1% on over 10,000 frames in NIAH.
Conclusion: The authors introduced a hierarchical compression technique, HiCo, and VideoChat-Flash, an MLLM trained using an innovative multi-stage scheme. This method advanced compression techniques to reduce computations for long-context videos while surpassing the accuracies of current SOTA models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.

The post Researchers from China Develop Advanced Compression and Learning Techniques to process Long-Context Videos at 100 Times Less Compute appeared first on MarkTechPost.
Source: Read MoreÂ
