




Multi-hop queries have always given LLM agents a hard time with their solutions, necessitating multiple reasoning steps and information from different sources. They are crucial for analyzing a model’s comprehension, reasoning, and function-calling capabilities. At this time when new large models are booming every other day with claims of unparalleled capabilities, multi-hop tools realistically assess them by bestowing with a complex query, which the model needs to decompose into atomic parts and iteratively solve by invoking and utilizing appropriate tools. Furthermore, multi-hop tool evaluation has emerged as pivotal for advancing models toward generalized intelligence.
Existing works in this field fall short of offering a reliable evaluation method. Methods proposed until now have relied on tool-driven data construction methods where queries are simulated for a given collection of tools. This shortfall points out the loophole in ensuring the interdependence of collected tools and assessing the multi-hop reasoning. Additionally, the absence of verifiable answers introduces model bias and evaluation errors. This article discusses the latest research that presents a reliable method to honestly assess the multi-hop capabilities of a large language model.
Fudan University and ByteDance researchers presented ToolHop, a dataset designed explicitly for multi-hop tool evaluation with 995 rigorously designed user queries and 3,912 associated tools. Toolhop claims to solve all the aforementioned problems through diverse queries, locally executable tools, meaningful interdependencies, detailed feedback, and verifiable answers. The authors propose a novel query-driven data construction approach that could expand a single multi-hop query into a comprehensive multi-hop tool use test case.
The proposed novel scheme comprises three key stages: tool creation, document refinement, and code generation.
Tool Creation: A preliminary set of tool documents is created per the user-provided multi-hop query. The document is designed to keep it interdependent and relevant by resolving queries into atomic parts and individually handling each. This way, the document captures the essence of the query and structures itself to generate similar queries, ensuring modularity and cohesion.
Document Refinement: The prepared tool document undergoes comprehensive filtering to support the evaluation of models in complex multi-hop scenarios. Here, new features like result filtering and customizable formats are introduced to expand functionality while maintaining originality. Parallelly, the number of parameters is increased, and their types are optimized.
Code Generation: At this stage, locally executable functions are generated by the prepared tool. Through these functions, tools are externally invoked, enabling seamless multi-turn interactions between the model and tools.
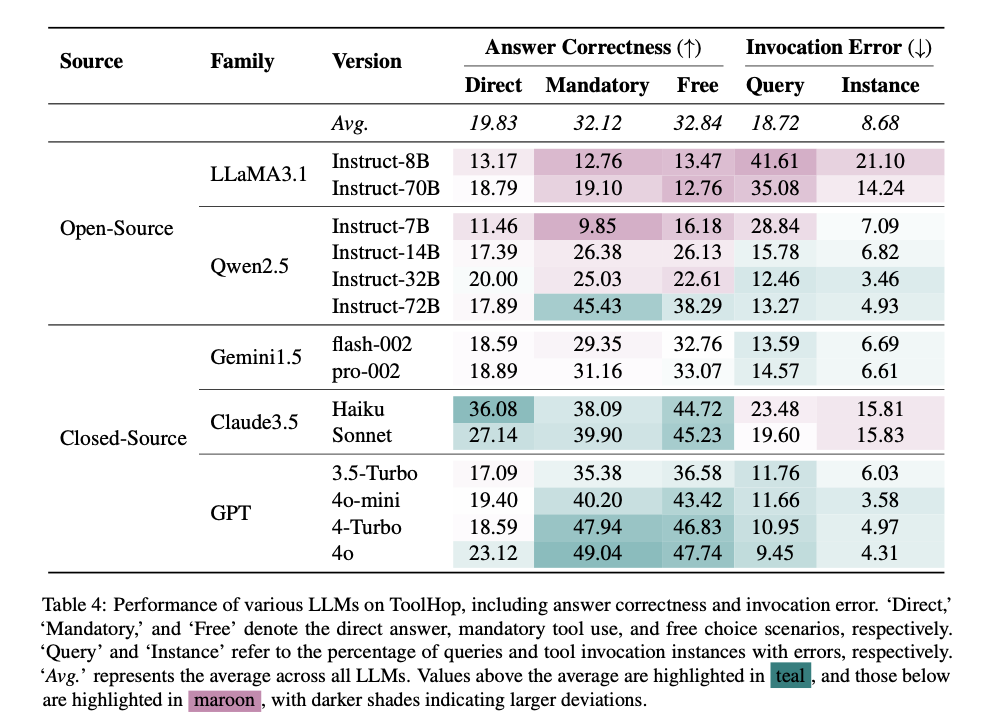
The research team implemented the approach with the queries drawn from the MoreHopQA dataset. Further, to ensure the evaluation with ToolHop, a rigorous five-dimensional analysis was done. ToolHop was then evaluated on fourteen LLMs from five families, including open and closed-sourced models. The evaluation method was so designed that answer correctness and minimized invocation errors were ensured. The authors observed that using tools increased the models’ performance by up to 12 % on average and by up to 23 % for GPT models. The best-performing model could achieve 49.04% answer correctness even after the increase. Also, despite using tools in response to multi-hop queries, models hallucinated around 10% of the time.
Conclusion:
This paper presents a comprehensive dataset for solving multi-hop queries using specially designed queries and tools. The main finding from the experiments was that while LLMs have significantly enhanced their ability to solve complex multi-shop queries with the use of tools, their multi-shop tool use capabilities still leave considerable room for improvement.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post ToolHop: A Novel Dataset Designed to Evaluate LLMs in Multi-Hop Tool Use Scenarios appeared first on MarkTechPost.
Source: Read MoreÂ
