




Large Language Models (LLMs) aim to align with human preferences, ensuring reliable and trustworthy decision-making. However, these models acquire biases, logical leaps, and hallucinations, rendering them invalid and harmless for critical tasks involving logical thinking. Logical consistency problems make it impossible to develop logically consistent LLMs. They also use temporal reasoning, optimization, and automated systems, resulting in less reliable conclusions.
Current methods for aligning Large Language Models (LLMs) with human preferences rely on supervised training with instruction-following data and reinforcement learning from human feedback. However, these methods suffer from problems such as hallucination, bias, and logical inconsistency, thereby undermining the validity of LLMs. Most improvements to LLM consistency have thus been made on simple factual knowledge or simple entailment between just a few statements while neglecting other, more intricate decision-making scenarios or tasks involving more than one item. This gap limits their ability to provide coherent and dependable reasoning in real-world applications where consistency is essential.
To evaluate logical consistency in large language models (LLMs), researchers from the University of Cambridge and Monash University proposed a universal framework to quantify the logical consistency by assessing three key properties: transitivity, commutativity, and negation invariance. Transitivity ensured that if a model determined that one item was preferred over a second and the second over a third, it also concluded that the first item was chosen over the third. Commutativity ensured that the model’s judgments remained the same regardless of the order in which the items were compared.
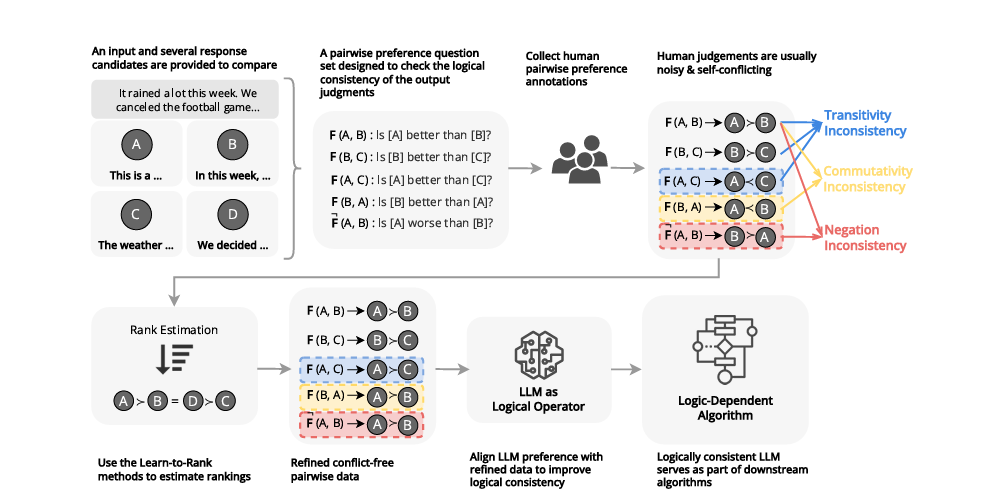
At the same time, negation invariance was checked for consistency in handling relational negations. These properties formed the foundation for reliable reasoning in models. The researchers formalized the evaluation process by treating an LLM as an operator function FFF that compared pairs of items and assigned relational decisions. Logical consistency was measured using metrics like stran(K)s_{tran}(K)stran(K) for transitivity and scomms_{comm}scomm for commutativity. Stran (K)s_{tran}(K)stran(K) quantified transitivity by sampling subsets of items and detecting cycles in the relation graph. At the same time, scomms_{comm}scomm evaluated whether the model’s judgments remained stable when the order of items in comparisons was reversed. Both metrics ranged from 0 to 1, with higher values indicating better performance.
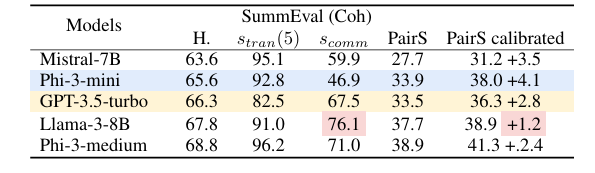
Researchers applied these metrics to various LLMs, revealing vulnerabilities to biases like permutation and positional bias. To address this, they introduced a data refinement and augmentation technique using rank aggregation methods to estimate partial or ordered preference rankings from noisy or sparse pairwise comparisons. This improved logical consistency without compromising alignment with human preferences and emphasized the essential role of logical consistency in improving logic-dependent algorithm performance.
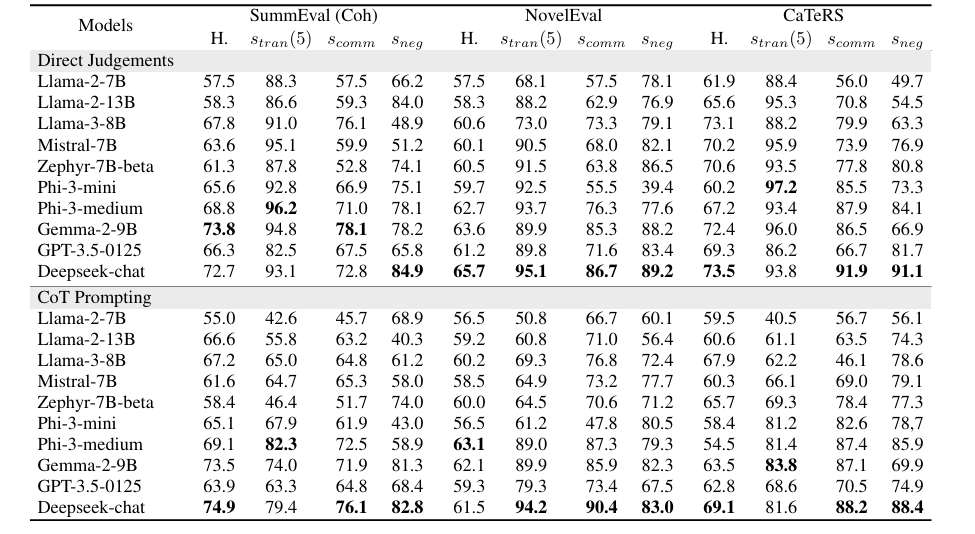
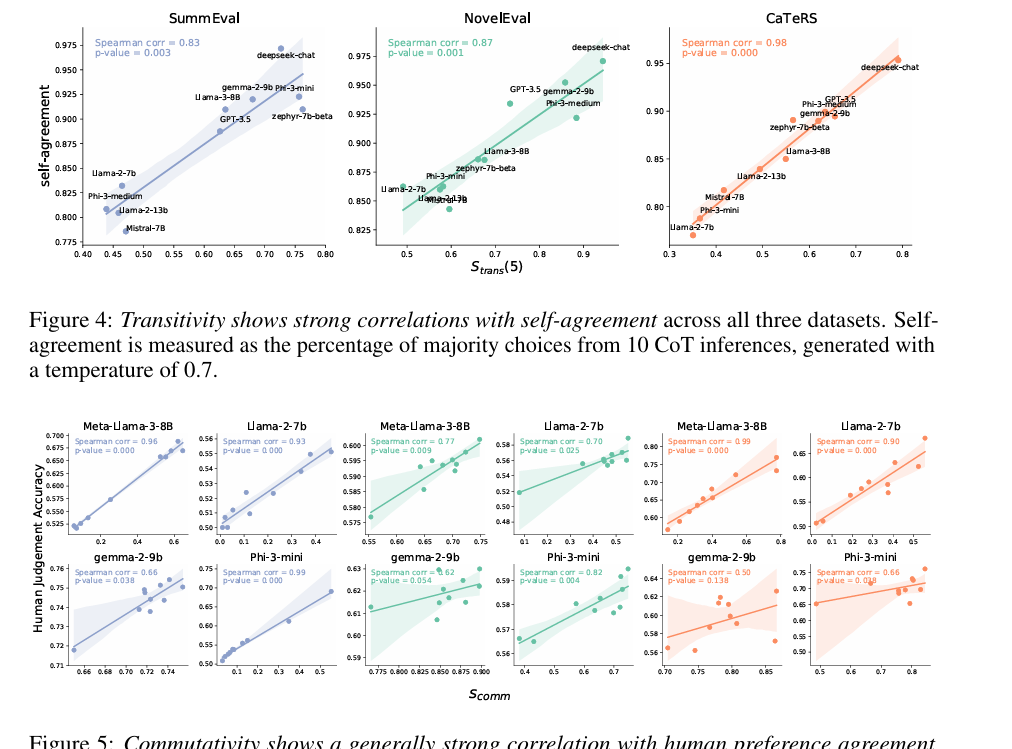
Researchers tested three tasks to evaluate logical consistency in LLMs: abstractive summarization, document reranking, and temporal event ordering using datasets like SummEval, NovelEval, and CaTeRS. They assessed transitivity, commutativity, negation invariance, and human and self-agreement. Results showed that newer models like Deepseek-chat, Phi-3-medium, and Gemma-2-9B had higher logical consistency, though this did not correlate strongly with human agreement accuracy. The CaTeRS dataset showed stronger consistency, focusing on temporal and causal relations. Chain-of-thought prompting had mixed results, sometimes reducing transitivity due to added reasoning tokens. Self-agreement was related to transitivity; this shows that consistent reasoning is fundamental for logical consistency, and models such as Phi-3-medium and Gemma-2-9B have equal reliability for each task, emphasizing the necessity for cleaner training data.
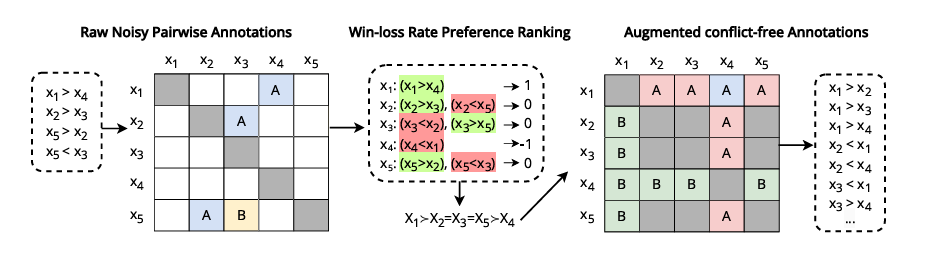
In the end, researchers showed the importance of logical consistency in enhancing the reliability of large language models. They presented a method for measuring the key aspects of consistency and explained a data-cleaning process that reduces the number of defaults while still being pertinent to humans. This framework can further be used as a guideline for subsequent research in improving the consistency of LLMs and for continuing efforts to implement LLMs into decision-making systems for enhanced effectiveness and productivity.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post From Contradictions to Coherence: Logical Alignment in AI Models appeared first on MarkTechPost.
Source: Read MoreÂ

