




Video-Language Representation Learning is a crucial subfield of multi-modal representation learning that focuses on the relationship between videos and their associated textual descriptions. Its applications are explored in numerous areas, from question answering and text retrieval to summarization. In this regard ,contrastive learning has emerged as a powerful technique that elevates video-language learning by enabling networks to learn discriminative representations. Here, global semantic interactions between predefined video-text pairs are utilized for learning.
One big issue with this method is that it undermines the model’s quality on downstream tasks. These models typically use video-text semantics to perform coarse-grained feature alignment. Contrastive Video Models are, therefore, unable to align fine-tuned annotations that capture the subtleties and interpretability of the video. The naïve approach to solving this problem of fine-grained annotation would be to create a massive dataset of high-quality annotations, which is unfortunately unavailable, especially for vision-language models. This article discusses the latest research that solves the problem of fine-grained alignment through a game.
Peking University and Pengcheng Laboratory researchers introduced a hierarchical Banzhaf Interaction approach to solve alignment issues in General Video-Language representation learning by modeling it as a multivariate cooperative game. The authors designed this game with video and text formulated as players. For this purpose, they grouped the collection of multiple representations as a coalition and used Banzhaf Interaction, a game-theoretic interaction index, to measure the degree of cooperation between coalition members.
The research team extends upon their conference paper on a learning framework with a Hierarchical Banzhaf Interaction, where they leveraged cross-modality semantics measurement as functional characteristics of players in the video-text cooperative game. In this paper, the authors propose HBI V2, which leverages single-modal and cross-modal representations to mitigate the biases in the Banzhaf Index and enhance video-language learning. In HBI V2, the authors reconstruct the representations for the game by integrating single and cross-modal representations, which are dynamically weighted to ensure fine granularity from individual representations while preserving the cross-modal interactions.
Regarding impact, HBI V2 surpasses HBI with its capability to perform various downstream tasks, from text-video retrieval to VideoQA and video captioning. To achieve this, the authors modified their previous structure into a flexible encoder-decoder framework, where the decoder is adapted for specific tasks.
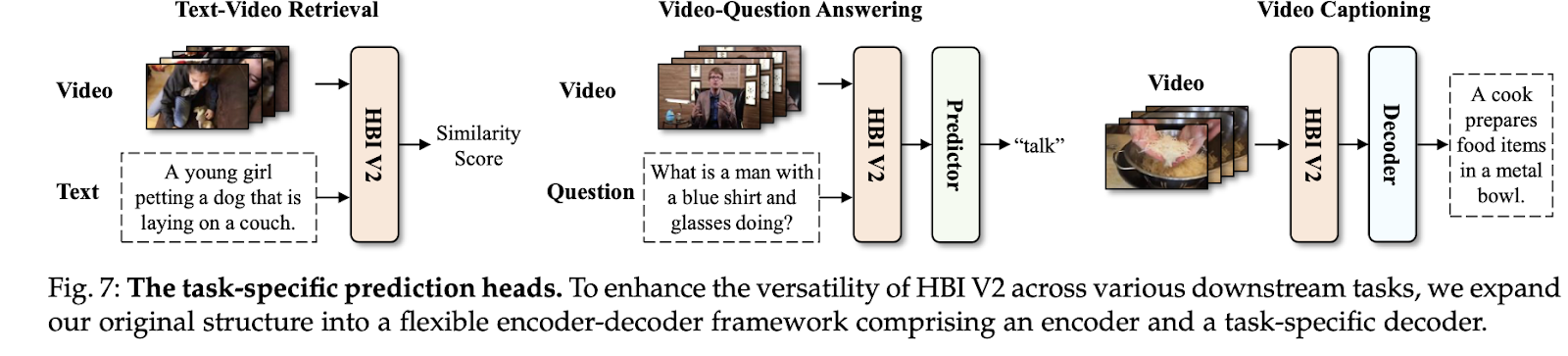
This framework of HBI V2 is divided into three submodules: Representation-Reconstruction, the HBI Module, and Task-Specific Prediction Heads. The first module facilitates the fusion of single and cross-modal components. The research team used CLIP to generate both representations. For video input, frame sequences are encoded into embeddings with ViT. This component integration helped overcome the problems of dynamically encoding video while preserving inherent granularity and adaptability. For the HBI module, the authors modeled video text as players in a multivariate cooperative game to handle the uncertainty during fine-grained interactions. The first two modules provide flexibility to the framework, enabling the third module to be tailored for a given task without requiring sophisticated multi-modal fusion or reasoning stages.

In the paper, HBI V2 was evaluated on various text-video retrieval, video QA, and video captioning datasets with the help of multiple suitable metrics for each. Surprisingly, the proposed method outperformed its predecessor and all other methods on all the downstream tasks. Additionally, the framework achieved notable advancements over HBI on the MSVD-QA and ActivityNet-QA datasets, which assessed its question-answering abilities. Regarding reproducibility and inference, the inference time was 1 second for the whole test data.
Conclusion: The proposed method uniquely and effectively utilized Banzhaf Interaction to provide fine-grained labels for a video-text relationship without manual annotations. HBI V2 extended upon the preceding HBI to infuse the granularities of single representation into cross-modal representations. This framework exhibited superiority and the flexibility to perform various downstream tasks.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post HBI V2: A Flexible AI Framework that Elevates Video-Language Learning with a Multivariate Co-Operative Game appeared first on MarkTechPost.
Source: Read MoreÂ

