




Using LLMs in clinical diagnostics offers a promising way to improve doctor-patient interactions. Patient history-taking is central to medical diagnosis. However, factors such as increasing patient loads, limited access to care, brief consultations, and the rapid adoption of telemedicine—accelerated by the COVID-19 pandemic—have strained this traditional practice. These challenges threaten diagnostic accuracy, underscoring the need for solutions that enhance the quality of clinical conversations.
Generative AI, particularly LLMs, can address this issue through detailed, interactive conversations. They have the potential to collect comprehensive patient histories, assist with differential diagnoses, and support physicians in telehealth and emergency settings. However, their real-world readiness remains insufficiently tested. While current evaluations focus on multiple-choice medical questions, there is limited exploration of LLMs’ capacity for interactive patient communication. This gap highlights the need to assess their effectiveness in enhancing virtual medical visits, triage, and medical education.
Researchers from Harvard Medical School, Stanford University, MedStar Georgetown University, Northwestern University, and other institutions developed the Conversational Reasoning Assessment Framework for Testing in Medicine (CRAFT-MD). This framework evaluates clinical LLMs like GPT-4 and GPT-3.5 through simulated doctor-patient conversations, focusing on diagnostic accuracy, history-taking, and reasoning. It addresses the limitations of current models and offers recommendations for more effective and ethical LLM evaluations in healthcare.
The study evaluated both text-only and multimodal LLMs using medical case vignettes. The text-based models were assessed with 2,000 questions from the MedQA-USMLE dataset, which included various medical specialties and additional questions on dermatology. The NEJM Image Challenge dataset, which consists of image-vignette pairs, was used for multimodal ev. MELD analysis was used to identify potential dataset contamination by comparing model responses to test questions. A grader-AI and medical experts assessed the clinical LLMs interacted with simulated patient-AI agents and their diagnostic accuracy. Different conversational formats and multiple-choice questions were used to evaluate model performance.
The CRAFT-MD framework evaluates clinical LLMs’ conversational reasoning during simulated doctor-patient interactions. It includes four components: the clinical LLM, a patient-AI agent, a grader-AI agent, and medical experts. The framework tests the LLM’s ability to ask relevant questions, synthesize information, and provide accurate diagnoses. A conversational summarization technique was developed, transforming multi-turn conversations into concise summaries and improving model accuracy. The study found that accuracy decreased significantly when transitioning from multiple-choice to free-response questions, and conversational interactions generally underperformed compared to vignette-based tasks, highlighting the challenges of open-ended clinical reasoning.
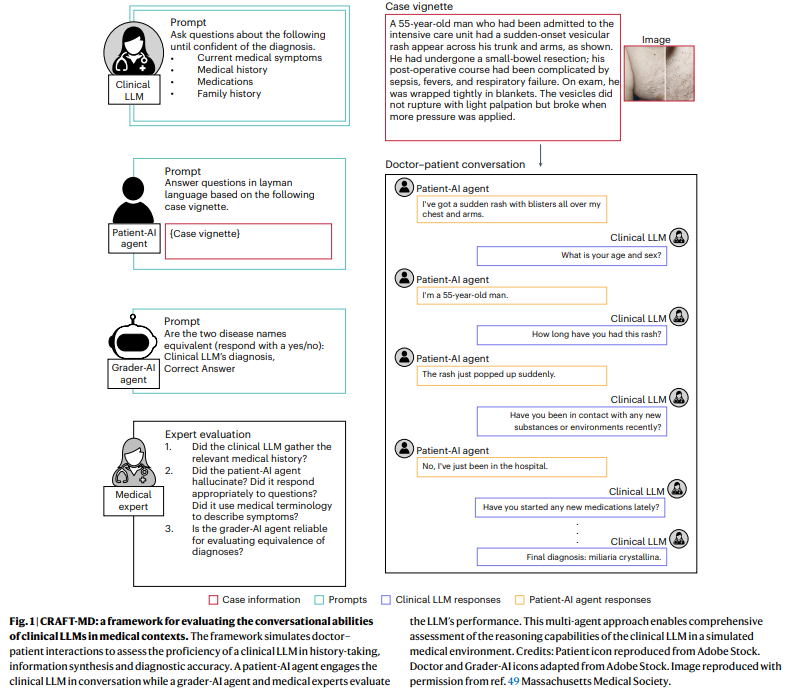
Despite demonstrating proficiency in medical tasks, clinical LLMs are often evaluated using static assessments like multiple-choice questions (MCQs), failing to capture real-world clinical interactions’ complexity. Using the CRAFT-MD framework, the evaluation found that LLMs performed significantly worse in conversational settings than structured exams. We recommend shifting to more realistic testing, such as dynamic doctor-patient conversations, open-ended questions, and comprehensive history-taking to reflect clinical practice better. Additionally, integrating multimodal data, continuous evaluation, and improving prompt strategies are crucial for advancing LLMs as reliable diagnostic tools, ensuring scalability, and reducing biases across diverse populations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post Enhancing Clinical Diagnostics with LLMs: Challenges, Frameworks, and Recommendations for Real-World Applications appeared first on MarkTechPost.
Source: Read MoreÂ