




Breaking down videos into smaller, meaningful parts for vision models remains challenging, particularly for long videos. Vision models rely on these smaller parts, called tokens, to process and understand video data, but creating these tokens efficiently is difficult. While recent tools achieve better video compression than older methods, they struggle to handle large video datasets effectively. A key issue is their inability to fully utilize temporal coherence, the natural pattern where video frames are often similar over short periods, which video codecs use for efficient compression. These tools are also computationally expensive to train and are limited to short clips, making them not very effective in capturing patterns and processing longer videos.

Current video tokenization methods have high computational costs and struggle to handle long video sequences efficiently. Early approaches used image tokenizers to compress videos frame by frame but ignored the natural continuity between frames, reducing their effectiveness. Later methods introduced spatiotemporal layers, reduced redundancy, and used adaptive encoding, but they still required rebuilding entire video frames during training, which limited them to short clips. Video generation models like autoregressive methods, masked generative transformers, and diffusion models are also limited to short sequences.
To solve this, researchers from KAIST and UC Berkeley proposed CoordTok, which learns a mapping from coordinate-based representations to the corresponding patches of input videos. Motivated by recent advances in 3D generative models, CoordTok encodes a video into factorized triplane representations and reconstructs patches corresponding to randomly sampled (x, y, t) coordinates. This approach allows large tokenizer models to be trained directly on long videos without requiring excessive resources. The video is divided into space-time patches and processed using transformer layers, with the decoder mapping sampled (x, y, t) coordinates to corresponding pixels. This reduces both memory and computational costs while preserving video quality.
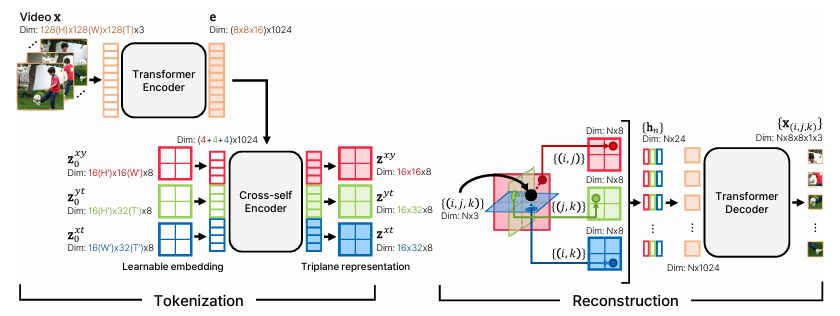
Based on this, researchers updated CoordTok to efficiently process a video by introducing a hierarchical architecture that grasped local and global features from the video. This architecture represented a factorized triplane to process patches of space and time, making long-duration video processing easier without excessively using computational resources. This approach greatly reduced the memory and computation requirements and maintained high video quality.

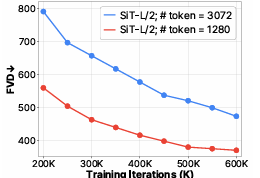

Researchers improved the performance by adding a hierarchical structure that captured the local and global features of videos. This structure allowed the model to process space-time patches more efficiently using transformer layers, which helped generate factorized triplane representations. As a result, CoordTok handled longer videos without demanding excessive computational resources. For example, CoordTok encoded a 128-frame video with 128×128 resolution into 1280 tokens, while baselines required 6144 or 8192 tokens to achieve similar reconstruction quality. The model’s reconstruction quality was further improved by fine-tuning with both ℓ2 loss and LPIPS loss, enhancing the accuracy of the reconstructed frames. This combination of strategies reduced memory usage by up to 50% and computational costs while maintaining high-quality video reconstruction, with models like CoordTok-L achieving a PSNR of 26.9.
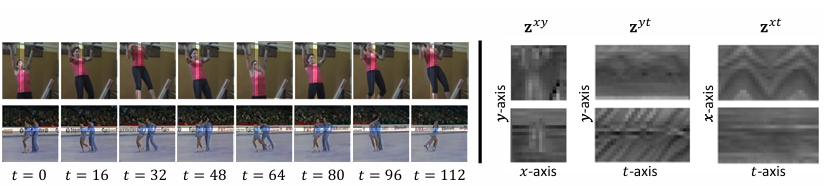
In conclusion, the proposed framework by researchers, CoordTok, proves to be an efficient video tokenizer that uses coordinate-based representations to reduce computational costs and memory requirements while encoding long videos.
It allows memory-efficient training for video generation models, making handling long videos with fewer tokens possible. However, it is not strong enough for dynamic videos and suggests further potential improvements, such as using multiple content planes or adaptive methods. This work can serve as a starting point for future research on scalable video tokenizers and generation, which can be beneficial for comprehending and generating long videos.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post CoordTok: A Scalable Video Tokenizer that Learns a Mapping from Co-ordinate-based Representations to the Corresponding Patches of Input Videos appeared first on MarkTechPost.
Source: Read MoreÂ
