


Key Takeaways
-
Silent data corruption—rare events in which data becomes corrupt in a way that is not readily detected—can impact systems of all kinds across the software industry.
-
MongoDB Atlas, our global cloud database service, operates at petabyte scale, which requires sophisticated solutions to manage the risk of silent data corruption. Because MongoDB Atlas itself relies on cloud services, the systems we have engineered to safeguard customer data have to account for limited access to the physical hardware behind our infrastructure.
-
The systems we have implemented consist of software-level techniques for proactively detecting and repairing instances of silent data corruption. These systems include monitoring for checksum failures and similar runtime evidence of corrupt data, methods of identifying corrupt documents by leveraging MongoDB indexes and replication, and processes for repairing corrupt data by utilizing the redundant replicas.
Introduction: Hardware corruption in the cloud
As a cloud platform, MongoDB Atlas promises to free its customers from the work of managing hardware. In our time developing Atlas, however, some hardware problems have been challenging to abstract away. One of the most notable of these is silent data corruption. No matter how well we design our software, in rare cases hardware can silently fail in ways that compromise data. Imagine, for example, a distance sensor that detects an obstacle 10 meters away. Even if the many layers of software handling the sensor’s data function flawlessly (application, network, database, operating system, etc.), if an unlucky memory chip has a single bit flipped by radiation the value of this measurement could mutate to something like 26.1 The consequences of this botched measurement would depend on how this data is used: in some cases it may introduce a blip in a vast amount of research data,2 but in the wrong system it could be dangerous.
Despite the rarity of events like this, global cloud systems like MongoDB Atlas operate at such a scale that these events become statistically inevitable over time, even in the presence of existing manufacturer defect screening. Our platform currently stores petabytes of data and operates nearly half a million virtual machines in cloud datacenters in dozens of countries; even random failures with odds as low as one in a hundred thousand become likely to appear in such an environment. Complicating this further is the reality that silent data corruption has many possible causes beyond rare, random failures like the example of radiation above. Recent research has identified notable rates of data corruption originating from defective CPUs in large-scale data centers,3 and corruption can just as easily originate from bugs in operating systems or other software. Considering this scope, and with limited levels of access to the cloud hardware we use to power MongoDB Atlas, how can we best stay ahead of the inevitability of silent data corruption affecting customers on our platform?
Our response to this problem has been to implement features both in the MongoDB database and the orchestration software that powers MongoDB Atlas for continuously detecting and repairing silent data corruption. Our systems are designed to be proactive, identifying potential issues before they ever affect customer data or operations. The way we use these systems can be described in three steps. First, Atlas proactively monitors for signals of corrupt data from across our fleet of databases by checking for certain logical truths about data in the course of runtime operations. Then, in the case that evidence of corruption is identified, we utilize features in MongoDB for scanning databases to pinpoint the location of corrupt data, narrowing down the site of corruption to specific documents. Finally, once we have enough information to identify a remediation plan, we repair corruption in coordination with our customers by leveraging the redundancy of MongoDB’s replica set deployment model. As a whole this approach gives us early visibility into new types of data corruption that emerge in our fleet, as well as the tools we need to pinpoint and repair corruption when it occurs.
Proactively monitoring for evidence of corruption
Fortunately for anyone interested in managing silent data corruption at scale, databases tend to tell you a lot about what they observe. In the course of a single day, the hundreds of thousands of database processes in the Atlas fleet generate terabytes of database logs describing their operations: connections received from clients, the details of startup and shutdown procedures, queries that are performing poorly. At their worst, logs at this scale can be expensive to store and difficult to parse, but at their best they are an indispensable diagnostic tool. As such, the first step of our strategy for managing corruption in Atlas is strategic log management.
There are several points in the course of a MongoDB database’s operations where we can proactively validate logical assumptions about the state of data and emit messages if something appears to be corrupt. The most fundamental form of this validation we perform is checksum validation. A checksum is a very small piece of information that is deterministically generated from a much larger piece of information by passing it through a mathematical function. When the storage engine for an Atlas cluster writes data to disk, each block–or individual unit of data written–is accompanied by a checksum of the data. When that block is later read from disk, the storage engine once again passes the data through the checksum function and verifies that the output matches the checksum that was originally stored. If there is a mismatch, we have a strong reason to suspect that the stored information is corrupt; the database process then emits a log line indicating this and halts further execution. You can see this behavior in the MongoDB source code here.
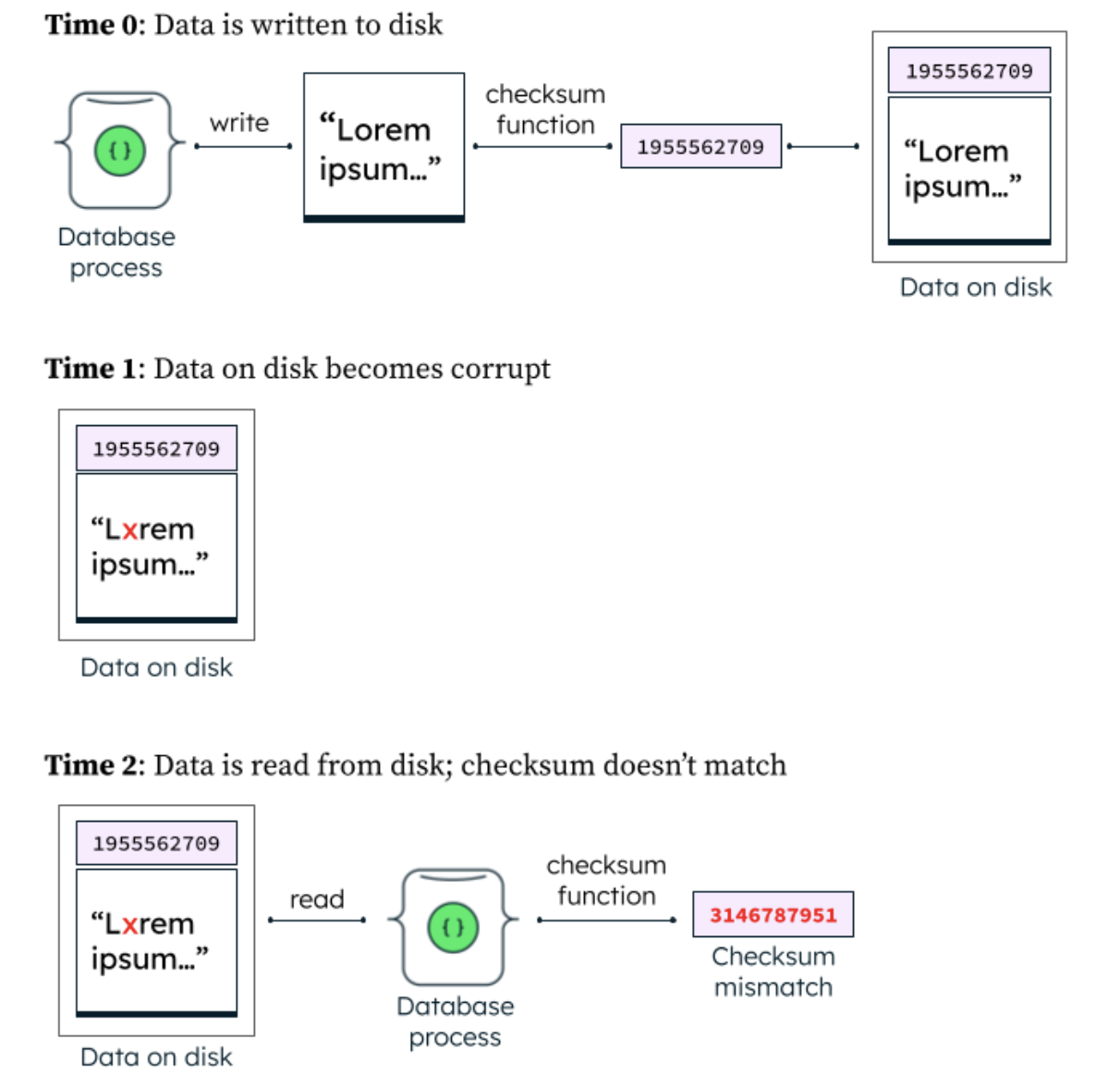
In addition to checksums, there are other opportunities for checking basic assumptions about the data we are handling during routine MongoDB operations. For example, when iterating through a list of values that is expected to be in ascending order, if we find that a given value is actually less than the one that preceded it we can also reasonably suspect that a piece of information is corrupt. Similar forms of validation exist in dozens of places in the MongoDB database. Successfully leveraging these types of runtime errors in the context of the entire Atlas fleet, however, comes with some challenges. We need to quickly detect these messages from among the flood of logs generated by the Atlas fleet, and, importantly, do so in a way that maintains data isolation for the many individual customer applications running on Atlas. Database logs, by design, reveal a lot about what is happening in a system; as the creators of a managed database service, exposing the full contents of database logs to our employees for corruption analysis is a non-starter, and so we need a more nuanced method of detecting these signals.
To solve this problem, we implemented a system for detecting certain classes of error as Atlas database logs are generated and emitting high-level metadata that can be analyzed by our teams internally without revealing sensitive information about the content or operations of a given database. To describe this system, it is first useful to understand a pair of concepts that we often reference internally, and which play an important role in the development of the Atlas platform, the data plane and the control plane.
The data plane describes the systems that manage the data that resides in a given Atlas cluster. It consists of the virtual network containing the cluster’s resources, the virtual machines and related resources hosting the cluster’s database processes, and storage for diagnostic information like database logs. As a whole, it consists of many thousands of individual private networks and virtual machines backing the Atlas fleet of database clusters. The control plane, on the other hand, is the environment in which the Atlas management application runs. It consists of separate networks hosting our own application processes and backing databases, and stores all of the operational metadata required for running Atlas including, for example, metadata about the configurations of the clusters that constitute the Atlas fleet.
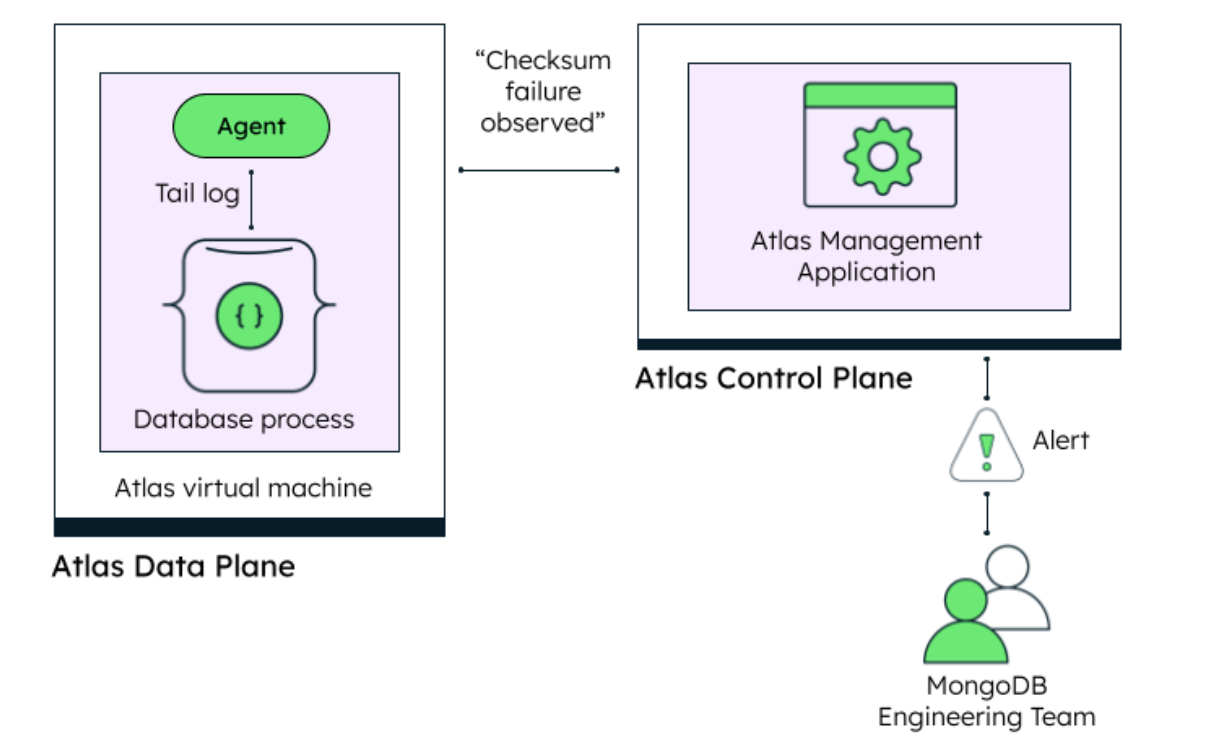
The flow of information between the two planes only occurs on a limited set of vectors, primary among these being the MongoDB Agent, a background process that runs locally on virtual machines in the Atlas data plane. The Agent serves as the primary orchestrator of a cluster’s database processes. Whenever an Atlas customer requests a change to their cluster–for example, upgrading the version of their database–their request results in some modification to metadata that resides in the control plane which is then picked up by the Agents in the data plane. The Agents then begin to interact with the individual database processes of the cluster to bring them to the desired state.
The Agent, with its ability to access database logs inside the data plane, provides the tool we need to detect critical logs in a controlled manner. In fact, at the time we implemented the feature for ingesting these logs, the Agent was already capable of tailing MongoDB logs in search of particular patterns. This is how the Performance Advisor feature works, in which the Agent looks for slow query logs above a certain operation duration threshold to alert users of potentially inefficient data queries. For the purposes of corruption detection we introduced a new feature for defining additional log patterns for the Agent to look for: for example, a pattern that matches the log line indicating an invalid checksum when data is read from disk. If the Agent observes a line that matches a specified pattern it will send a message to the control plane reporting when the message was observed, in which process, along with high-level information–such as an error code–but without further information about the activity of the cluster.
The next step of this process, once evidence of corruption is detected, is to assess the extent of the problem and gather additional information to inform our response. This brings us to the next piece of our corruption management system: once we become aware of the possibility of corruption, how do we pinpoint it and determine a remediation plan?
Scanning databases to pinpoint identified corruption
So far, we have outlined our system for detecting runtime errors symptomatic of corrupt data. However, the detection of these errors by itself is not sufficient to fully solve the problem of data corruption in a global cloud database platform. It enables early awareness of potential corruption within the Atlas fleet, but when it is time to diagnose and treat a specific case we often need more exhaustive tools. The overall picture here is not unlike the treatment of an illness: so far, what we have described is our system for detecting symptoms. Once symptoms have been identified, further testing may be needed to determine the correct course of treatment. In our case, we may need to perform further scanning of data to identify the extent of corruption and the specific information affected.
The ability to scan MongoDB databases for corruption relies on two of the most fundamental concepts of a database, indexes and replication. These two basic features of MongoDB each come with certain simple logical assumptions that they adhere to in a healthy state. By scanning for specific index entries or replicated data that violate these assumptions, we are able to pinpoint the location of corrupt data, a necessary step towards determining a remediation path.
Indexes–data structures generated by a database to allow for quick lookup of information–relate to the contents of a database following specific logical constraints. For example, if a given collection is using an index on the lastName field and contains a document with a lastName value of “Turing,†the value “Turing†should be present in that collection’s index keys. A violation of this constraint, therefore, could point to the location of corrupt data; the absence of an in-use lastName value in the index would indicate that either the index has become corrupt or the lastName value on the document itself has become corrupt. Because almost all indexes are specified by the customer, Atlas does not have control over how the data in a cluster is indexed. In practice, though, the most frequently-accessed data tends to be highly indexed, making index scanning a valuable tool in validating the most critical data in a cluster.
Replicated data, similarly, adheres to certain constraints in a healthy state: namely, that replicas of data representing the same point in time should be identical to one another. As such, replicated data within a database can also be scanned at a common point in time to identify places where data has diverged as a result of corruption. If two of three replicas in a cluster show a lastName value of “Turing†for a given document but the third shows “Toringâ€4, we have a clear reason to suspect that this particular document’s data has become corrupt. Since all Atlas clusters are deployed with at least three redundant copies of data, replication is always available to be leveraged when repairing corruption on Atlas.
This is, of course, easier said than done. In practice, performing integrity scanning of indexes and replicated data for a very large database requires processing a large amount of complex data. In the past, performing such an operation was often infeasible on a database cluster that was actively serving reads and writes. The db.collection.validate command was one of the first tools we developed at MongoDB for performing integrity scans of index data, but it comes with certain restrictions. The command obtains an exclusive lock on the collection it is validating, which means it will block reads and writes on the collection until it is finished. We still use this command as part of our corruption scanning strategy, but because of its limitations this means it is often only feasible to run on an offline copy of a database restored from a backup snapshot. This can be expensive, and comes with the overhead of managing additional hardware for performing validations on offline copies. With this in mind, we have been developing new tools for scanning for data corruption that are more feasible to run in the background of a cluster actively serving traffic.
Our latest tools for detecting inconsistencies in replica sets utilize the replication process to perform background validation of data while a cluster is processing ordinary operations, and can be rate-limited based on the available resources on the cluster. When this process is performed, the primary node will begin by iterating through a collection in order, pulling a small batch of data into memory that stays within the bounds of a specified limit. It will make note of the range of the data being analyzed and produce an MD5 hash, writing this information to an entry in the oplog, a transaction log maintained by MongoDB that is replayed by secondary nodes in the database. When the secondaries of the cluster encounter this entry in their copies of the oplog, they perform the same calculation based on their replicas of the data, generating their own hash belonging to the indicated range of data at the specified point in time. By comparing a secondary’s hash with the original hash recorded by the primary, we can determine whether or not this batch of data is consistent between the two nodes. The result of this comparison (consistent or inconsistent) is then logged to an internal collection in the node’s local database. In this manner small batches of data are processed until the collection has been fully scanned.
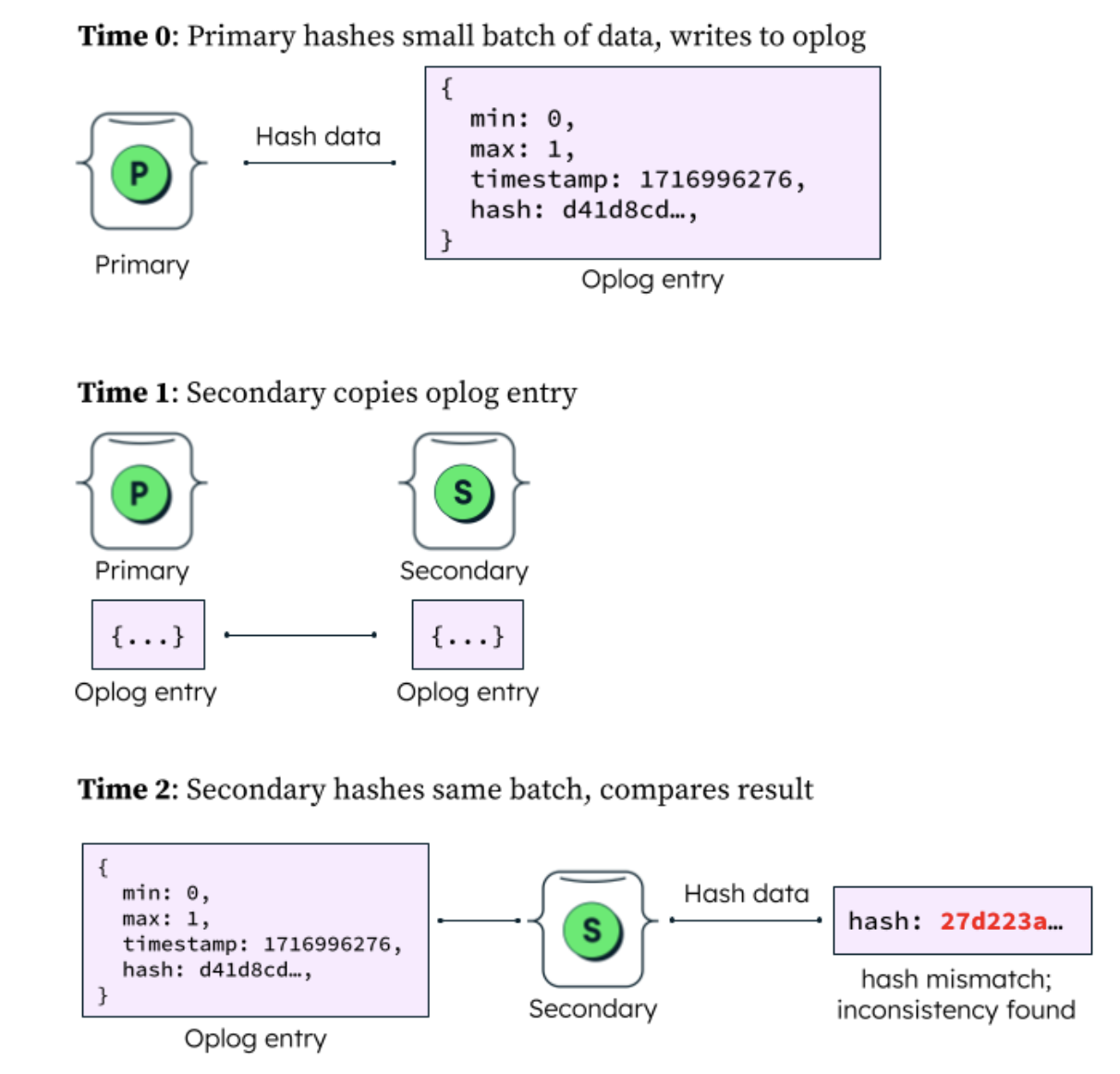
This form of online data consistency scanning has allowed us to scan our own internal databases without interruption to their ordinary operations, and is a promising tool for expanding the scale of our data corruption scanning without needing to manage large amounts of additional hardware for performing offline validations. We do, nonetheless, recognize there will be some cases where running an online validation may be unviable, as in the cases of clusters with very limited available CPU or memory. For this reason, we continue to utilize offline validations as part of our strategy, trading the cost of running additional hardware for the duration of the validation for complete isolation between the validation workload and the application workload. Overall, utilizing both online and offline approaches in different cases gives us the flexibility we need to handle the wide range of data characteristics we encounter.
Repairing corruption
Once the location of corrupt data has been identified, the last step in our process is to repair it. Having several redundant copies of data in an Atlas cluster means that more often than not it is straightforward to rebuild the corrupt data. If there is an inconsistency present on a given node in a cluster, that node can be rebuilt by triggering an initial sync and designating a known healthy member as the sync source. Triggering this type of resync is sufficient to remediate both index inconsistencies and replication inconsistencies5 as long as there is at least one known, healthy copy of data in a cluster.
While it is typically the case that it is straightforward to identify a healthy sync source when repairing corruption–truly random failures would be unlikely to happen on more than one copy of data–there are some additional considerations we have to make when identifying a sync source. A given node in an Atlas cluster may have already had its data resynced at some point in the past in the course of ordinary operations. For example, if the cluster was migrated to a new set of hardware in the past, some or all nodes in the cluster may have already been rebuilt at least once before. For this reason, it is important for us to consider the history of changes in the cluster in the time after corruption may have been introduced to rule out any nodes that may have copied corrupt data, and to separately validate the integrity of the sync source before performing any repair.
Once we are confident in a remediation plan and have coordinated any necessary details with our customers, we leverage internal features for performing automated resyncs on Atlas clusters to rebuild corrupt data. Very often, these repairs can be done with little interruption to a database’s operations. Known healthy nodes can continue to serve application traffic while data is repaired in the background. Internal-facing functionality for repairing Atlas clusters has existed since the early days of the platform, but in recent years we have added additional features and levels of control to facilitate corruption remediation. In particular, in many cases we are able to perform optimized versions of the initial sync process by using cloud provider snapshots of healthy nodes to circumvent the sometimes-lengthy process of copying data directly between replica set members, reducing the overall time it takes to repair a cluster. In the rarer event that we need to perform a full logical initial sync of data, we can continue to perform this mode of data synchronization as well. After repair has completed, we finish by performing follow-up scanning to validate that the repair succeeded.
We are still hard at work refining our systems for detecting and remediating data corruption. At the moment, much of our focus is on making our scanning processes as performant and thorough as possible and continuing to reduce the time it takes to identify new instances of corruption when they occur. With these systems in place it is our intention to make silent data corruption yet another detail of hardware management that the customers of Atlas don’t need to lose any sleep over, no matter what kinds of rare failures may occur.
Join our MongoDB Community to learn about upcoming events, hear stories from MongoDB users, and connect with community members from around the world.
Acknowledgments
The systems described here are the work of dozens of engineers across several teams at MongoDB. Significant developments in these areas in recent years were led by Nathan Blinn, Xuerui Fa, Nan Gao, Rob George, Chris Kelly, and Eric Sedor-George. A special thanks to Eric Sedor-George for invaluable input throughout the process of writing this post.
1 Instances of alpha radiation, often in the form of cosmic rays, introducing silent data corruption have been explored in many studies since the 1970s. For a recent overview of literature on this topic, see Reghenzani, Federico, Zhishan Guo, and William Fornaciari. “Software fault tolerance in real-time systems: Identifying the future research questions.” ACM Computing Surveys 55.14s (2023): 1-30.
2 Five instances of silent data corruption introducing inaccurate results in scientific research were identified in a review of computing systems at Los Alamos National Laboratory in S. E. Michalak, et al , “Correctness Field Testing of Production and Decommissioned High Performance Computing Platforms at Los Alamos National Laboratory,” SC ’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2014
3A recent survey of the CPU population of Alibaba Cloud identified a corruption rate of 3.61 per 10,000 CPUs, see Wang, Shaobu, et al. “Understanding Silent Data Corruptions in a Large Production CPU Population.” Proceedings of the 29th Symposium on Operating Systems Principles. 2023. Research by Google on its own datacenters identified CPU corruption on “the order of a few mercurial cores per several thousand machines,†see Hochschild, Peter H., et al. “Cores that don’t count.” Proceedings of the Workshop on Hot Topics in Operating Systems. 2021. Research by Meta on its own datacenters found that “hundreds of CPUs†demonstrated silent data corruption across “hundreds of thousands of machines,†see Dixit, Harish Dattatraya, et al. “Silent data corruptions at scale.” arXiv preprint arXiv:2102.11245 (2021).
4 In practice, it is rare that corrupt data results in a legible value; more often data in this state would be simply illegible.
5 There are other methods of rebuilding indexes in a MongoDB database beyond what is described here; see db.collection.reIndex for information on rebuilding indexes without triggering an initial sync.
Source: Read More