




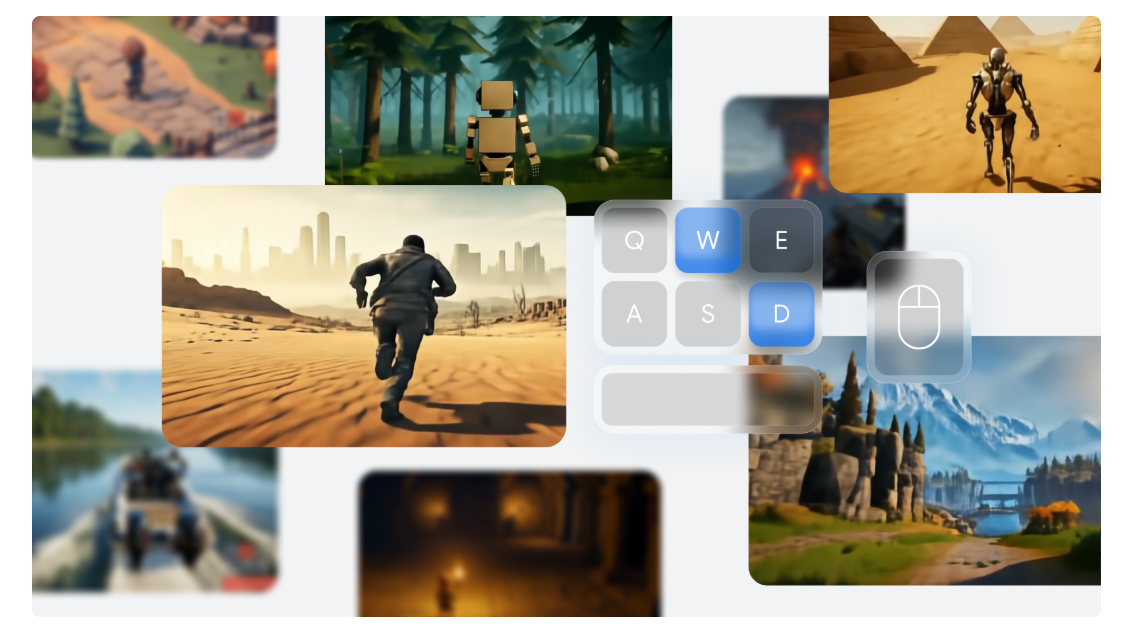
Google DeepMind has introduced Genie 2, a multimodal AI model designed to reduce the gap between creativity and AI. Genie 2 is poised to redefine the future of interactive content creation, particularly in video game development and virtual worlds. Building upon the foundation of its predecessor, the original Genie, this new iteration demonstrates advancements, including its ability to generate complex, fully playable virtual environments from simple input. Genie 2 can transform these inputs into dynamic, immersive video game landscapes, whether written descriptions, images, or hand-drawn sketches.
Using its intuitive system, Google Genie 2 allows users to craft detailed, interactive virtual environments. No longer limited to those with programming skills, anyone can craft detailed, interactive virtual environments using Genie 2’s intuitive system. The AI tool analyzes vast datasets, including video content, to learn how players interact with their environment. This allows it to generate virtual spaces where users can actively participate and explore. What sets Genie 2 apart is its ability to autonomously interpret and transform input into fully functioning gameplay elements without the need for explicit instructions.
Spatiotemporal (ST) transformers are a unique form of transformer model that allows Genie 2 to process video content effectively. Unlike traditional transformers optimized for processing text, ST transformers can analyze video frames’ spatial and temporal components. This enables Genie 2 to predict what actions might happen in a video sequence, which is critical for generating the next playable frame in a video game. Essentially, the AI learns the underlying patterns in video content and how objects interact as time progresses, allowing it to simulate realistic, evolving virtual worlds. Through this sophisticated method, it can understand not only the individual frames of a video but also the transitions between them, enabling more fluid, lifelike virtual environments.
Google Genie 2 can learn latent actions from video content. This feature enables the AI to predict player actions in a game or virtual world without explicit instructions.Â
For example, If a user provides a simple image or description of a space, Genie 2 can infer the most likely actions a player would take in that environment, such as walking, jumping, or interacting with objects.
This capability allows users to create personalized virtual spaces that respond naturally to player input. This feature is impressive because it mimics modern video games’ dynamic, interactive behavior, where the environment reacts to player choices and actions in real-time.
Another great feature of Genie 2 is its ability to create entirely new gameplay experiences based on relatively minimal input. This is accomplished through its training on a massive dataset of internet videos, particularly those showcasing gameplay. This training allows Genie 2 to learn gaming environments’ basic rules and dynamics. It then uses this knowledge to predict the appropriate responses to user inputs, generating complex, dynamic worlds without an extensive rulebook. This learning process from video content is integral to its success, as it empowers Genie 2 to be adaptable and capable of handling an infinite variety of virtual scenarios.
The core of Genie 2’s operation is using a video tokenizer, which reduces the complexity of video frames into smaller, more manageable chunks. These chunks, tokens, are easier for the AI to process and manipulate. Using these tokens, Genie 2 predicts the next frame of a video sequence by evaluating the actions within the video, effectively continuing the story or gameplay sequence. This ability to generate the next frame of a video on the fly is essential for creating immersive, playable environments, as it allows users to build games that evolve naturally over time.
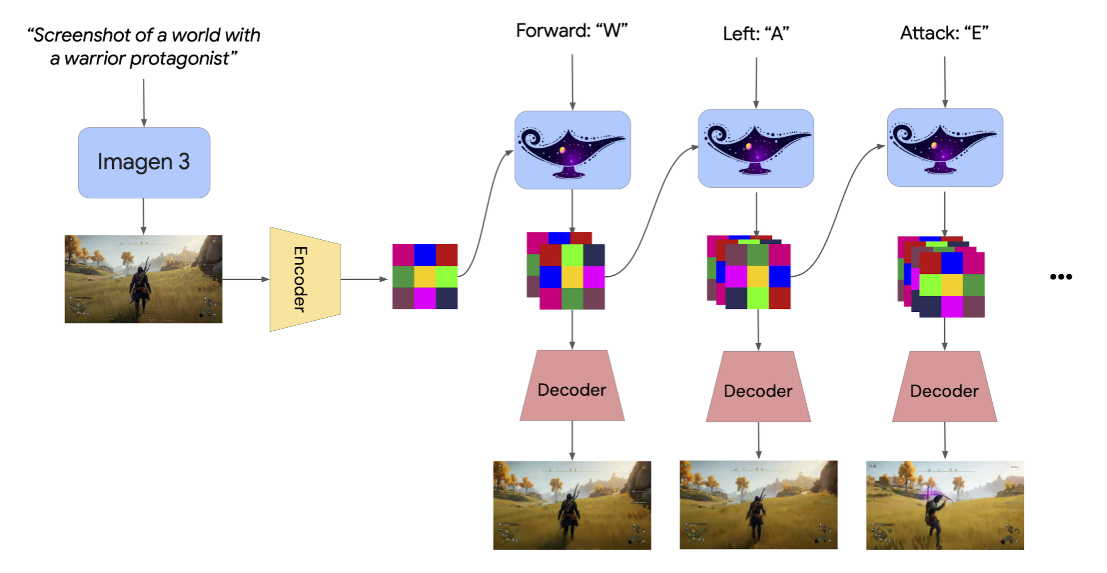
Also, Genie 2 uses a dynamics model that plays a great role in maintaining the continuity and coherence of the generated video. The dynamics model uses the video tokens and inferred actions to generate the next frame, ensuring that the virtual world remains consistent and logical. This model helps predict what happens next in a game or virtual space based on the player’s actions and choices. This prediction capability makes the virtual worlds feel more responsive and interactive as the AI adapts to the player’s real-time decisions.
The system also includes a latent action model (LAM), which helps Genie 2 understand what happens between video frames. The LAM analyzes video sequences to infer the unspoken actions, such as a character moving or interacting with objects. This feature is important in video generation because it allows the AI to create more accurate and dynamic interactions between objects and characters within a virtual world.
In conclusion, Google Genie 2’s innovative approach to game and world creation is a game-changer for the industry. It enables users to create complex virtual environments with minimal effort and technical expertise, opening up new possibilities for professionals and amateurs. Game developers, for instance, can use Genie 2 to quickly prototype new worlds and gameplay experiences, saving valuable time and resources. At the same time, hobbyists and aspiring creators can explore their ideas without needing advanced programming skills.
Check out the Details here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Google DeepMind Introduces Genie 2: An Autoregressive Latent Diffusion Model for Virtual World and Game Creation with Minimal Input appeared first on MarkTechPost.
Source: Read MoreÂ