


This post is co-written with Adarsh Kyadige and Salma Taoufiq from Sophos.Â
As a leader in cutting-edge cybersecurity, Sophos is dedicated to safeguarding over 500,000 organizations and millions of customers across more than 150 countries. By harnessing the power of threat intelligence, machine learning (ML), and artificial intelligence (AI), Sophos delivers a comprehensive range of advanced products and services. These solutions are designed to protect and defend users, networks, and endpoints against a wide array of cyber threats including phishing, ransomware, and malware. The Sophos Artificial Intelligence (AI) group (SophosAI) oversees the development and maintenance of Sophos’s major ML security technology.
Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation across diverse domains as showcased in numerous leaderboards (e.g., HELM, Hugging Face Open LLM leaderboard) that evaluate them on a myriad of generic tasks. However, their effectiveness in specialized fields like cybersecurity relies heavily on domain-specific knowledge. In this context, fine-tuning emerges as a crucial technique to adapt these general-purpose models to the intricacies of cybersecurity. For example, we could use Instruction fine-tuning to increase the model performance on an incident classification or summarization. However, before fine-tuning, it’s important to determine an out-of-the-box model’s potential by testing its abilities on a set of tasks based on the domain. We have defined three specialized tasks that are covered later in the blog. These same tasks can also be used to measure the gains in performance obtained through fine-tuning, Retrieval-Augmented Generation (RAG), or knowledge distillation.
In this post, SophosAI shares insights in using and evaluating an out-of-the-box LLM for the enhancement of a security operations center’s (SOC) productivity using Amazon Bedrock and Amazon SageMaker. We use Anthropic’s Claude 3 Sonnet on Amazon Bedrock to illustrate the use cases.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Tasks
We will showcase three example tasks to delve into using LLMs in the context of an SOC. An SOC is an organizational unit responsible for monitoring, detecting, analyzing, and responding to cybersecurity threats and incidents. It employs a combination of technology, processes, and skilled personnel to maintain the confidentiality, integrity, and availability of information systems and data. SOC analysts continuously monitor security events, investigate potential threats, and take appropriate action to mitigate risks. Known challenges faced by SOCs are the high volume of alerts generated by detection tools and the subsequent alert fatigue among analysts. These challenges are often coupled with staffing shortages. To address these challenges and enhance operational efficiency and scalability, many SOCs are increasingly turning to automation technologies to streamline repetitive tasks, prioritize alerts, and accelerate incident response. Considering the nature of tasks analysts need to perform, LLMs are good tools to enhance the level of automation in SOCs and empower security teams.
For this work, we focus on three essential SOC use cases where LLMs have the potential of greatly assisting analysts, namely:
- SQL Query generation from natural language to simplify data extraction
- Incident severity prediction to prioritize which incidents analysts should focus on
- Incident summarization based on its constituent alert data to increase analyst productivity
Based on the token consumption of these tasks, particularly the summarization component, we need a model with a context window of at least 4000 tokens. While the tasks have been tested in English, Anthropic’s Claude 3 Sonnet model can perform in other languages. However, we recommend evaluating the performance in your specific language of interest.
Let’s dive into the details of each task.
Task 1: Query generation from natural language
This task’s objective is to assess a model’s capacity to translate natural language questions into SQL queries, using contextual knowledge of the underlying data schema. This skill simplifies the data extraction process, allowing security analysts to conduct investigations more efficiently without requiring deep technical knowledge. We used prompt engineering guidelines to tailor our prompts to generate better responses from the LLM.
A three-shot prompting strategy is used for this task. Given a database schema, the model is provided with three examples pairing a natural-language question with its corresponding SQL query. Following these examples, the model is then prompted to generate the SQL query for a question of interest.
The prompt below is a three-shot prompt example for query generation from natural language. Empirically, we have obtained better results with few-shot prompting as opposed to one-shot (where the model is provided with only one example question and corresponding query before the actual question of interest) or zero-shot (where the model is directly prompted to generate a desired query without any examples).
To evaluate a model’s performance on this task, we rely on a proprietary data set of about 100 target queries based on a test database schema. To determine the accuracy of the queries generated by the model, a multi-step evaluation is followed. First, we verify whether the model’s output is an exact match to the expected SQL statement. Exact matches are then recorded as successful outcomes. If there is a mismatch, we then run both the model’s query and the expected query against our mock database to compare their results. However, this method can be prone to false positives and false negatives. To mitigate this, we further perform a query equivalence assessment using a different stronger LLM on this task. This method is known as LLM-as-a-judge.
Anthropic’s Claude 3 Sonnet model achieved a good accuracy rate of 88 percent on the chosen dataset, suggesting that this natural-language-to-SQL task is quite simple for LLMs. With basic few-shot prompting, an LLM can therefore be used out-of-the-box without fine-tuning by security analysts to assist them in retrieving key information while investigating threats. The above model performance is based on our dataset and our experiment. This means that you can perform your own test using the strategy explained above.
Task 2: Incident severity prediction
For the second task, we assess a model’s ability to recognize the severity of observed events as indicators of an incident. Specifically, we try to determine whether an LLM can review a security incident and accurately gauge its importance. Armed with such a capability, a model can assist analysts in determining which incidents are most pressing, so they can work more efficiently by organizing their work queue based on severity levels, cut through the noise, and save time and energy.
The input data in this use case is semi-structured alert data, typical of what is produced by various detection systems during an incident. We clearly define severity categories—critical, high, medium, low, and informational—across which the model is to classify the severity of the incident. This is therefore a classification problem that tests an LLM’s intrinsic cybersecurity knowledge.
Each security incident within the Sophos Managed Detection and Response (MDR) platform is made up of multiple detections that highlight suspicious activities occurring in a user’s environment. A detection might involve identifying potentially harmful patterns, such as unusual command executions, abnormal file access, anomalous network traffic, or suspicious script use. We have attached below an example input data.
The “detection†section provides detailed information about each specific suspicious activity that was identified. It includes the type of security incident, such as “Execution,†along with a description that explains the nature of the threat, like the use of suspicious PowerShell commands. The detection is tied to a unique identifier for tracking and reference purposes. Additionally, it contains details from the MITRE ATT&CK framework which categorizes the tactics and techniques involved in the threat. This section might also reference related Sigma rules, which are community-driven signatures for detecting threats across different systems. By including these elements, the detection section serves as a comprehensive outline of the potential threat, helping analysts understand not just what was detected but also why it matters.
The “machine_data†section holds crucial information about the machine on which the detection occurred. It can provide further metadata on the machine, helping to pinpoint where exactly in the environment the suspicious activity was observed.
To facilitate evaluation, the prompt used for this task requires that the model communicates its severity assessments in a uniform way, providing the response in a standardized format, for example, as a dictionary with severity_pred as the key and their chosen severity level as the value. The prompt below is an example for incident severity classification. Model performance is then evaluated against a test set of over 3,800 security incidents with target severity levels.
Various experimental setups are used for this task, including zero-shot prompting, three-shot prompting using random or nearest-neighbor incidents examples, and simple classifiers.
This task turned out to be quite challenging, because of the noise in the target labels and the inherent difficulty of assessing the criticality of an incident without further investigation by models that weren’t trained specifically for this use case.
Even under various setups, such as few-shot prompting with nearest neighbor incidents, the model’s performance couldn’t reliably outperform random chance. For reference, the baseline accuracy on the test set is approximately 71 percent and the baseline balanced accuracy is 20 percent.
Figure 1 presents the confusion matrix of the model’s responses. The confusion matrix allows to see in one graph the performance of the model’s classification. We can see that only 12% (0.12) of the Actual critical incidents have been correctly predicted/classified. Then 50% of the Critical incidents have been predicted as High incidents, 25% as Medium incidents and 12% as Informational incidents. We can similarly see low accuracy on the rest of the labels and the lowest being bee the Low incidents label with only 2% of the incidents correctly predicted. There is also a notable tendency to overpredict High and Medium categories across the board.
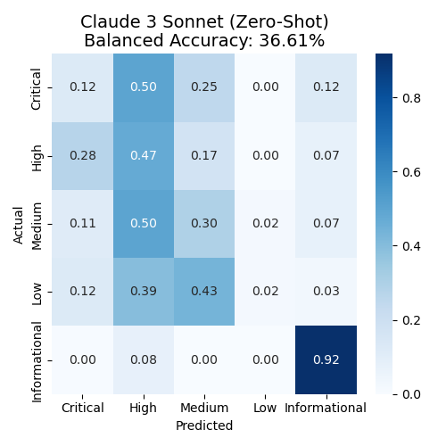
Figure 1: Confusion matrix for the five-severity-level classification using Anthropic Claude 3 Sonnet
The performance observed in this benchmark task indicates this is a particularly hard problem for an unmodified, all-purpose LLM, and the problem requires a more specialized model, specifically trained or fine-tuned on cybersecurity data.
Task 3: Incident summarization
The third task is concerned with the summarization of incoming incidents. It evaluates the potential of a model to assist threat analysts in the triage and investigation of security incidents as they come in by providing a succinct and concise summary of the activity that triggered the incident.
Security incidents typically consist of a series of events occurring on a user endpoint or network, associated with detected suspicious activity. The analysts investigating the incident are presented with a series of events that occurred on the endpoint at the time the suspicious activity was detected. However, analyzing this event sequence can be challenging and time-consuming, resulting in difficulty in identifying noteworthy events. This is where LLMs can be beneficial by helping organize and categorize event data following a specific template, thereby aiding comprehension, and helping analysts quickly determine the appropriate next actions.
We use real incident data from Sophos’s MDR for incident summarization. The input for this task encompasses a set of JSON events, each having distinct schemas and attributes based on the capturing sensor. Along with instructions and a predefined template, this data is provided to the model to generate a summary. The prompt below is an example template prompt for generating incident summaries from SOC data.
Evaluating these generated incident summaries is tricky because several factors must be considered. For example, it’s crucial that the extracted information is not only correct, but also relevant. To gain a general understanding of the quality of a model’s incident summarization, we use a set of five distinct metrics and rely on a dataset comprising of N incidents. We compare the generated descriptions with corresponding gold-standard descriptions crafted based on Sophos analysts’ feedback.
We compute two classes of metrics. The first class of metrics assesses factual accuracy; they are used to evaluate how many artifacts such as command lines, file paths, usernames, and so on were correctly identified and summarized by the model. The computation here is straightforward; we compute the average distance across extracted artifacts between the generated description and the target. We use two distance metrics, Levenshtein distance and longest common subsequence (LCS).
The second class of metrics is used to provide a more semantic evaluation of the generated description, using three different metrics:
- BERTScore metric: This metric is used to evaluate the generated summaries using a pre-trained BERT model’s contextual embeddings. It determines the similarity between the generated summary and the reference summary using cosine similarity.
- ADA2 embeddings cosine similarity: This metric assesses the cosine similarity of ADA2 embeddings of tokens in the generated summary with those of the reference summary.
- METEOR score: METEOR is an evaluation metric based on the harmonic mean of unigram precision and recall.
More advanced evaluation methods can be used such as training a reward model on human preferences and using it as an evaluator, but for the sake of simplicity and cost-effectiveness, we limited the scope to these metrics.
Below is a summary of our results on this task:
| Model | Levenshtein-based factual accuracy | LCS-based factual accuracy | BERTScore | Cosine similarity of ADA2 embeddings | METEOR score |
| Anthropic’s Claude 3 Sonnet | 0.810 | 0.721 | 0.886 | 0.951 | 0.4165 |
Based on these findings, we gain a broad understanding of the performance of the model when it comes to generating incident summaries, focusing especially on factual accuracy and retrieval rate. Anthropic’s Claude 3 Sonnet model can capture the activity that’s occurring in the incident and summarize it well. However, it ignores certain instructions such as defanging all IPs and URLs. The returned reports are also not fully aligned with the target responses on a token level as signaled by the METEOR score. Anthropic’s Claude 3 Sonnet model skims over some details and explanations in the reports.
Experimental setup using Amazon Bedrock and Amazon SageMaker
This section outlines the experimental setup for evaluating various large language models (LLMs) using Amazon Bedrock and Amazon SageMaker. These services allowed us to efficiently interact with and deploy multiple LLMs for quick and cost-effective experimentation.
Amazon Bedrock
Amazon Bedrock is a managed service that allows experimenting with various LLMs quickly in an on-demand manner. This brings the advantage of being able to interact and experiment with LLMs without having to self-host them and only pay by tokens consumed. We used the InvokeModel API to interact with the model with minimal latency. We wrote the following function that let us call different models by passing the necessary inference parameters to the API. For more details on what the inference parameters are per provider, we recommend you read the Inference request parameters and response fields for foundation models section in the Amazon Bedrock documentation. The example below uses the function based on Anthropic’s Claude 3 Sonnet model. Notice that we gave the model a role via the system prompt and that we prefilled its response.
The above example is based on our use case. The model_id parameter specifies the identifier of the specific model you wish to invoke using the Bedrock runtime. We used the model id anthropic.claude-3-sonnet-20240229-v1:0. For other model ids, please refer to the bedrock documentation. For further details about this API, we recommend you read the API documentation. We advise you to adapt it to your use case based on your requirements.
Our analysis in this blog post has focused on Anthropic’s Claude 3 Sonnet model and three specific use cases. These insights can be adapted to other SOCs’ specific requirements and desired models. For example, it’s possible to access other models such as Meta’s Llama models, Mistral models, Amazon Titan models and others. For additional models, we used Amazon SageMaker Jumpstart.
Amazon SageMaker
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and confidently build, train, and deploy ML models into a production-ready hosted environment. Amazon SageMaker JumpStart is a robust feature within the SageMaker machine learning (ML) environment, offering practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs). It offers a wide range of publicly available and proprietary LLMs that you can, in a low-code manner, quickly tune and deploy. To quickly deploy and experiment with the out of the box models in SageMaker in a cost-effective manner, we deployed the LLMs from SageMaker JumpStart using asynchronous inference endpoints.
Inference endpoints were an effortless way for us to directly download these models from the respective Hugging Face repositories and deploy them using a few lines of code and pre-made Text Generation Inference (TGI) containers (see the example notebook on GitHub). In addition, we used asynchronous inference endpoints with autoscaling, which helped us to manage costs by automatically scaling the inference endpoints down to zero when they weren’t being used. Considering the number of endpoints we were creating, asynchronous inference made it simple for us to manage endpoints by having the endpoint ready to use whenever they were needed and scaling them down when they weren’t being used, without additional management on our end after the scaling policy was defined.
Next steps
In this blog post we applied the tasks on a single model to show case it as an example; in reality, you would select a couple of LLMs that you would put through the experiments in this post based on your requirements. From there, if the out-of-the-box models aren’t sufficient for the task, you would select the best suited LLM and then fine-tune it on the specific task.
For example, based on the outcomes of our three experimental tasks, we found that the results of the incident information summarization task didn’t meet our expectations. Therefore, we will fine-tune the out-of-the-box model that best suits our needs. This fine-tuning process can be accomplished using Amazon Bedrock Custom Models or SageMaker fine tuning, and the fine-tuned model could then be deployed using the customized model by importing it into Amazon Bedrock or by deploying the model to a SageMaker endpoint.
In this blog we covered the experimentation phase. Once you identify an LLM that meets your performance requirements, it’s important to start considering how to productionize it. When productionizing an LLM, it is important to consider things like guardrails and scalability of the LLM. Implementing guardrails helps you to minimize the risk of the model being misused or security breaches. Amazon Bedrock Guardrails enables you to implement safeguards for your generative AI applications based on your use cases and responsible AI policies. This blog covers how to build guardrails in your generative AI applications. When moving an LLM into ] production, you also want to validate the scalability of the LLM based on request traffic. In Amazon Bedrock, consider increasing the quotas of your model, batch inference, queuing the requests, or even distributing the requests between different Regions that have the same model. Select the technique that suits you based on your use case and traffic.
Conclusion
In this post, SophosAI shared insights on how to use and evaluate out-of-the-box LLMs following a set of specialized tasks for the enhancement of a security operations center’s (SOC) productivity by using Amazon Bedrock and Amazon SageMaker. We used Anthropic’s Claude 3 Sonnet model on Amazon Bedrock to illustrate three use cases.
Amazon Bedrock and SageMaker have been key to enabling us to run these experiments. With the convenient access to high-performing foundation models (FMs) from leading AI companies provided by Amazon Bedrock through a single API call, we were able to test various LLMs without needing to deploy them ourselves. Additionally, the on-demand pricing model allowed us to only pay for what we used based on token consumption.
To access additional models with flexible control, SageMaker is a great alternative that offers a wide range of LLMs ready for deployment. While you would deploy these models yourself, you can still achieve great cost optimization by using asynchronous endpoints with a scaling policy that scales the instance down to zero when not in use.
General takeaways as to the applicability of an LLM such as Anthropic’s Claude 3 Sonnet model in cybersecurity can be summarized as follows:
- An out-of-the-box LLM can be an effective assistant in threat hunting and incident investigation. However, it still requires some guardrails and guidance. We believe that this potential application can be implemented using an existing powerful model, such as Anthropic’s Claude 3 Sonnet model, with careful prompt engineering.
- When it comes to summarizing incident information from raw data, Anthropic’s Claude 3 Sonnet model performs adequately, but there’s room for improvement through fine-tuning.
- Evaluating individual artifacts or groups of artifacts remains a challenging task for a pre-trained LLM. To tackle this problem, a specialized LLM trained specifically on cybersecurity data might be required.
It is also worth noticing that while we used the InvokeModel API from Amazon Bedrock, another simpler way to access Amazon Bedrock models is by using the Converse API. The Converse API provides consistent API calls that work with Amazon Bedrock models that support messages. This means you can write code once and use it with different models. Should a model have unique inference parameters, the Converse API also allows you to pass those unique parameters in a model specific structure.
About the Authors
 Benoit de Patoul is a GenAI/AI/ML Specialist Solutions Architect at AWS. He helps customers by providing guidance and technical assistance to build solutions related to GenAI/AI/ML using Amazon Web Services. In his free time, he likes to play piano and spend time with friends.
Benoit de Patoul is a GenAI/AI/ML Specialist Solutions Architect at AWS. He helps customers by providing guidance and technical assistance to build solutions related to GenAI/AI/ML using Amazon Web Services. In his free time, he likes to play piano and spend time with friends.
 Naresh Nagpal is a Solutions Architect at AWS with extensive experience in application development, integration, and technology architecture. At AWS, he works with ISV customers in the UK to help them build and modernize their SaaS applications on AWS. He is also helping customers to integrate GenAI capabilities in their SaaS applications.
Naresh Nagpal is a Solutions Architect at AWS with extensive experience in application development, integration, and technology architecture. At AWS, he works with ISV customers in the UK to help them build and modernize their SaaS applications on AWS. He is also helping customers to integrate GenAI capabilities in their SaaS applications.
 Adarsh Kyadige oversees the Research wing of the Sophos AI team, where he has been working since 2018 at the intersection of Machine Learning and Security. He earned a Masters degree in Computer Science, with a specialization in Artificial Intelligence and Machine Learning, from UC San Diego. His interests and responsibilities involve applying Deep Learning to Cybersecurity, as well as orchestrating pipelines for large scale data processing. In his leisure time, Adarsh can be found at the archery range, tennis courts, or in nature. His latest research can be found on Google Scholar.
Adarsh Kyadige oversees the Research wing of the Sophos AI team, where he has been working since 2018 at the intersection of Machine Learning and Security. He earned a Masters degree in Computer Science, with a specialization in Artificial Intelligence and Machine Learning, from UC San Diego. His interests and responsibilities involve applying Deep Learning to Cybersecurity, as well as orchestrating pipelines for large scale data processing. In his leisure time, Adarsh can be found at the archery range, tennis courts, or in nature. His latest research can be found on Google Scholar.
 Salma Taoufiq was a Senior Data Scientist at Sophos focusing at the intersection of machine learning and cybersecurity. With an undergraduate background in computer science, she graduated from the Central European University with a MSc. in Mathematics and Its Applications. When not developing a malware detector, Salma is an avid hiker, traveler, and consumer of thrillers.
Salma Taoufiq was a Senior Data Scientist at Sophos focusing at the intersection of machine learning and cybersecurity. With an undergraduate background in computer science, she graduated from the Central European University with a MSc. in Mathematics and Its Applications. When not developing a malware detector, Salma is an avid hiker, traveler, and consumer of thrillers.
Source: Read MoreÂ