




Logic synthesis is one of the important steps in designing digital circuits, in which high-level descriptions are turned into detailed gate-level designs. The development of ML algorithms is transforming fields such as autonomous driving, robotics, and natural language processing. Various Machine learning approaches have been used to integrate domains. These ML methods have improved logic synthesis, including logic optimization, technology mapping, and formal verification. They have shown great potential to improve the efficiency and quality of the logic synthesis steps, making them faster and better. However, more reliable datasets are needed to continue improving these methods.
The traditional benchmarks have played a major role in developing EDA tools and methodologies by providing a foundation for testing, comparison, and enhancement. Datasets like OpenABC-D have been created for logic synthesis from these benchmarks. However, these datasets are designed for specific tasks and limit their use in different machine-learning applications. It fails to preserve the original information in intermediate files, which makes it difficult to adapt and refine datasets for new challenges.
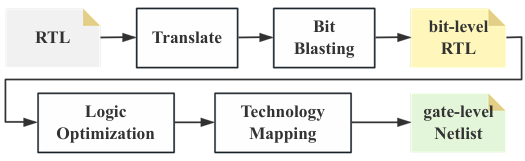
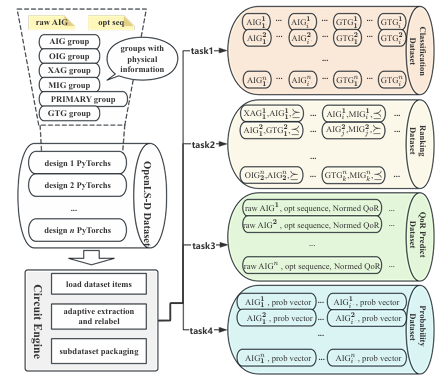
To overcome these drawbacks, a group of researchers from China conducted detailed research. They proposed OpenLS-DGF, an adaptive logic synthesis dataset generation framework designed to support various machine learning tasks within logic synthesis. The proposed framework covers the three fundamental stages of logic synthesis: Boolean representation, Logic optimization, and Technology mapping. The comprehensive workflow includes seven steps, including the raw file generation and the dataset packing. The framework involves seven steps, from the initial design input to the final dataset packaging. The first three steps include preprocessing the input design to generate the generic technology circuit and its optimized AIGs. The further steps produce intermediate Boolean circuits derived from these optimized AIGs, including logic blasting, technology mapping, and physical design. The final step packages these Boolean circuits into PyTorch format data using a circuit engine, facilitating efficient dataset management.
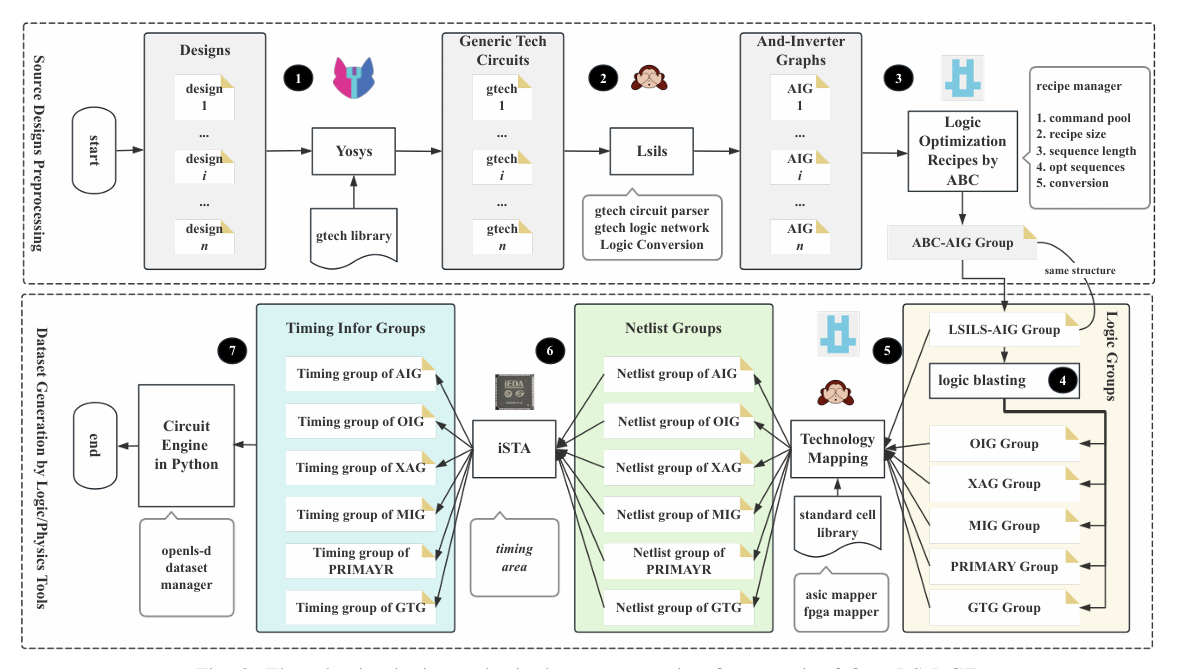
The dataset generation process creates optimized circuit designs through connected steps. Input designs are standardized into GTG and then transformed into AIG for optimization. Multiple circuit variations are generated in six formats, mapped for ASIC/FPGA designs, and analyzed for performance. Outputs are organized into PyTorch files for easy use and validation, ensuring flexibility and efficiency. The Circuit Engine processes raw files into a dataset using the “Circuit†class, which defines nodes with attributes like type, name, and connections. It includes tools for simulation and compatibility with ML frameworks like “torch geometry.†Files that are stored in Verilog and GraphML formats are loaded via NetworkX, and structured graphs are created.Â
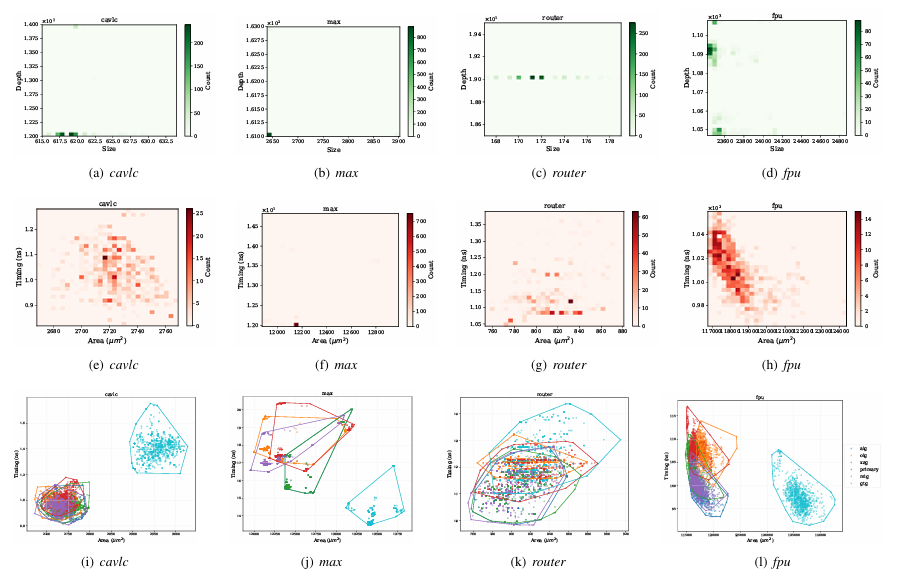
The OpenLS-D-v1 dataset is designed using a variety of benchmark designs like IWLS and OpenCores, containing diverse combinational circuits. It features Boolean networks with wide primary inputs and outputs, and the circuits include arithmetic, control, and IP cores. Graph embeddings combine heuristic and Graph2Vec features for analysis. The dataset comprises 966,000 circuits, categorized into 46 designs with different Boolean network types and netlists for ASIC and FPGA applications. Compared to OpenABC-D, OpenLS-D-v1 offers more diversity, ensuring better representation for machine learning tasks.Â
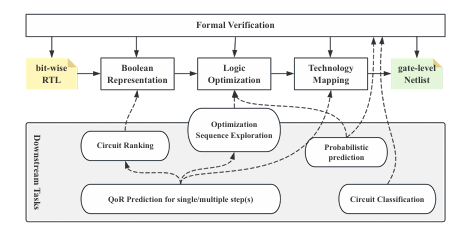
The experiments used ten designs from the OpenLS-D-v1 dataset, including ctrl, router, and int2float, extracting approximately 120,000 pairs for pair-wise ranking. The training covered 70% of the data with an input feature size of 64, a hidden feature size of 128, a learning rate of 0.0001, a decay rate of 1e-5, and a batch size of 32, achieving high prediction accuracy. For QoR prediction across three variants (unseen recipes, designs, and design-recipe combinations), the Mean Absolute Percentage Error (MAPE) reached 4.31% for GraphSAGE, 4.43% for GINConv, and 5.09% for GCNConv, with area prediction outperforming timing prediction. In probabilistic prediction, the node embedding methods like DeepGate reduced average prediction errors by up to 75% and computation time by 56.89× compared to GraphSAGE, demonstrating strong performance and scalability in circuit optimization and prediction tasks.
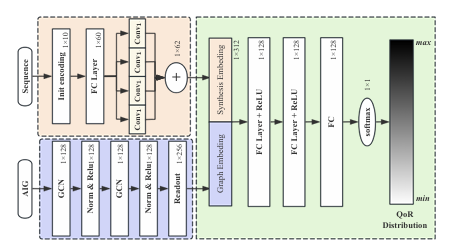
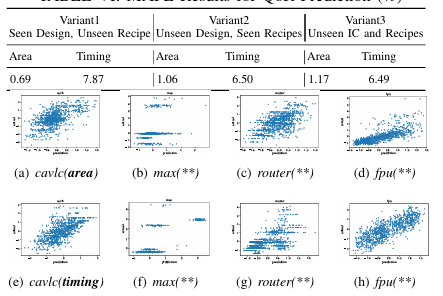
In conclusion, OpenLS-DGF supports various machine learning tasks and highlights its potential as a general resource and standardized process in logic synthesis. The OpenLS-D-v1dataset further enhances this by providing a viable foundation for future research and innovation. The OpenLS-DGF demonstrated its utility by implementing and evaluating four typical tasks on OpenLS-D-v1. The results of these tasks validate the effectiveness and versatility of the framework. In future times, the efficiency of the generation flow can be enhanced, and the specific machine-learning tasks for logic synthesis can be benchmarked!
Check out the Paper and GitHub Page here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post OpenLS-DGF: An Adaptive Open-Source Dataset Generation Framework for Machine Learning Tasks in Logic Synthesis appeared first on MarkTechPost.
Source: Read MoreÂ