




By processing complex data formats, deep learning has transformed various domains, including finance, healthcare, and e-commerce. However, applying deep learning models to tabular data, characterized by rows and columns, poses unique challenges. While deep learning has excelled in image and text analysis, classic machine learning techniques such as gradient-boosted decision trees still dominate tabular data due to their reliability and interpretability. Researchers are exploring new architectures that can effectively adapt deep learning techniques for tabular data without sacrificing accuracy or efficiency.
One significant challenge in applying deep learning to tabular data is balancing model complexity and computational efficiency. Traditional machine learning methods, particularly gradient-boosted decision trees, deliver consistent performance across diverse datasets. In contrast, deep learning models suffer from overfitting and require extensive computational resources, making them less practical for many real-world datasets. Furthermore, tabular data exhibits varied structures and distributions, making it challenging for deep learning models to generalize well. Thus, the need arises for a model that achieves high accuracy and remains efficient across diverse datasets.
Current methods for tabular data in deep learning include multilayer perceptrons (MLPs), transformers, and retrieval-based models. While MLPs are simple and computationally light, they often fail to capture complex interactions within tabular data. More advanced architectures like transformers and retrieval-based methods introduce mechanisms such as attention layers to enhance feature interaction. However, these approaches often require significant computational resources, making them impractical for large datasets and limiting their widespread application. This gap in deep learning for tabular data led to exploring alternative, more efficient architectures.
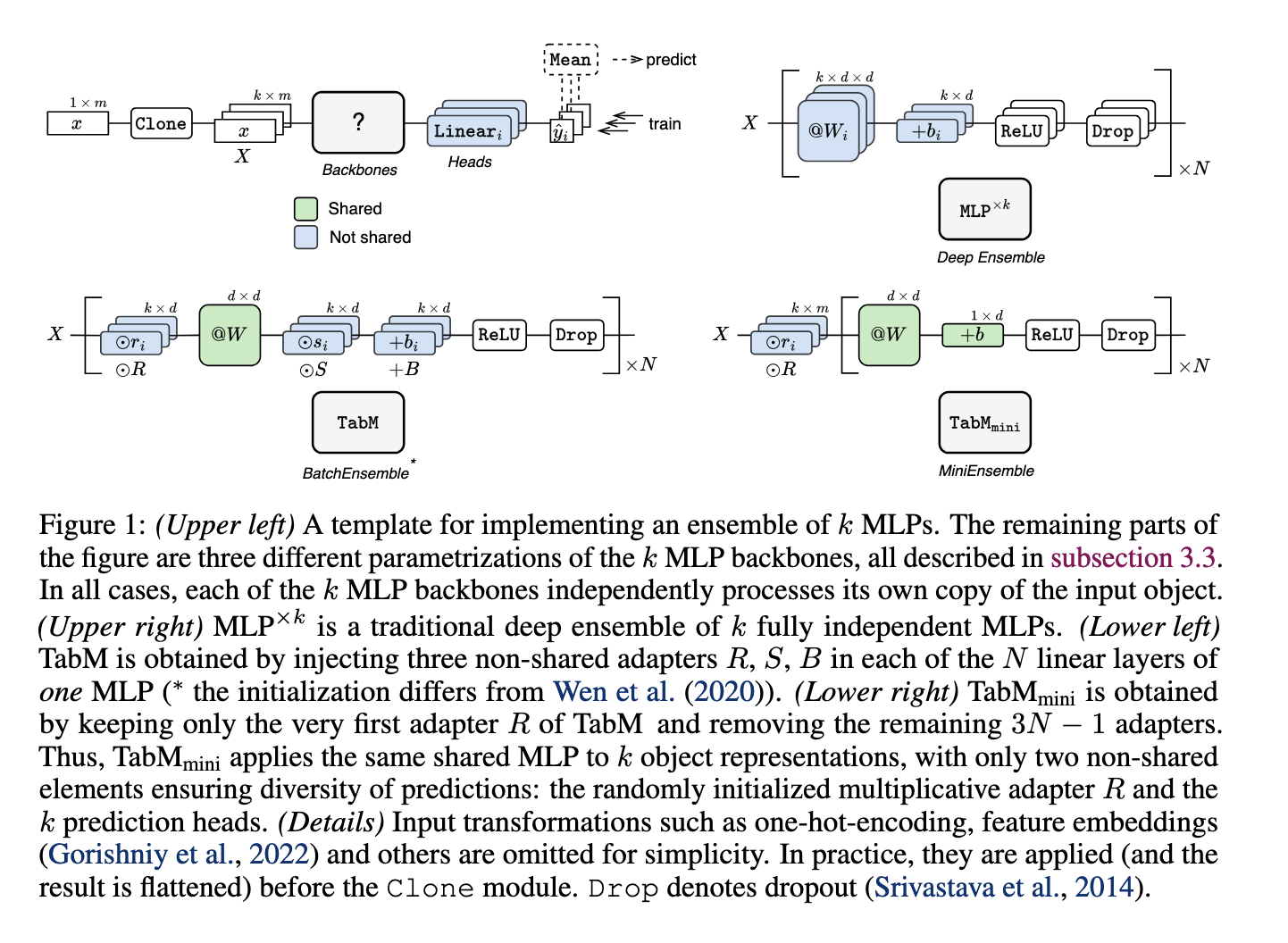
Researchers from Yandex and HSE University introduced a model named TabM, built upon an MLP foundation but enhanced with BatchEnsemble for parameter-efficient ensembling. This model generates multiple predictions within a single structure by sharing most of its weights among ensemble members, allowing it to produce diverse, weakly correlated predictions. By combining simplicity with effective ensembling, TabM balances efficiency and performance, aiming to outperform traditional MLP models without the complexity of transformer architectures. TabM offers a practical solution, providing advantages for deep learning without the excessive resource demands typically associated with advanced models.
The methodology behind TabM leverages BatchEnsemble to maximize prediction diversity and accuracy while maintaining computational efficiency. Each ensemble member uses unique weights, known as adapters, to create a range of predictions. TabM generates robust outputs by averaging these predictions, mitigating overfitting, and improving generalization across diverse datasets. The researchers’ approach combines MLP simplicity with efficient ensembling, creating a balanced model architecture that enhances predictive accuracy and is less prone to common tabular data pitfalls. TabM’s efficient design allows it to achieve high accuracy on complex datasets without the heavy computational demands of transformer-based methods.
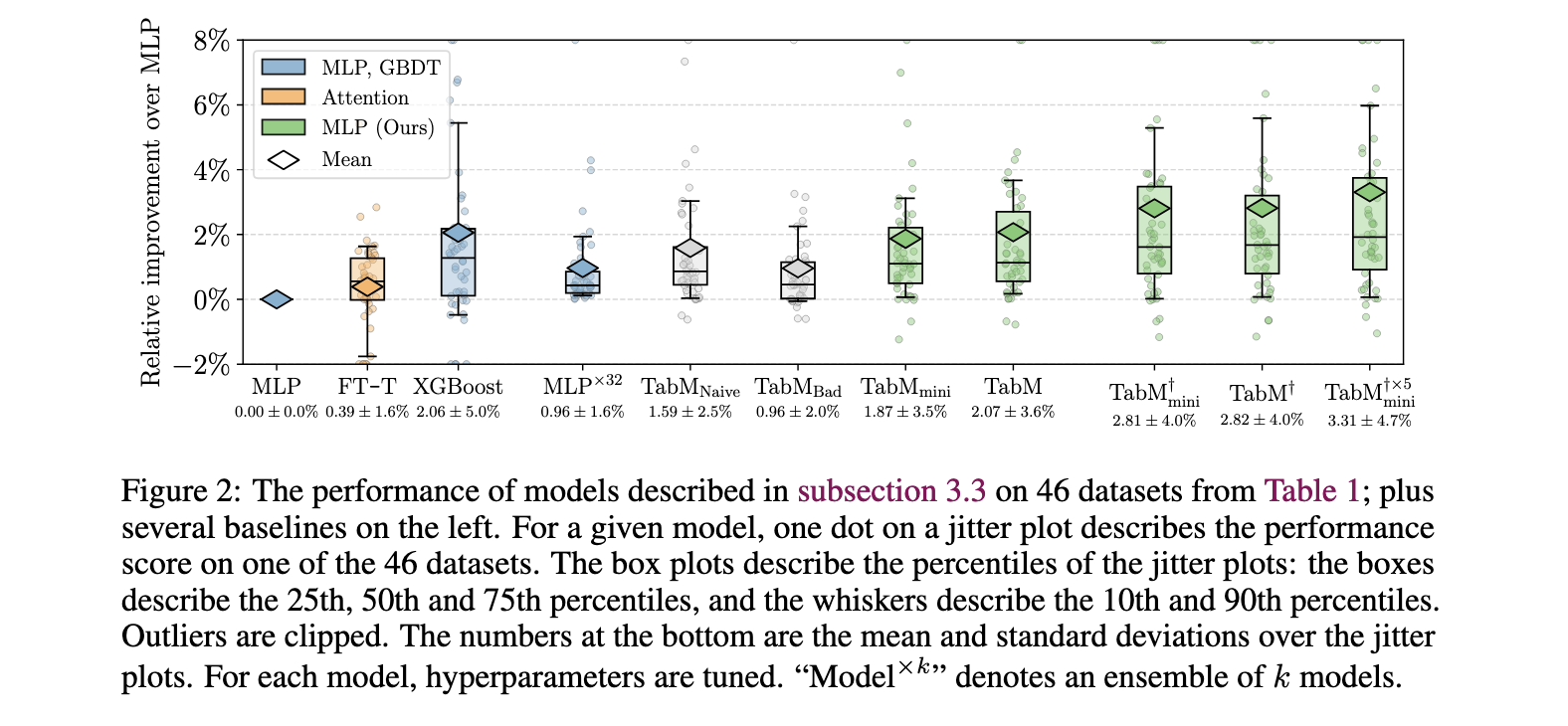
Empirical evaluations demonstrate TabM’s strong performance across 46 public datasets, showing an average improvement of approximately 2.07% over standard MLP models. Specifically, on domain-aware splits—representing more complex, real-world scenarios—TabM outperformed many other deep learning models, proving its robustness. TabM showcased efficient processing capabilities on large datasets, managing datasets with up to 6.5 million objects on the Maps Routing dataset within 15 minutes. For classification tasks, TabM utilized the ROC-AUC metric, achieving consistent accuracy. At the same time, Root Mean Squared Error (RMSE) was employed for regression tasks, demonstrating the model’s capacity to generalize effectively across various task types.
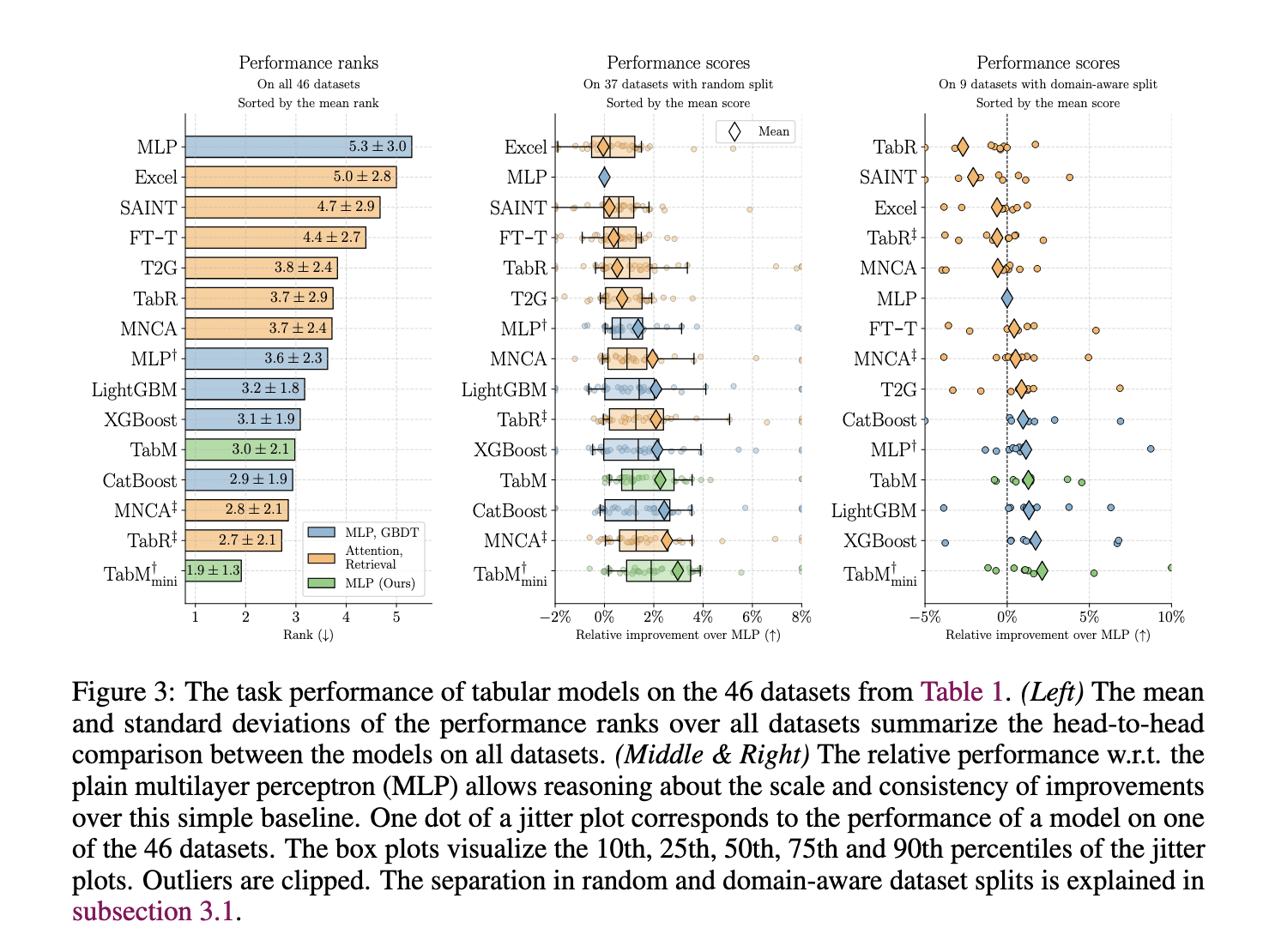
The study presents a significant advancement in applying deep learning to tabular data, merging MLP efficiency with an innovative ensembling strategy that optimizes computational demands and accuracy. By addressing the limitations of previous models, TabM provides an accessible and reliable solution that meets the needs of practitioners handling diverse tabular data types. As an alternative to traditional gradient-boosted decision trees and complex neural architectures, TabM represents a valuable development, offering a streamlined, high-performing model capable of efficiently processing real-world tabular datasets.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post This AI Paper Introduces TabM: An Efficient Ensemble-Based Deep Learning Model for Robust Tabular Data Processing appeared first on MarkTechPost.
Source: Read MoreÂ