




Causal disentanglement is a critical field in machine learning that focuses on isolating latent causal factors from complex datasets, especially in scenarios where direct intervention is not feasible. This capability to deduce causal structures without interventions is particularly valuable across fields like computer vision, social sciences, and life sciences, as it enables researchers to predict how data would behave under various hypothetical scenarios. Causal disentanglement advances machine learning’s interpretability and generalizability, which is crucial for applications requiring robust predictive insights.
The main challenge in causal disentanglement is identifying latent causal factors without relying on interventional data, where researchers manipulate each factor independently to observe its effects. This limitation poses significant constraints in scenarios where interventions could be more practical due to ethical, cost, or logistical barriers. Therefore, a persistent issue remains: how much can researchers learn about causal structures from purely observational data where no direct control over the hidden variables is possible? Traditional causal inference methods struggle in this context, as they often require specific assumptions or constraints that may only apply sometimes.
Existing methods typically depend on interventional data, assuming researchers can manipulate each variable independently to reveal causation. These methods also rely on restrictive assumptions like linear mixing or parametric structures, limiting their applicability to datasets lacking predefined constraints. Some techniques attempt to bypass these limitations by utilizing multi-view data or enforcing additional structural constraints on latent variables. However, these approaches remain limited in observational-only scenarios, as they need to generalize better to cases where interventional or structured data is unavailable.

Researchers from the Broad Institute of MIT and Harvard have introduced a novel approach to address causal disentanglement using only observational data without assuming interventional access or strict structural constraints. Their method uses nonlinear models incorporating additive Gaussian noise and an unknown linear mixing function to identify causal factors. This innovative approach leverages asymmetries within the joint distribution of observed data to derive meaningful causal structures. By focusing on data’s natural distributional asymmetries, this method allows researchers to detect causal relationships up to a layer-wise transformation, marking a significant step forward in causal representation learning without interventions.
The proposed methodology combines score matching with quadratic programming to infer causal structures efficiently. Using estimated score functions from observed data, the approach isolates causal factors through iterative optimization over a quadratic program. This method’s flexibility enables it to integrate various score estimation tools, making it adaptable across different observational datasets. Researchers input score estimations into Algorithms 1 and 2 to capture and refine the causal layers. This framework allows the model to function with any score estimation technique, providing a versatile and scalable solution to complex causal disentanglement problems.
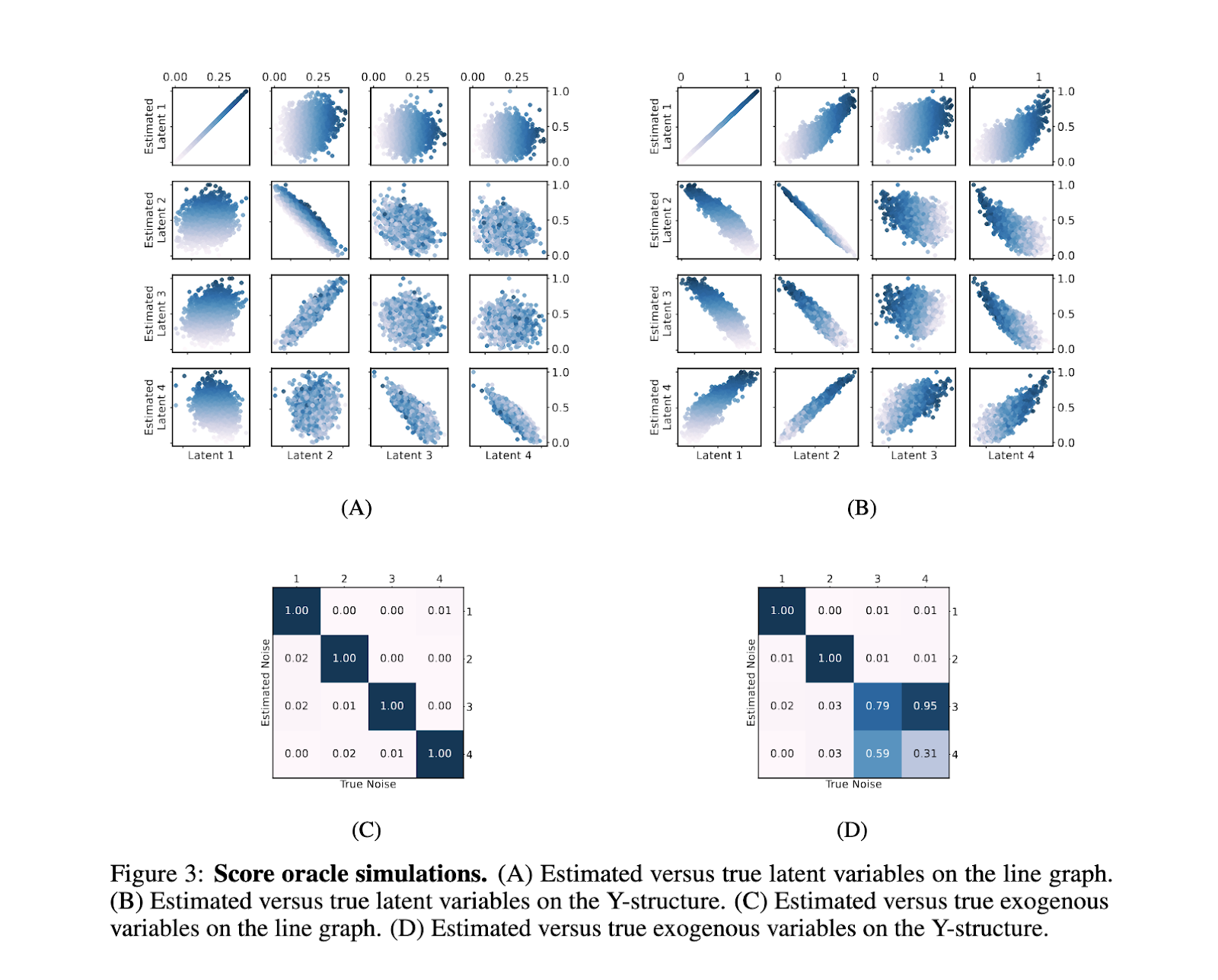
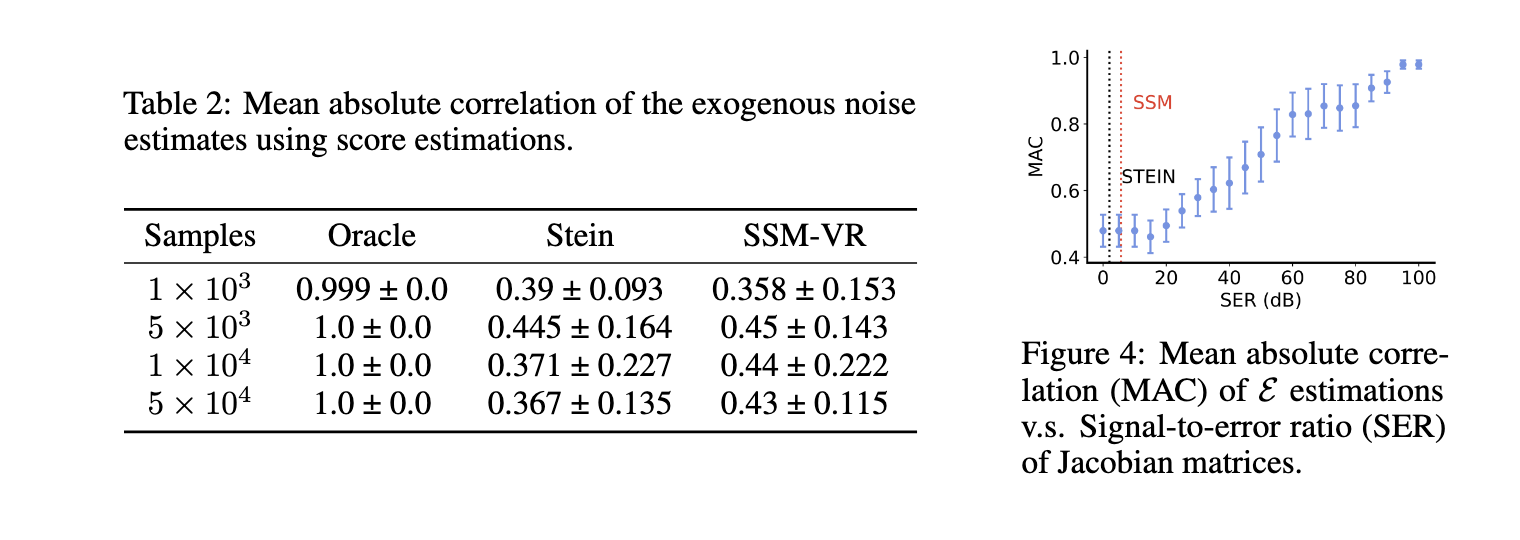
Quantitative evaluation of the method showed promising results, demonstrating its practical effectiveness and reliability. For example, using a four-node causal graph in two configurations— a line graph and a Y-structure—, the researchers generated 2000 observational samples and computed scores with ground-truth link functions. In the line graph, the algorithm achieved perfect disentanglement of all variables, while in the Y-structure, it accurately disentangled variables E1 and E2, though some mixing occurred with E3 and E4. The Mean Absolute Correlation (MAC) values between true and estimated noise variables highlighted the model’s efficacy in accurately representing causal structures. The algorithm maintained high accuracy in tests with noisy score estimates, validating its robustness against real-world data conditions. These results underscore the model’s capability to isolate causal structures in observational data, verifying the theoretical predictions of the research.
This research marks a significant advancement in causal disentanglement by enabling the identification of causal factors without relying on interventional data. The approach addresses the persistent issue of achieving identifiability in observational data, offering a flexible and efficient method for causal inference. This study opens new possibilities for causal discovery across various domains, enabling more accurate and insightful interpretations in fields where direct interventions are challenging or impossible. By enhancing causal representation learning, the research paves the way for broader machine learning applications in fields that require robust and interpretable data analysis.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live LinkedIn event] ‘One Platform, Multimodal Possibilities,’ where Encord CEO Eric Landau and Head of Product Engineering, Justin Sharps will talk how they are reinventing data development process to help teams build game-changing multimodal AI models, fast‘
The post Achieving Causal Disentanglement from Purely Observational Data without Interventions appeared first on MarkTechPost.
Source: Read MoreÂ